Blog
Datenmanagement im modernen Datenstapel und im Zeitalter der KI: Ein Aufruf zum Handeln

Einführung
Unternehmen aller Größenordnungen interessieren sich zunehmend für Datenmanagement. Aber dieses Interesse entsteht oft aus dem Kampf heraus. Sie ringen mit grundlegenden Fragen: Können wir diesen Daten vertrauen? Was ist die einzige Quelle der Wahrheit? Was bedeuten diese Daten eigentlich? Wie werden diese Metriken berechnet? Warum sind unsere Pipelines und Dashboards ständig defekt?
Ich glaube, dass der Wandel des letzten Jahrzehnts - der Wechsel von ETL zu ELT und von relationalen On-Premise-Datenbanken zum Modern Data Stack - zu einer Vernachlässigung des Datenmanagements geführt hat.
Wir sind sogar noch schlechter geworden, trotz der zunehmenden Komplexität und des wachsenden Datenvolumens.
Und mit dem Aufkommen der KI steht sogar noch mehr auf dem Spiel. Das Motto "Garbage in, garbage out" war noch nie so wichtig wie heute. Das Versprechen der KI hängt von der Qualität, der Vertrauenswürdigkeit und dem Verständnis der zugrunde liegenden Daten ab. Wenn Sie das Datenmanagement jetzt vernachlässigen, ist das so, als würden Sie einen Wolkenkratzer auf einem wackeligen Fundament bauen - es sieht zwar zunächst beeindruckend aus, ist aber letztlich nicht tragfähig.
In diesem Blogbeitrag werden die Folgen dieses Paradigmenwechsels für das Datenmanagement und seine Auswirkungen auf Unternehmen untersucht. Außerdem wird ein Rahmen vorgeschlagen, der dabei helfen soll, die Kontrolle zurückzugewinnen und das Datenmanagement als wichtige Funktion in der modernen Datenlandschaft zu etablieren.
Die alten Zeiten
Vor dem Aufkommen des "modernen Datenstapels" wurde die Landschaft von relationalen Datenbanken beherrscht, die in erster Linie für die Bereitstellung von Kennzahlen und Trends konzipiert waren. Denken Sie an Kundenzahlen, Produktverkäufe und die Entwicklung der Gewinnspanne. Ein zentrales IT-Team war für dieses relationale Datenbankprodukt verantwortlich, das in der Regel von einem Anbieter relationaler Datenbanken bezogen und vor Ort eingesetzt wurde. Dies war das (unternehmensweite) Data Warehouse, die Hauptquelle für Berichte und Dashboarding.
Diese Einrichtung hatte ihre Grenzen. Die Datenbenutzer waren damit konfrontiert:
- Speicherbegrenzungen: Datenteams mussten oft große Mengen an eingehenden Daten aufgrund von Kapazitätsbeschränkungen im Datawarehouse verwerfen.
- Begrenzte Unterstützung von Datentypen: Die fehlende Unterstützung für Bilder, Audio und JSON schränkte die Nutzung neuer Datenquellen und Erkenntnisse stark ein.
- Langsame Innovation: Schwierigkeiten bei der Übernahme neuer Technologien wie Streaming-/Echtzeitdatenquellen oder der Verwendung von APIs.
- Schmerzhafte Upgrades: Die Aktualisierung oder das Upgrade des lokalen Technologie-Stacks war ein mehrwöchiges oder sogar monatelanges Projekt.
Aber dieser Ansatz bot auch erhebliche Vorteile:
- Eindeutig definierte Schemata:Die Zieltabellenwaren gut definiert und strukturiert, basierend auf logischen und physischen Datenmodellen.
- Quelle-Ziel-Zuordnung: Die Zusammenarbeit mit den Ingenieuren des Quellsystems und den Domänenexperten wurde forciert, um die Datennutzung, die Qualitätserwartungen und die Liefertermine zu vereinbaren.
- ETL-Werkzeuge: Tools wie Informatica PowerCenter oder Ab Initio boten Funktionen wie Data Lineage, Datenvalidierung, Geschäftslogikbibliotheken und Datenkatalogisierung.
Um es klar zu sagen: Ich plädiere nicht für eine Rückkehr zur Ära der relationalen Datenbanken. Der Wechsel von ETL zu ELT, von Schema-on-Write zu Schema-on-Read und von On-Premise zu Cloud hat uns eine nie dagewesene Freiheit, Geschwindigkeit und technologische Fortschritte gebracht. Wir haben jedoch Struktur, Übersicht und Kontrolle verloren. Im "Modern Data Stack" fehlt oft die vollständige Datenabfolge, die Datenvalidierung ist nicht vorhanden und die Dokumentation ist oft veraltet. Wir haben auch Praktiken aufgegeben, die für das Datenmanagement unerlässlich sind: Datenmodellierung, Vereinbarungen mit Quellsystemen und eine einheitliche Informationsebene. Stattdessen gibt es für jedes Dashboard individuelle ETL-Jobs, was die Wiederverwendbarkeit und Konsistenz beeinträchtigt.
