Blog
Datenanreicherung in Flink SQL mit dem HTTP Connector für Flink - Teil Zwei

Im ersten Teil dieser Blogpost-Serie haben wir einen geschäftlichen Anwendungsfall vorgestellt, der uns dazu inspiriert hat, einen HTTP-Konnektor für Flink SQL zu erstellen.
Der Anwendungsfall lautete:
Als Datenanalyst möchte ich eingehende Daten mit einem Modell für maschinelles Lernen zur weiteren Verarbeitung anreichern.
Die Daten des Machine Learning-Modells werden über die HTTP/GET-Methode durch ein externes Webservice-System bereitgestellt.
Die Logik sollte mit SQL ausgedrückt werden.
Ob es sich um einen Kartenzahlungsstrom, einen Aktientransaktionsstrom oder einen Klickstrom aus einem Online-Kreditantragsformular handelt, fast immer ist eine Anreicherung erforderlich, um einen größeren Kontext für die nachgelagerte Verarbeitung zu schaffen. Dieser Anreicherungsschritt beinhaltet in der Regel das Abrufen von Daten aus einem externen System. Sehr oft ist der Zugriff auf diese Daten nur über eine REST-API möglich.
Unser HTTP-Konnektor ermöglicht uns die Verwendung der bekannten SQL JOIN-Abfrage, ohne dass wir eine benutzerdefinierte Funktion aufrufen müssen.
Die SQL-Abfrage für diesen Anwendungsfall lautet:
SELECT o.id, o.id2, c.msg, ml.uuid, ml.isActive
FROM Orders AS o
JOIN ML_Data FOR SYSTEM_TIME AS OF o.proc_time AS ml
ON
o.id = ml.id AND o.id2 = ml.id2In diesem Teil möchten wir einige technische Details unseres Connectors besprechen. Zur Erinnerung: Wir haben ihn auf GitHub als Open Source veröffentlicht - GitHub - getindata/flink-http-connector: Http-Konnektor für Flink SQL
Einzelheiten zur Konfiguration des Konnektors, zur Verwendung in Ihrer Pipeline und zur Ausführung eines Beispielprojekts finden Sie in dieser README.md Dokument - GitHub - getindata/flink-http-connector: Http-Konnektor für Flink SQL
Flink Unified Source Schnittstelle - vielleicht beim nächsten Mal
Ursprünglich wollten wir das neue Unified Source Interface von Flink verwenden, das in FLIP-27 vorgeschlagen wurde (FLIP-27: Refactor Source Interface - Apache Flink - Apache Software Foundation ) vorgeschlagen wurde. Diese neue API wurde in Flink 1.12 eingeführt und löst mehrere Probleme, die in der vorherigen API auftraten, wie z.B. "work discovery". Der Begriff "Work Discovery" beschreibt die Logik, die erforderlich ist, um neue Daten in den Stream aufzunehmen. Das kann zum Beispiel eine Kafka-Topic- oder Partitionserkennung während der Laufzeit sein. Es kann sich auch um eine aktive Überwachung eines Quellordners für die Dateiquelle oder eine aktive Abfrage des E-Mail-/Slack-Servers handeln, um festzustellen, ob neue Nachrichten zu verarbeiten sind.
Wir hatten wirklich gehofft, es verwenden zu können, zumal dies jetzt eine empfohlene Methode für die Implementierung benutzerdefinierter Anschlüsse ist. Leider hat sich herausgestellt, dass wir das nicht können.
Im Gegensatz zum JDBC-Konnektor, bei dem es sich um einen direkten Datenbankkonnektor handelt, gibt es bei Webdiensten eher selten einen REST-Endpunkt, der einen ganzen Datensatz zurückgibt, es sei denn, dieser Satz hat eine überschaubare Größe. In diesem Fall ist es jedoch üblich, die Daten in Form von numerierten Seiten zurückzugeben, die dem HATEOAS-Antwortmuster folgen. HATEOAS steht für Hypermedia As The Engine Of Application State ( Hypermedia als Motor des Anwendungsstatus) und wird im Falle der Paginierung durch die Bereitstellung von Links zur vorherigen und nächsten Seite umgesetzt. Diese Links werden der API-Antwort hinzugefügt.
