Blog
Data Lakehouse mit Snowflake Iceberg Tables - Einführung

Snowflake hat offiziell die Welt der Data Lakehouses betreten! Was ist ein Data Lakehouse, wo würden solche Lösungen perfekt passen und wie könnten sie in das Snowflake-zentrierte Datenökosystem eingeführt werden? Wir werden Ihnen dieses Thema in einer Reihe von Blogbeiträgen näher bringen. Heute finden Sie als Einführung in das Thema Antworten auf Fragen wie: Warum ist ein Data Lakehouse eine Lösung, die alle wichtigen Funktionen eines Data Warehouse und eines Data Lake vereint, und welche Mängel dieser Lösungen behebt es? Welche Rolle spielen offene Datenformate (wie Iceberg) in DLH-Architekturen und was sind Snowflake Iceberg Tables? Im zweiten Teil werden wir die Blueprint-Architektur vorstellen und einige interessante Beobachtungen darüber machen, wie kosteneffizient, flexibel und sicher ein Data Lakehouse auf Snowflake mit dem Iceberg-Format sein könnte. Außerdem gehen wir darauf ein, worauf Sie achten müssen, wenn Sie sich für eine solche Lösung entscheiden. Kommen wir nun zum ersten Teil!
Woher kommen die Daten für ein Lakehouse?
In modernen Datenumgebungen ist es offensichtlich geworden, dass eine Beschränkung auf strukturierte Daten und vordefinierte Schemata nicht mehr ausreicht, wenn Sie den maximalen Wert aus Ihren Datenbeständen ziehen, die damit verbundene Time-to-Value maximieren und die Gesamtbetriebskosten (TCO) optimieren möchten. Traditionell Data Warehousing ist auch sehr oft mit Problemen bei der Handhabung großer Datenmengen oder unterschiedlicher Arbeitslasten verbunden. Daten-Seen ermöglichen dagegen die Speicherung von rohen, unstrukturierten oder halbstrukturierten Daten in ihrem nativen Format. Obwohl sie Flexibilität bei der Dateninterpretation ermöglichen, können sie aufgrund fehlender vordefinierter Strukturen und Leistungsoptimierung für strukturierte Abfragen Herausforderungen bei der Verwaltung und Sicherheit darstellen. Wie so oft in der Natur, wenn keine der Lösungen alle Bedürfnisse abdeckt, taucht schließlich eine neue... dritte Lösung auf.