Dies trägt direkt zu den Problemen bei, mit denen viele Datenteams heute konfrontiert sind: Bedenken hinsichtlich der Vertrauenswürdigkeit der Daten, fehlendes Dateneigentum, ein hoher Aufwand für die Datenverarbeitung und Schwierigkeiten, die Bedeutung und Herkunft der Daten zu verstehen.
Praktiken der Datenverwaltung (wieder)einführen
Es ist an der Zeit, das Datenmanagement für diese neue Datenrealität neu zu definieren.
Um diese Herausforderungen zu meistern, müssen wir Datenmanagement-Praktiken strategisch in unsere aktuelle Arbeitsweise und unsere Technologien einbinden.
Rahmen für die Datenverwaltung
Am besten beginnen Sie mit der Definition Ihres Datenmanagement-Rahmens. Datenmanagement ist ein breites Thema mit Dutzenden von Unterkategorien. Sie sollten die Unterkategorien jedoch auf der Grundlage Ihrer wichtigsten Herausforderungen und der Möglichkeiten, den größten Nutzen zu erzielen, auswählen.
Diese Unterkategorien können organisatorisch (Datenstrategie, Prozesse, Betriebsmodell), technisch (Metadatenspeicher, Datenqualitäts-Engine, Data Lineage, automatisierte Governance-Workflows) oder auf das Wissensmanagement ausgerichtet sein (Erfassung von Wissen, Dokumentation von Output, Erstellung von Datenmodellen).
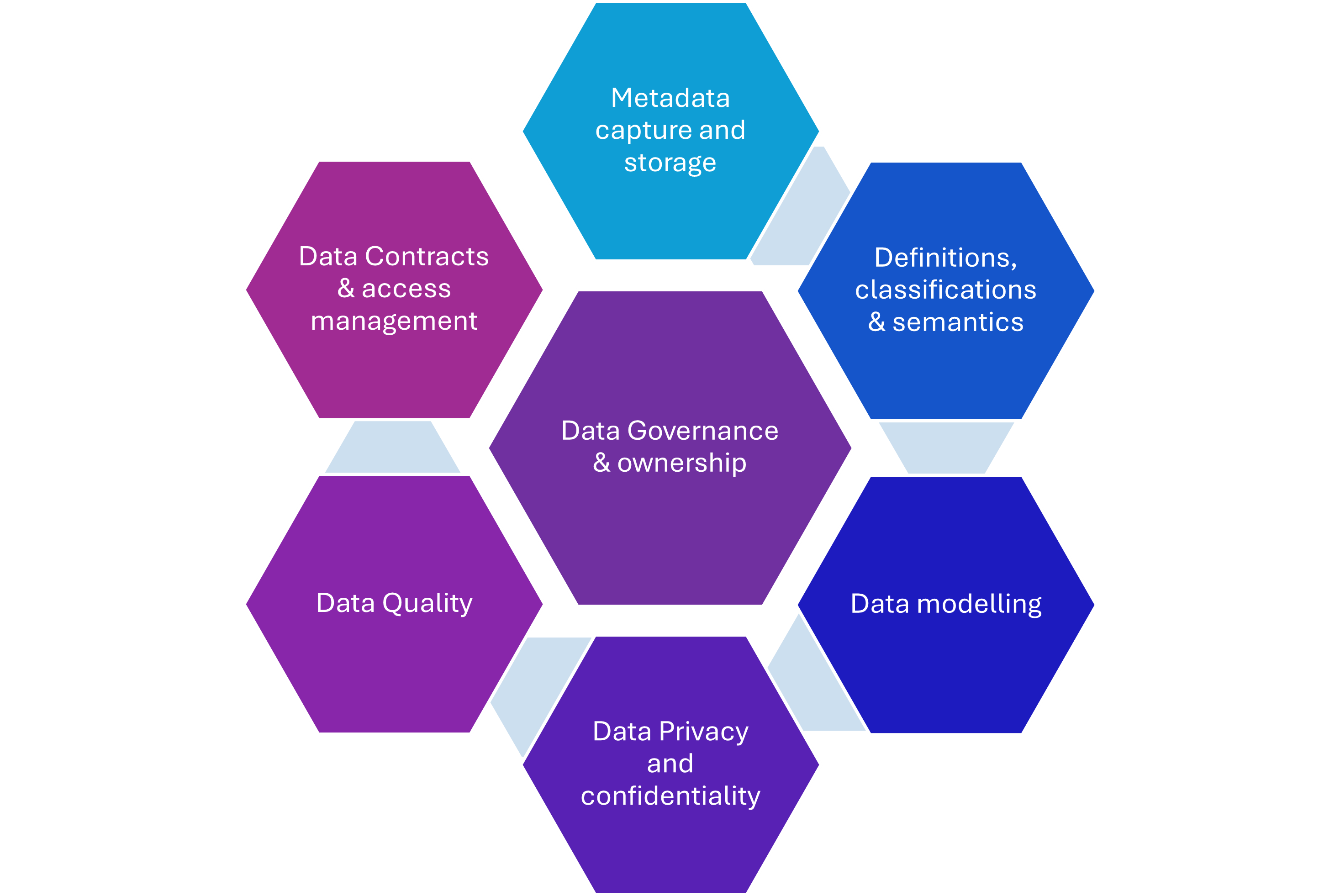
Beispiel für einen DM-Rahmen, die Kategorien sollten zu Ihrer Organisation passen
Nachdem Sie diese Unterkategorien definiert haben, stimmen Sie sich mit Ihren wichtigsten Interessengruppen ab. Seien Sie sich über Ihren beabsichtigten Zweck und Ihre Ziele im Klaren. Themen wie Metadaten, Datenabfolge und Datenqualität sind offen für Interpretationen. Dokumentieren Sie Ihren Rahmen in einem Leitfaden, der im gesamten Unternehmen verteilt werden kann. Dies ist auch eine gute Möglichkeit, neue Teammitglieder einzuarbeiten und ihnen beizubringen, wie sie mit Daten arbeiten sollen. Machen Sie außerdem eine "Road Tour" durch Ihr Unternehmen, bei der Sie das Rahmenwerk vorstellen und erklären, wie es dazu beitragen wird, strategische Ziele zu erreichen und aktuelle Herausforderungen zu bewältigen. Stimmen Sie sich eng mit dem Team ab, das Ihren Datentechnologie-Stack entwickelt und implementiert, da die Komponenten des Frameworks in diesen Stack eingebettet werden müssen.
Straßenkarte