In der Praxis verwendet das gängigste Muster einfach die Filterung mit HTTP GET mit Parametern, z.B. mit einer Art ID, für die die Daten abgerufen werden sollen. In unserem Fall mussten die in SQL JOIN verwendeten Parameter als diese Art von ID verwendet werden. Die Übergabe von Join-Parametern an den Konnektor kann mit Flink's Lookup Joins- Joins durchgeführt werden
Leider hat sich herausgestellt, dass Lookup Join, oder besser gesagt eine Lookup Table Source, nichtmit der FLIP-27 API implementiert werden kann. Der mit einer Unified Source Interface implementierte Source Connector kann nur als Scan Source fungieren , d.h. er scannt zur Laufzeit alle Zeilen aus einem externen Speichersystem. Was wir in unserem Fall brauchten, war eine Lookup Table Source. Ich habe einen E-Mail-Thread zu diesem Thema auf der Flink-Benutzer-Mailingliste(hier) gestartet, in dem diese Einschränkung bestätigt wurde.
Kurz gesagt, da wir eine Lookup-Tabellenquelle für Flink SQL benötigen, können wir unseren Connector nicht mit der Unified Source Interface API implementieren, da diese nur Scan-Quellen unterstützt und Scan-Quellen nicht gut mit REST-APIs zusammenpassen.
Nachschlagefunktion
Detailliertes UML-Diagramm für HTTP-Connector:
Im Kern haben wir zwei Hauptklassen:
HttpTableLookupFunctionAsyncHttpTableLookupFunction
Beide Klassen stellen die Verbindung zwischen Flink Runtime und dem Benutzercode her, der die HTTP-Aufrufe ausführt.
Wie Sie bereits am Klassennamen erkennen können, kann unser Connector asynchron arbeiten.
Beide Klassen müssen, um mit Flink Core kommunizieren zu können, eine Methode public void eval(...) implementieren. Das Überraschende dabei ist, dass es keine Schnittstelle oder abstrakte Klasse gibt, die die Implementierung dieser Methode erzwingen würde. Als Entwickler könnten Sie dies also völlig übersehen.
Wie habe ich es also gefunden?
Nun, zum Glück wird dies in der Javadoc für TableFunction und AsyncTableFunction abstrakte Klassen erwähnt.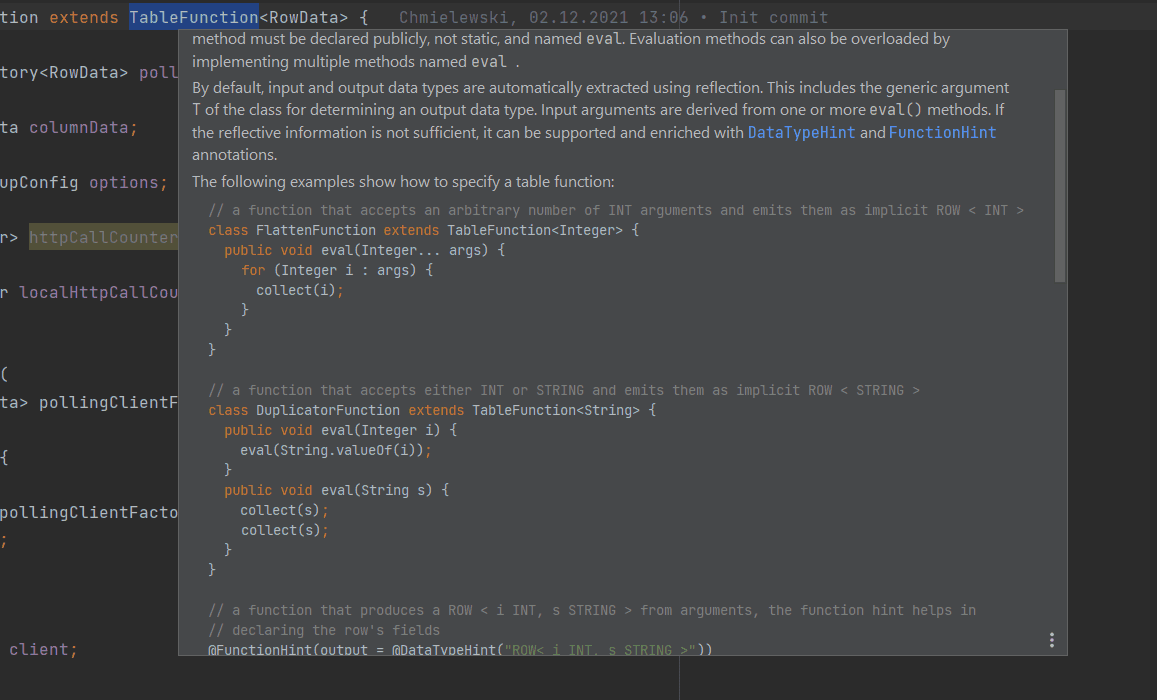
Es sieht so aus, als würde sich das Lesen der Dokumentation am Ende auszahlen :) Sie fragen sich vielleicht, woher Flink "weiß", dass es die Methode evalaufrufen muss, da sie nicht Teil einer Schnittstelle oder einer abstrakten Methode ist. Nun, es scheint, dass es dies einfach annimmt. Die auf Scala basierende TableFunctionCallGen macht genau das:
val functionCallCode =
s"""
|${parameters.map(_.code).mkString("\n")}
|$functionReference.eval(${parameters.map(_.resultTerm).mkString(", ")});
|""".stripMarginMeiner Meinung nach ist es ein wenig überraschend, dass die Implementierung der eval-Methode nicht durch eine Schnittstelle erzwungen wird. Das wäre intuitiver und eigentlich etwas, das die meisten Programmierer erwarten würden.
