Blog
Chaos Engineering: Warum Sie in der Produktion absichtlich Dinge kaputt machen sollten

Wurden Sie schon einmal aus dem Bett geholt, weil die Anwendung, an der Sie arbeiten, nicht mehr funktionierte? Oder haben Sie an einem Samstag Zeit damit verbracht, manuelle Failover-Tests von einem Rechenzentrum zum anderen durchzuführen? Wenn ja, sind Sie wahrscheinlich begeistert zu erfahren, wie Sie dies vermeiden können. Wenn nicht, haben Sie entweder Glück gehabt, dass es noch nicht passiert ist, oder Sie haben es zum Problem von jemand anderem gemacht.
Messung komplexer IT-Landschaften
Die Anwendungslandschaften haben sich im Laufe der Jahre weiterentwickelt und herkömmliche Überwachungssysteme sind nicht in der Lage zu überprüfen, ob unsere Systeme in Betrieb sind oder nicht. Wie kommt das?
Sehen Sie sich die folgenden Architekturen von großen Unternehmen wie Amazon und Netflix an. Sie stellen alle Instanzen von Microservices dar, die den Webshop von Amazon betreiben (also kein AWS, das ist nur der Online-Shop). Glauben Sie, die haben ein Dashboard, das alle Server und Instanzen anzeigt und grün oder rot ist? Ich sage Ihnen gleich, dass sie es nicht haben.

Microservice-Architekturen und Cloud-Infrastrukturen haben unsere Landschaft stark verändert. Wir haben keine großen Server mehr, die wir wie unsere Haustiere hüten. Stattdessen haben wir eine Menge kleinerer Infrastrukturen, die für bestimmte Teile des Anwendungsworkflows zuständig sind. Oft können diese Teile der Infrastruktur horizontal skaliert werden, indem mehrere Instanzen desselben Dienstes ausgeführt werden.
Was wir überprüfen müssen, ist, ob unsere Anwendung normal funktioniert. Wenn ein Microservice über mehrere Instanzen skaliert wird, bemerken die Benutzer möglicherweise nicht einmal, dass eine von ihnen ausfällt.
Die Frage, ob die Server verfügbar sind oder nicht, ist kein Maßstab mehr. Wir müssen messen, ob die Benutzer noch in der Lage sind, das zu tun, was sie tun sollen. Nehmen Sie zum Beispiel Netflix. Netflix verwendet dafür eine großartige Messung, die "The pulse of Netflix" genannt wird. Damit wird die Anzahl der gedrückten Wiedergabetasten gemessen. Netflix weiß sehr gut, wie viele Streams durchschnittlich gestartet werden. Wenn Streams nicht gestartet werden, drücken die Nutzer immer wieder auf die Wiedergabetaste, um es erneut zu versuchen. Infolgedessen steigt die Anzahl der Klicks. Wenn die Seite mit der Wiedergabetaste nicht einmal geladen wird, sinkt die Anzahl der Klicks auf die Wiedergabetaste. In beiden Fällen wird Netflix über dieses Verhalten (oder Problem) benachrichtigt.
"In einer komplexen Landschaft ist Ihre Anwendung nie ganz ausgereift"
Die Überwachung der Benutzeraktivität und der Erfolgsquote ist bei der Entwicklung von hochverfügbaren Anwendungen von entscheidender Bedeutung. Ohne dies werden Sie nie wissen, ob Ihre Anwendung funktioniert oder nicht. Selbst wenn Sie nur über eine kleine Anzahl von Servern verfügen und alle Überwachungsbildschirme einen grünen Status anzeigen, ist das noch keine Garantie dafür, dass Ihre Benutzer eine gute Erfahrung mit Ihrer Anwendung haben. Eine Voraussetzung für eine verteilte, hochverfügbare Anwendung ist eine angemessene Protokollierung, mit der Sie abfragen können, was die Benutzer erwarten.
Wie testet man auf Fehler?
In der Vergangenheit haben wir den Ausfall der Infrastruktur durch manuelle Failover-Tests getestet. Unternehmen führen oft etwa alle 6 Monate einen vollständigen Failover des Rechenzentrums durch. Meistens werden diese Failover-Tests am Wochenende oder zu anderen Zeiten durchgeführt, wenn die Benutzer am wenigsten davon betroffen sind.