Data Lakehouses bieten ein Gleichgewicht, das verschiedene Analyseanforderungen mit der Fähigkeit unterstützt, sowohl strukturierte als auch unstrukturierte Daten effizient zu verarbeiten, um erstklassige Unterstützung für maschinelles Lernen und Data Science Workloads zu bieten. Sie kombinieren die Governance-Funktionen von Data Warehouses mit der Flexibilität von Data Lakes, bieten starke Sicherheits- und Zugriffskontrollen und unterstützen gleichzeitig verschiedene Datentypen. Einige der häufigsten Herausforderungen von Data Warehouses wie Datenstalinität, Zuverlässigkeit, Gesamtbetriebskosten, Datenabhängigkeit und begrenzte Unterstützung von Anwendungsfällen werden ebenfalls angegangen. In der Theorie sieht das fantastisch aus, aber... wie wird dieses Konzept aus technischer Sicht eingeführt? 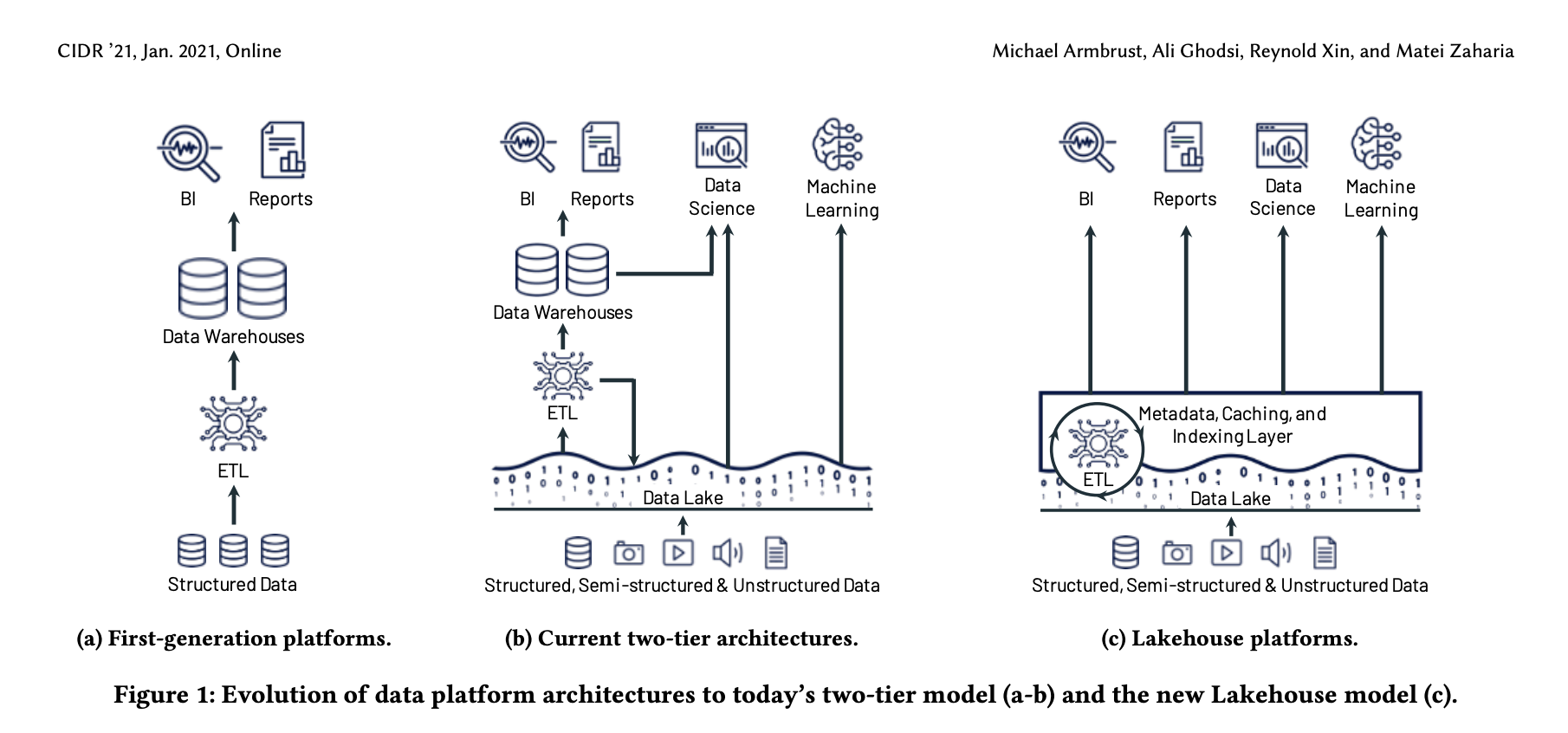
Data Lakehouses und offene Formate
In der Ära von Hadoop und Data Lakes gehörten Transaktionskonsistenz, Schemaentwicklung und Metadatenverwaltung zu den größten Herausforderungen bei der Erstellung von Datenprodukten. Es bestand ein Bedarf an einer Abstraktionsschicht, die diese Mängel beheben würde - so kamen mehr oder weniger offene Tabellenformate ins Spiel. Apache Iceberg ist (neben Delta Lake und Hudi) eines der beliebtesten Formate im Zusammenhang mit Data Lakehouse-Architekturen.
Apache Iceberg als offenes Tabellenformat
Apache Iceberg ist ein Open-Source-Tabellenformat für die Verarbeitung umfangreicher Daten. Es bietet ein Tabellenformat, das Schemaentwicklung, transaktionale Konsistenz und effiziente Datenbereinigung unterstützt. Zu den wichtigsten Merkmalen von Apache Iceberg aus der Sicht der Data Lakehouse-Architektur gehören:
Interoperabilität: Es gewährleistet die Interoperabilität zwischen verschiedenen Datenverarbeitungs-Engines (wie Spark, Trino, Flink, Hive usw.) und Frameworks. So können Benutzer verschiedene Analyse-Tools und -Engines nutzen und gleichzeitig auf dieselben zugrunde liegenden Daten zugreifen, die im Data Lakehouse gespeichert sind.
Schema Evolution: ermöglicht die Entwicklung von Tabellenschemata im Laufe der Zeit, ohne dass der gesamte Datensatz neu geschrieben werden muss. Diese Flexibilität ist in dynamischen Datenumgebungen, in denen Schemaänderungen häufig vorkommen, von entscheidender Bedeutung.
Transaktionale Konsistenz: bietet ACID-Transaktionen (Atomicity, Consistency, Isolation, Durability) für Schreibvorgänge. Dadurch wird sichergestellt, dass Schreibvorgänge entweder vollständig übertragen oder vollständig zurückgenommen werden und die Konsistenz gewahrt bleibt.