Registrierung einer neuen Quelle
Um eine neue Quelle als Tabellenquelle zu registrieren, müssen wir eine Fabrikklasse hinzufügen und sie für die Java Service Provider Interfaces registrieren. In unserem Fall ist dies die Klasse HttpLookupTableSourceFactory
Die Fabrikklasse muss die Schnittstelle DynamicTableFactory implementieren. Damit sie von Flink erkannt wird, muss sie zu dieser Datei hinzugefügt werden:
src/main/resources/META-INF/services/org.apache.flink.table.factories.Factory
HttpLookupTableSourceFactory erstellt eine Instanz von DynamicTableSource, die in unserem Fall HttpLookupTableSource ist.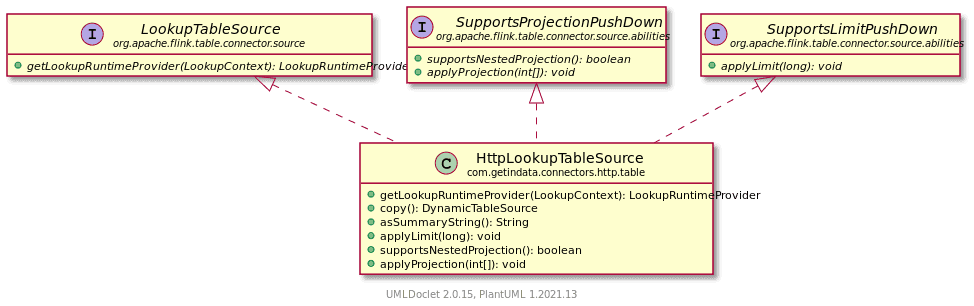
Die Methode getLookupRuntimeProvider wird vom Flink-Kern aufgerufen, um die Implementierung der Lookup-Funktion zu erhalten.
Im Allgemeinen können Sie je nach Bedarf und Anwendungsfall einen von zwei Anbietern wählen,LookupRuntimeProvider oder ScanRuntimeProvider. Die Quellen, die FLIP-27 implementieren, werden nur von ScanRuntimeProvider unterstützt. In unserem Anwendungsfall mussten wir LookupRuntimeProvider verwenden.
Die LookupRuntimeProvider wird durch TableFunctionProviderund AsyncTableFunctionProvider erweitert. Wir verwenden beide, je nach Konfigurationsparameter des Connectors asyncPolling.
HTTP-Kommunikation
Unser http-Connector verwendet den Java 11 HTTP-Client, um HTTP-Anfragen zu senden. Er bietet einen umfassenden Mechanismus für die Kommunikation mit dem HTTP-Server und ist bereits im JDK implementiert, so dass keine zusätzlichen Abhängigkeiten erforderlich sind.
Details zu HttpClient finden Sie hier.
Für die Erstellung des URI-Pfads haben wir uns jedoch für die Klasse URIBuilder aus der 3rd-Party-Bibliothek org.apache.httpcomponents von Apache entschieden (siehe hier).
Wir wollten keine Logik für die Erstellung aller HTTP-URI-Varianten, die Behandlung mehrerer Anfrageparameter usw. programmieren. Die Verwendung dieser Bibliothek hat uns einige Mühe erspart.
Derzeit unterstützen wir nur GET-Methoden und den Antwortcode HTTP 200 OK. Wir hoffen, dass wir diesen Teil in Zukunft verbessern können.