Im Zeitalter des Cloud Computing wirkt das altmodisch. Wir haben keine Rechenzentren mehr und die Infrastruktur wird als Vieh statt als Haustier gehalten. Wenn die Infrastruktur kaputt ist oder nicht richtig funktioniert, stellen Sie einfach eine neue bereit, anstatt sie wieder gesund zu pflegen. Wir denken vielleicht, dass wir unsere Systeme so konzipiert haben, dass sie hochverfügbar sind, sich selbst heilen, automatisch skalieren und ausfallen, aber funktioniert das auch so?
Was ist Chaos Engineering?
Viele Menschen haben schon von dem Begriff "Chaos Engineering" gehört. Aber wenn Sie sie fragen, was sie darunter verstehen, lautet die häufigste Antwort: "Das wahllose Töten von Servern in der Produktion". Das verursacht zwar sicherlich Chaos, aber das ist nicht das, worum es beim Chaos Engineering geht. Dieses falsche Verständnis stammt von einer der ersten Praktiken bei Netflix. Im Jahr 2010, noch bevor der Begriff Chaos Engineering geprägt wurde, wurde Chaos Monkey bei Netflix geboren. Chaos Monkey tat genau das, was die Leute heute vermuten: zufällige Server in zufälligen Abständen killen. Teams nutzten Chaos Monkey, um Anwendungen zu entwickeln, die hochverfügbar sein mussten. Chaos Monkey zu überleben war ein großer Test. Später wurde aus Chaos Monkey und "Failure Injection Testing" (FIT) die neue Praxis, Chaos Engineering. Im Jahr 2014 wurde dieser Name zum ersten Mal für die Praxis der absichtlichen Injektion von Fehlern verwendet, um bessere, hochverfügbare Software zu entwickeln. Heute gibt es eine von der Chaos Community eingerichtete Website, auf der die Prinzipien des Chaos Engineering beschrieben werden. Sie finden sie unter
"Chaos Engineering ist die Disziplin des Experimentierens mit einem verteilten System, um Vertrauen in die Fähigkeit des Systems zu schaffen, turbulenten Bedingungen in der Produktion standzuhalten.
Beim Chaos Engineering geht es darum, kontrollierte Experimente durchzuführen und NICHT darum, Dinge in der Produktion zu zerstören, die zu Ausfallzeiten oder Fehlern für Ihre Endbenutzer führen würden.
Chaos Engineering versus reguläre Tests
Chaos Engineering sollte eine Ergänzung zu all den Tests sein, die Sie bereits durchführen. Sie müssen Vertrauen in die Qualität Ihrer Anwendung haben, um Chaos Engineering als eine zusätzliche Reihe von Experimenten zu verwenden, um die Belastbarkeit Ihrer Anwendung zu beweisen. Diese Art von Tests kann nicht durch Unit-Tests oder Integrationstests simuliert werden.
Aber müssen wir das in der Produktion tun? Das ist ein Missverständnis, das die Leute über Chaos Engineering haben. Obwohl Chaos Engineering oft in der Produktion durchgeführt wird, ist dies wahrscheinlich nicht der richtige Ort für den Anfang. Wenn Sie Ihre ersten Experimente durchführen möchten, können Sie dies je nach Experiment in einer Abnahme- oder Testumgebung tun. Wenn Sie mit der Zeit sicherer werden oder größere Teile Ihrer Anwendungslandschaft testen möchten, ist die Produktion der einzige Ort, an dem Sie dies tun können, da es oft unmöglich ist, eine vollständig verteilte Anwendungslandschaft in einer Test- oder Abnahmeumgebung zu emulieren.
Dies funktioniert gut in Cloud-Umgebungen, wo Sie die Kontrolle über die Infrastruktur haben und es möglich ist, eine Infrastruktur zu schaffen, auf der Ihre Experimente ausgeführt werden, während das Experiment stattfindet. Wenn Sie eine kleine Anzahl von Nutzern oder bestimmte Nutzer (vielleicht Mitarbeiter oder Beta-Tester) auf diese Experimentierinfrastruktur umleiten können, können Sie die Experimente dort durchführen, ohne Ihre gesamte Bevölkerung dem Risiko des Experiments auszusetzen.
Ist Chaos Engineering etwas für mich?