Snapshot-Isolierung: unterstützt die Snapshot-Isolierung, die es gleichzeitigen Lesern ermöglicht, auf dieselbe Tabelle zuzugreifen, ohne sich gegenseitig zu stören. Dies ist wichtig, um konsistente Abfrageergebnisse in Umgebungen mit mehreren Benutzern zu erhalten.
Zeitreise: Ermöglicht die Abfrage von Daten zu verschiedenen Zeitpunkten und bietet eine historische Ansicht des Datensatzes. Diese Funktion ist wertvoll für die Prüfung, Fehlersuche und Analyse von Änderungen im Laufe der Zeit.
Metadatenverwaltung: verwaltet Metadaten über die Tabelle, einschließlich Informationen über Schema, Partitionen und Statistiken. Diese Metadaten sind wichtig, um die Abfrageleistung zu optimieren und ein effizientes Bereinigen von Daten während der Abfrageausführung zu ermöglichen.
Optimierte Abfrageleistung: Bietet Optimierungen für die Abfrageleistung, indem es effizientes Data Pruning und Filtern ermöglicht und so die Datenmenge reduziert, die während der Abfrageausführung gescannt werden muss. Dies ist besonders wichtig für große Data Lakehouse-Umgebungen.
Apache Eisberg und Schneeflocke
Snowflake ist in das BYOS-Spiel (Bring Your Own Storage) eingestiegen.
Snowflake Data Cloud unterstützt die Verarbeitung von Big Data-Workloads mit zahlreichen Dateiformaten, darunter Parquet, Avro, ORC, JSON und XML. Während das interne, vollständig verwaltete Tabellenformat von Snowflake die Speicherpflege wie Verschlüsselung, Transaktionskonsistenz, Versionierung, Ausfallsicherheit und Zeitreise vereinfacht, sind einige Organisationen mit gesetzlichen oder anderen Einschränkungen entweder nicht in der Lage, alle ihre Daten in Snowflake zu speichern oder ziehen es vor, Daten extern in offenen Formaten (wie Apache Iceberg) zu speichern. Einer der Hauptgründe, warum einige Organisationen auf die offenen Formate setzen, ist die Interoperabilität - sie können ihre Daten sicher mit Spark, Trino, Flink, Presto, Hive und vielen anderen in denselben Tabellen und zur selben Zeit verarbeiten. Andere ziehen es vor, dass die Speicherkosten über die Rechnung ihres Cloud-Anbieters abgerechnet werden, oder sie bevorzugen einfach offene Formate, weil sie sich nicht einschränken lassen und bei der Wahl ihrer Architektur flexibel sein wollen. Letzten Endes läuft es immer auf das beliebte Dilemma hinaus - verwaltete oder flexible Lösungen. Unabhängig von den Gründen sollten sich die Fans offener Tabellenformate freuen, denn Snowflake hat vor kurzem die Unterstützung für Iceberg-Tabellen angekündigt.
Iceberg-Tabellen speichern ihre Daten und Metadaten in einem externen Cloud-Speicher (Amazon S3, Google Cloud Storage oder Azure Storage), der nicht Teil des Snowflake-Speichers ist und für den keine Snowflake-Speicherkosten anfallen. Ein solcher externer Speicher könnte in einigen Unternehmen aufgrund von Compliance- und Datensicherheitsbeschränkungen relevant sein. Das bedeutet jedoch, dass die gesamte Verwaltung (einschließlich der Datensicherheitsaspekte) dieses Speichers bei Ihnen liegt (oder zumindest nicht bei Snowflake). Snowflake stellt über ein externes Volume eine Verbindung zu Ihrem Speicherort her. Die Daten befinden sich also außerhalb von Snowflake, aber Sie behalten die Leistung und andere Vorteile von Snowflake (z. B. Sicherheit, Governance, gemeinsame Nutzung).
Snowflake unterstützt verschiedene Katalogoptionen - Sie können Snowflake als Iceberg-Katalog verwenden, aber auch eine Katalogintegration nutzen, um Snowflake mit einem externen Iceberg-Katalog wie AWS Glue oder mit Iceberg-Metadaten-Dateien im Objektspeicher zu verbinden. Eine Iceberg-Tabelle, die Snowflake als Iceberg-Katalog verwendet, bietet volle Snowflake-Plattformunterstützung mit Lese- und Schreibzugriff. Snowflake kümmert sich um die gesamte Lebenszykluswartung, wie z.B. die Verdichtung der Tabelle.