HTTP-Antwortmodell
Wir gehen davon aus, dass die HTTP-Antwort als JSON-Objekt an uns zurückgeschickt wird. Flink unterstützt bereits das JSON-Format für die Definition von SQL-Quellen, wie in JSON. Da sich unser Connector jedoch noch in der Anfangsphase befindet, unterstützen wir vorerst nur String-Spaltentypen. Daher haben wir uns entschlossen, eine Alternative für die Übersetzung von JSON Response in ein Tabellenschema anzubieten. Die Unterstützung für das Flink JSON Format wird in Zukunft hinzugefügt werden.
Der alternative Mapping-Mechanismus, den wir entwickelt haben, basiert auf der com.jayway.jsonpath Bibliothek und der Json Path Notation - JSON Path Syntax im Detail. Aus meiner Erfahrung in der Wirtschaft habe ich festgestellt, dass die Json Path-Notation für Business Analytics recht vertraut sein kann, insbesondere bei der Erstellung von Modellkonvertierungsregeln. In einem meiner früheren Projekte wurden alle Mapping-Regeln vom Rohformat zum gemeinsamen Modell von BAs unter Verwendung der Json Path-Notation erstellt.
Die Konvertierung von Json in RowData wird von der Klasse HttpResultConverter vorgenommen.
Die Klasse HttpResultConverter verwendet die Definition des Connectors, um nach Alias-Definitionen oder der Definition des Stammknotens zu suchen. Wenn keine gefunden werden, wird der Spaltenname direkt in das JSON-Pfadformat umgewandelt.
Für komplexe Strukturen kann der Benutzer Alias-Pfade definieren. Die Alias-Eigenschaft muss dem Muster: field.COLUMN_NAME.path folgen. Eine ähnliche Konvention findet sich auch im DataGen SQL Connector von Flink.
Der Wert für den Alias-Pfadschlüssel ist eine json-Pfadzeichenkette. HttpResultConverter oder jede Spalte überprüft, ob es einen Alias gibt. Wenn dies der Fall ist, wird die entsprechende json-Pfaddefinition verwendet, um den Wert aus der HTTP-Antwort zu erhalten.
Zum Beispiel mit der untenstehenden Tabelle Definition:
CREATE TABLE Customers (
id STRING,
id2 STRING,
msg STRING,
uuid STRING,
isActive STRING,
balance STRING
) WITH (
'connector' = 'rest-lookup',
'url' = 'http://localhost:8080/client',
'field.isActive.path' = '$.details.isActive',
'field.balance.path' = '$.details.nestedDetails.balance'
)Jede Spalte außer isActive und balance wird direkt in einen json-Pfad konvertiert. Zum Beispiel id -> $.id, die verbleibenden zwei Spalten verwenden Alias-Pfade aus der Tabellendefinition, d.h. der Wert für die Spalte isActive wird aus dem Pfad $.details.isActive und der Wert für die Spalte balance wird aus dem Pfad $.details.nestedDetails.balance übernommen.
Asynchrone Unterstützung
Bei der Implementierung der Prozessfunktion, die mit dem externen System über blockierende Aufrufe kommuniziert, wird empfohlen, Flink Async I/O - Async I/O zu verwenden. Dies hilft bei der Verwaltung der Kommunikationsverzögerung mit dem externen System und dominiert nicht die gesamte Arbeit der Streaming-Anwendung. Der Anreicherungsprozess ist ein gutes Beispiel dafür, dass eine solche asynchrone Unterstützung erforderlich ist.
Glücklicherweise wird die Async I/O von Flink auch in Flink SQL unterstützt. Wir müssen einfach nur AsyncTableFunctionProvider von HttpLookupTableSource::getLookupRuntimeProvider zurückgeben.
Die AsyncTableFunctionProvider muss ein Objekt bereitstellen, das die abstrakte Klasse AsyncTableFunction erweitert.
In unserem Fall ist dies die Klasse AsyncHttpTableLookupFunction.
Die abstrakte Klasse AsyncTableFunction ist der Klasse TableFunction sehr ähnlich. Der Hauptunterschied besteht in der Signatur der berühmten Methode eval. Ja, dieselbe evalMethode, von der wir nur "wissen" müssen, dass wir sie überschreiben müssen. Auch hier finden Sie den einzigen Hinweis darauf, dass wir diese Methode implementieren müssen, in der Javadoc von AsyncTableFunction. Auch hier wäre es viel intuitiver, wenn es nur eine abstrakte Methode gäbe, die wir implementieren müssten.