Wer würde nicht gerne den Zusatz "Chaos-Ingenieur" zu seiner Berufsbezeichnung hinzufügen? Aber ist das etwas, das Sie wirklich brauchen? Wenn Sie verteilte Anwendungen entwickeln (und wer tut das heutzutage nicht), die hochverfügbar oder geschäftskritisch sein müssen, ist Chaos Engineering die einzige Möglichkeit, dieses Vertrauen für Ihre Anwendung aufzubauen.
Wie Sie Ihre eigenen Chaos Engineering Experimente durchführen können
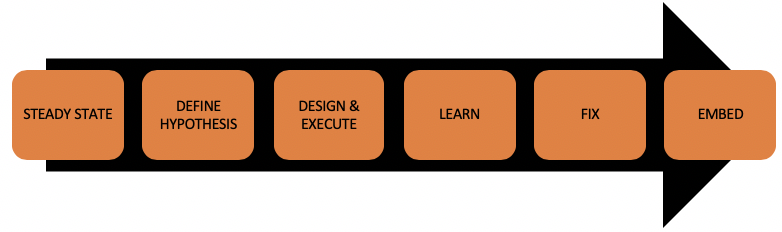
Um zu wissen, wie Sie Ihre eigenen Experimente durchführen können, müssen Sie wissen, was Sie bei diesen Experimenten tun müssen. Alles beginnt damit, dass Sie ein System haben, das sich in einem stabilen Zustand befindet und das genügend Beobachtungsmöglichkeiten bietet, um damit zu experimentieren. Keine Protokolle oder Monitore? Fehlanzeige! Wir können keine Experimente durchführen, ohne zu überwachen, was passiert. Daher ist eine ordnungsgemäße Protokollierung innerhalb der Anwendung eine Grundvoraussetzung.
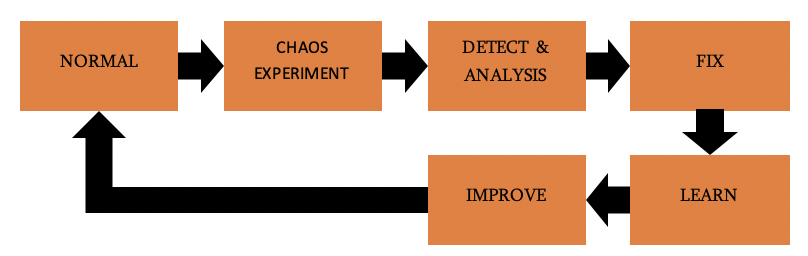
Ein guter Weg, um mit Chaos-Experimenten zu beginnen, ist die Organisation von "Game Days". Dabei handelt es sich um eine zeitlich begrenzte Veranstaltung, bei der Sie alle, die an der Entwicklung und dem Betrieb Ihrer Anwendung beteiligt sind, dazu bringen, sich auf die Widerstandsfähigkeit und das Scheitern zu konzentrieren, indem Sie gemeinsam Experimente durchführen. Der Teil "gemeinsam" ist hier wichtig. Sie sind gemeinsam verantwortlich und wollen vermeiden, dass Sie anderen die Schuld für Dinge geben, die schief laufen. Wenn Sie einen Spieltag organisieren, wird die Bedeutung des Chaos-Engineerings in Ihrer Unternehmenskultur verankert und Sie werden es im Laufe der Zeit gutheißen.
Fester Zustand
Das erste, was wir tun müssen, um ein Chaos-Experiment durchzuführen, ist, einen stabilen Zustand zu definieren. Dies muss ein Indikator für Ihre Anwendung sein, der für Ihre Endbenutzer wie vorgesehen funktionieren sollte. Wie bereits beschrieben, verwendet Netflix hierfür "The pulse of Netflix" und Sie sollten etwas Ähnliches für Ihr Experiment haben. Je nach Art des Experiments und der Anwendung kann dies sehr viel einfacher sein als das, was Netflix verwendet.
Es ist wichtig, eine geschäftliche Metrik statt einer rein technischen Metrik zu messen. Was uns interessiert, ist, ob unsere Benutzer betroffen sind oder nicht, und auf welche Weise sie betroffen sind. Wenn bestimmte Dienste nicht verfügbar sind, kann es zu einem "graceful degradation" kommen. Wir möchten diese Änderungen immer mit Blick auf den Endbenutzer entwickeln und ihm die bestmögliche Erfahrung bieten.