Die Implementierung von Datenmanagement braucht Zeit. Ihre Teams sind bereits ausgelastet, also setzen Sie Prioritäten, welche Rahmenkategorien Sie zuerst angehen wollen. Erstellen Sie eine Roadmap und beginnen Sie mit dem, was für Ihr Unternehmen am wichtigsten ist.
Ziehen Sie außerdem einen anwendungsfallorientierten Ansatz in Betracht. Finden Sie die Anwendungsfälle, die für Ihr Unternehmen von strategischer Bedeutung sind, überzeugen Sie die Sponsoren und die wichtigsten Interessengruppen dieses Anwendungsfalls davon, angemessene Datenverwaltungspraktiken einzuführen, und arbeiten Sie mit dem Bereitstellungsteam zusammen, um den Anwendungsfall zu einem Erfolg zu machen. So schaffen Sie die nötige Akzeptanz und zeigen den Wert, den Sie brauchen, um die Bemühungen auf eine breitere Basis zu stellen.
Ich glaube, dass einige Bereiche am wichtigsten sind, um damit zu beginnen:
- Metadaten: Metadaten sind die Grundlage der Datenverwaltung. Erfassen Sie Metadaten für alle Daten. Semantische Metadaten enthalten Definitionen und Erklärungen. Sicherheits-Metadaten klassifizieren Daten und weisen auf ihre Sensibilität hin. Berücksichtigen Sie Dateneigentum und Nutzungsstatistiken. Dies ermöglicht einen datengesteuerten Ansatz für das Datenmanagement. Speziell für KI sind umfangreiche und genaue Metadaten entscheidend für die Erklärbarkeit von Modellen, die Erkennung von Verzerrungen und die Gewährleistung einer verantwortungsvollen KI-Entwicklung.
- Organisatorisches Modell: Oft übernehmen zentrale oder dezentrale Datenteams die gesamte Verantwortung für die Daten. Sie haben Mühe, den Kontext und die Personen zu finden, die erklären können, wie die Daten erstellt wurden. Außerdem ist es ohne die richtige Verantwortung schwierig, Entscheidungen über Prioritäten und Kapazitätszuweisungen zu treffen. Die Verantwortung für die Datenbestände sollte auf der Unternehmensseite liegen, und zwar bei Personen, die das Mandat haben, Entscheidungen zu treffen, und nicht allein beim Datenteam.
- Daten-Verträge: Ein Datenvertrag ist eine Vereinbarung zwischen Datenproduzenten und -konsumenten. Er reicht von einer einfachen, vorlagenbasierten Vereinbarung bis hin zu einer erzwungenen Nutzungsrichtlinie. Selbst in seiner einfachsten Form erzwingt er Kommunikation und die Kenntnis der Erwartungen. In fortgeschritteneren Formen erhöht er die Datensicherheit und bietet einen Überblick über den Datenzugriff. So wird sichergestellt, dass die Daten den Erwartungen entsprechen.