Im Fall von AsyncTableFunction akzeptiert die Signatur der Methode evalJoin Keys und ein CompletableFuture Objekt. Die Signatur sieht wie folgt aus:
public void eval(CompletableFuture<Collection<RowData>> resultFuture, Object... keys)
Unsere Implementierung der eval-Methode basiert auf HBaseAsyncTableFunction. Diese Klasse ist in der Javadoc von AsyncTableFunction als Beispiel aufgeführt.
Die gesamte Implementierung sieht folgendermaßen aus:
public void eval(CompletableFuture<Collection<RowData>> resultFuture, Object... keys) {
CompletableFuture<RowData> future = new CompletableFuture<>();
future.completeAsync(() -> decorate.lookupByKeys(keys), pollingThreadPool);
future.whenCompleteAsync(
(result, throwable) -> {
if (throwable != null) {
log.error("Exception while processing Http Async request", throwable);
resultFuture.completeExceptionally(
new RuntimeException("Exception while processing Http Async request", throwable));
} else {
resultFuture.complete(Collections.singleton(result));
}
},
publishingThreadPool);
}Sie können sehen, dass wir zwei separate Thread-Pools verwendet haben. Einer wird von HttpClientverwendet, um eine HTTP-Anfrage zu stellen, während der zweite für die Veröffentlichung der Ergebnisse nachgelagert über CompletableFuture resultFuture verwendet wird. Die getrennten Thread-Pools helfen uns, ein Aushungern der Threads bei der Veröffentlichung der Ergebnisse zu vermeiden.
Pläne für die Zukunft
Das erste, was wir flink-http-connector hinzufügen möchten, ist die Unterstützung für alle Flink-Datentypen. Das würde die Benutzerfreundlichkeit unseres Connectors sicherlich verbessern.
Als Nächstes sollten wir Unterstützung für das Json-Format von Flink hinzufügen. Das würde gut zu den etablierten Konventionen passen, die die übrigen Konnektoren in Bezug auf eine komplexe Schemadefinition und den Umgang mit Datenformattypen wie Json befolgen. Wir werden unseren auf Json Path basierenden Konverter beibehalten, da er für Benutzer, die es gewohnt sind, mit Json-Objekten zu arbeiten, hilfreich sein kann.
Der letzte Punkt, den Sie hier erwähnen sollten, ist die Implementierung des HTTP-Connectors mit FLIP-27 für Data Stream API. Der Entwurf geht davon aus, dass der Client in der Lage sein wird, seine eigene Logik für die Arbeitsfindung und -aufteilung strikt nach dem Muster der Dependency Injection einzubauen. Dies wird für die SQL-API eine Herausforderung sein, da wir eine statische Fabrik registrieren müssen, auf die keine Dependency Injection angewendet werden kann, zumindest nicht in ihrer derzeitigen Form. Es könnte jedoch eine Möglichkeit geben, dies mit ein wenig Hilfe von Spring Framework zu umgehen. Das mag für einige der Flink-Mitarbeiter sehr seltsam klingen, aber es gibt eine Möglichkeit, Spring Framework als Dependency Injection Framework mit Flink zu verwenden. Dies wird jedoch ein Thema für zukünftige Blogbeiträge sein.
Fazit
In diesem Blogbeitrag möchten wir Ihnen einige technische Details zu unserem http-Connector vorstellen. Wir möchten den Entscheidungsprozess beschreiben, dem wir bei der Entwicklung dieses Connectors gefolgt sind und warum wir uns für diese Art der Implementierung entschieden haben.
Wir wollten Ihnen auch zeigen, was Sie tun müssen, wenn Sie Ihren eigenen SQL-Konnektor implementieren möchten. Wir wollten einige Schritte hervorheben, die bei der Implementierung eines solchen Konnektors von entscheidender Bedeutung sind, wie z.B. die Implementierung der Methode evaloder die Registrierung des Factorings mit Hilfe der Service Provider Interfaces von Java.
Wir hoffen, dass Ihnen die Lektüre dieses Blogbeitrags gefallen hat und dass Sie etwas gefunden haben, das Ihnen bei Ihren zukünftigen Projekten nützlich sein könnte.
Ich wünsche Ihnen einen schönen Tag und viel Spaß!
– --
Haben Sie den ersten Teil des Blogbeitrags verpasst? Lesen Sie Data Enrichment in Flink SQL using HTTP Connector For Flink - Part One und melden Sie sich für unseren Newsletter an, um auf dem Laufenden zu bleiben!
Verfasst von
Krzysztof Chmielewski
Unsere Ideen
Weitere Blogs




Contact