Als Faustregel gilt: Verwenden Sie Snowflake Managed Iceberg, wenn die Daten in einem offenen Format vorliegen müssen, das von externen Prozessen konsumiert werden kann und bei dem Snowflake die Tabelle (und den Katalog) verwaltet, und Snowflake Unmanaged Iceberg, wenn Snowflake Iceberg-Daten im offenen Format lesen muss, aber nur ein Konsument ist und auf einen externen Katalog verweist (z.B. AWS Glue Data Catalog).
Mit der Einführung von Iceberg-Tabellen sind Snowflake-Datenarchitekturen flexibler und offener für neue Arten von Unternehmen geworden. Besonders gut gefällt uns die Verpflichtung, Datenbewegungen zu vermeiden und sicherzustellen, dass die Daten an Ort und Stelle bleiben, was sich positiv auf die Verringerung der Latenzzeit und die Optimierung der gesamten Abfrageleistung auswirkt.
Bitte beachten Sie, dass sich Snowflake Iceberg Tables zum Zeitpunkt der Erstellung dieses Dokuments in der öffentlichen Vorschau befand, was bedeutet, dass es einige Einschränkungen und Haftungsausschlüsse für die potenzielle Nutzung gab. Bitte prüfen Sie die Details hier.
Also... wann sollten Sie Iceberg mit Snowflake verwenden?
Wenn man die Funktionalitäten des Iceberg-Formats und seine Integration in Snowflake kennt, stellt sich natürlich die Frage: Was sind die häufigsten Anwendungsfälle für das Iceberg-Format in Snowflake? Schauen wir uns die Szenarien an, die wir für besonders geeignet halten:
- Sie haben bereits große Datensätze in Ihrem Data Lake im Iceberg-Format, die Sie mit Snowflake abfragen möchten, und zwar mit einer ähnlichen Leistung wie bei Tabellen im nativen Snowflake-Format, ohne die Daten einlesen zu müssen
- Sie möchten, dass Snowflake Ihre Datensätze verwaltet und Sie möchten sie mit Snowflake abfragen, aber Sie müssen dieselben Tabellen auch direkt mit anderen Abfrage-Engines wie Spark, Trino, Redshift usw. abfragen, ohne dass Sie die Daten durch Snowflake leiten müssen
- Sie möchten auf große Datenmengen zugreifen, um anspruchsvolle ML/AI-Trainingspipelines zu betreiben, bei denen eine standardmäßige JDBC/ODBC-Schnittstelle einen Engpass darstellen könnte, und andererseits möchten Sie, dass dieselben Datensätze von Berichtstools abgefragt werden können.
Wie bereits erwähnt - größere Flexibilität bedeutet eine größere Verantwortung für die Sicherung Ihrer Daten über IAM-Regeln, da die Daten in Ihrem Speicher abgelegt werden und direkt abgerufen werden können, ohne Snowflake zu durchlaufen. Wenn Sie Ihre Daten also in erster Linie nur für Business Intelligence verwenden, haben Sie wahrscheinlich keinen Bedarf an einem offenen Format wie Iceberg. Wenn Sie jedoch auf viele verschiedene Arten und mit verschiedenen Tools auf Ihre Daten zugreifen möchten, dann kann die Option des offenen Standards vorteilhafter sein.
Unser Data Lakehouse auf Snowflake
OK, das war ein nettes Update aus der Praxis. Aber... ist das alles, was wir vorbereitet haben? Nein, natürlich nicht! Als eine Gruppe von Fachingenieuren schreiben wir nicht nur IT-Romane - wir bauen auch gerne etwas. Das war auch bei Data Lakehouse auf Snowflake mit dem Iceberg-Format der Fall. Im zweiten Teil unseres Blogbeitrags stellen wir Ihnen unsere Blueprint-Architektur vor und verraten Ihnen einige interessante Beobachtungen darüber, wie kosteneffizient, flexibel und sicher diese Art von Lösung sein könnte. Bleiben Sie dran!
Inspirationen:
Snowflake Iceberg Tables - Leistungsstarke Analysen im offenen Tabellenformat Apache Iceberg oder Snowflake Tabellenformat? | von James Malone Eisberg-Tabellen auf Snowflake: Designüberlegungen und das Leben einer INSERT-Abfrage | Medium Wann man Iceberg-Tabellen in Snowflake verwenden sollte | von Mike Taveirne Eisberg-Tabellen | Snowflake Dokumentation
Verfasst von
Michał Rudko
Unsere Ideen
Weitere Blogs




Contact