- Datenportfolio-Management: Datenteams werden oft von Anfragen aus verschiedenen Geschäftsbereichen und Domänen überrannt. Eine einfache Dezentralisierung und die Zuweisung eines Datenteams für jeden Bereich ist kein Allheilmittel, da dies zu Doppelarbeit und Unstimmigkeiten führen kann. Ein gut organisiertes Portfolio von Anwendungsfällen, die nach dem Geschäftswert priorisiert sind, ist entscheidend, um den Fokus zu setzen und die Wirkung zu maximieren. Dadurch wird sichergestellt, dass die Bemühungen auf die Projekte mit der größten Wirkung gelenkt werden und redundante Entwicklungen vermieden werden. Dies sind auch die Projekte, bei denen eine angemessene Datenverwaltung am wirkungsvollsten und wichtigsten ist. Ein gut verwaltetes Datenportfolio stellt sicher, dass KI-Initiativen auf die strategischen Ziele abgestimmt sind, und vermeidet den Fallstrick, KI-Lösungen auf schlecht verwalteten oder doppelten Daten aufzubauen.
Wenn Sie diese Bereiche geordnet haben, können Sie je nach den Herausforderungen und Möglichkeiten Ihres Unternehmens weitere Bereiche einbeziehen. Zum Beispiel:
- Wenn die Datenqualität ein großes Problem darstellt, sollten Sie sich als nächstes damit befassen. Mit Datenqualitätsfunktionen können Sie Daten kontinuierlich überwachen und frühzeitig Warnungen erhalten. Sie schaffen auch Vertrauen, indem Sie die Qualität der Daten für kritische Anwendungsfälle nachweisen.
- Führen Sie Verfahren zur Datenmodellierung ein und konzentrieren Sie sich dabei auf die Dateneinheiten, die für Ihr Geschäftsmodell und Ihren Kontext am wichtigsten sind. Modellieren Sie diese gut und sorgen Sie dafür, dass aus diesen Entitäten wiederverwendbare Datenbestände entstehen.
- Sie könnten auch die Datenabfolge in Betracht ziehen. Viele Tools bieten inzwischen eine Datenabfolge auf Spaltenebene an, die jedoch oft über verschiedene Tools verstreut ist. Wenn Sie die Datenverfolgung über die gesamte Kette hinweg anbieten, können Sie die Herkunft der Daten, die Ursache von Datenproblemen, die Auswirkungen von Änderungen usw. erklären.
- Eine weitere Option sind Referenzdaten, die standardisierte Listen von Werten ermöglichen. Die Verwaltung von Referenzdaten reduziert die Vielfalt und erhöht den Wiedererkennungswert.
Ich könnte noch weitere Bereiche aufzählen, aber die Kernaussage ist, dass Metadaten, Ihr Organisationsmodell (insbesondere Dateneigentum), Datenportfolio-Management und Datenverträge die typischen Ausgangspunkte sind. Erweitern Sie diese Grundlage mit Datenqualität, Referenzdaten oder Datenherkunft.
Und natürlich fragen Sie sich, aber wie setze ich das eigentlich um?
Für viele dieser Aspekte haben wir mit unseren Kunden erfolgreich Lösungen implementiert. In den folgenden Blogs werden wir bestimmte Aspekte der Implementierung und die Tools und Technologien, die wir dafür eingesetzt haben, näher beleuchten.
Fazit
Wir haben diese Untersuchung begonnen, indem wir auf die kritische Lücke in der Struktur und im Wissen hingewiesen haben, die mit dem modernen Datenstapel entstanden ist. Bei diesem Rahmenwerk geht es nicht darum, den Fortschritt, den wir gemacht haben, aufzugeben; es geht darum, ihn zu verbessern. Und jetzt, mit dem allgegenwärtigen Einfluss der KI, geht es nicht nur um bessere Dashboards oder effizientere Pipelines - es geht darum, die verantwortungsvolle und effektive Anwendung von KI sicherzustellen.
Durch die strategische Wiedereinführung von Datenmanagement-Prinzipien können wir das wahre Potenzial unserer modernen Datenstapel erschließen, vertrauenswürdige Erkenntnisse gewinnen, präzise KI-Modelle entwickeln und unsere Unternehmen in die Lage versetzen, datengestützte Entscheidungen zu treffen.
Die Zeit zum Handeln ist jetzt gekommen. Lassen Sie uns die Kontrolle zurückgewinnen, eine stabilere Datenzukunft aufbauen und endlich das Versprechen von datengesteuertem und KI-gestütztem Erfolg einlösen!
Verfasst von
Xebia Author




Contact