Hypothese
Als Nächstes brauchen Sie eine Hypothese darüber, welchen Misserfolg Ihre Anwendung verkraften sollte und wie das Ergebnis aussehen wird. Der beste Weg, eine Hypothese zu erstellen, ist ein Brainstorming mit allen, die an diesem Teil der Anwendung beteiligt sind. Dies sollte nicht nur das technische Team sein, sondern jeder, der an der Ausführung Ihrer Anwendung beteiligt ist.
Meistens haben die Leute eine Vorstellung davon, was als Teil des Entwurfs passieren "sollte", aber wenn alle anwesend sind - von den Entwicklern, dem Betrieb, dem Netzwerk, der Sicherheit, den Architekten und natürlich dem Product Owner - kann man gut diskutieren, was die Anwendung im Falle eines Ausfalls wirklich tun wird. Gibt es eine "graceful degradation", wird etwas anderes den Betrieb übernehmen, oder wird die Anwendung einfach nicht mehr funktionieren?
Eine gängige Methode, um ein Brainstorming darüber durchzuführen, welche Ausfälle Ihre Anwendung verkraften sollte, ist die Betrachtung des stabilen Zustands und das Aufstellen mehrerer "Was wäre wenn"-Fragen. Was ist, wenn die Datenbank nicht verfügbar ist? Was wäre, wenn sich die Netzwerklatenz um 100 Millisekunden erhöhen würde? Was ist, wenn der Anwendungsknoten neu startet? Jeder kann sich mit seinem Fachwissen einbringen und sich mehrere Szenarien ausdenken, die sich auf Ihren stabilen Zustand auswirken werden.
Wenn Sie sich nicht sicher sind, ob sich der Fehler auf Ihren stabilen Zustand auswirkt, wenn Sie sich nicht einigen können, was passiert, wenn ein Fehler auftritt, oder wenn Sie nicht in der Lage sind, dieses Verhalten zu überwachen, brechen Sie Ihr Experiment hier ab. Es ist an der Zeit, wieder an das Zeichenbrett zu gehen und mehr Informationen darüber zu erhalten, wie Ihre Anwendung auf einen Ausfall reagieren wird, oder mehr Protokollierung und Überwachung einzuführen.
Sie denken vielleicht, dass dies etwas Schlechtes ist, aber eigentlich ist es etwas Gutes. Sie haben etwas über Ihr System gelernt und handeln, bevor etwas Schlimmes passiert. Das macht Ihre Anwendung widerstandsfähiger und bereit für weitere Experimente in der Zukunft.
Entwurf und Durchführung des Experiments
Sobald Sie eine Hypothese aufgestellt haben, ist es an der Zeit, ein Experiment zu entwickeln, um zu testen, ob Ihre Hypothese richtig ist. Bei der Planung des Experiments müssen Sie einige Dinge beachten. Erstens: Fangen Sie so klein wie möglich an, um die Auswirkungen zu minimieren, wenn etwas schief geht. Wenn Sie sich noch nicht so sicher sind oder dies eines Ihrer ersten Experimente ist, könnten Akzeptanzumgebungen ein guter Ausgangspunkt sein, aber meistens wollen Sie das Experiment in der Produktion durchführen, weil dies der einzige Ort ist, der nach erfolgreichen Experimenten wirklich Vertrauen schafft.
Fangen Sie klein an , damit Sie den Explosionsradius minimieren können. Sobald dies gelungen ist, können Sie den Radius der Explosion vergrößern, indem Siemehr Benutzer hinzufügen oder einen größeren Teil Ihrer Landschaft beeinflussen. Beobachten Sie die Situation und haben Sie immer eine Sicherheitsvorkehrung, umdas Experiment abzubrechen.
Eine Cloud-Infrastruktur ist ideal für diese Experimente, da Sie problemlos eine zweite Umgebung einrichten können, in der Sie Ihre Experimente durchführen können, ohne den Rest Ihrer Anwendungslandschaft zu beeinträchtigen.
Lernen Sie
Nachdem Sie das Experiment durchgeführt haben, ist es an der Zeit, die Ergebnisse zu untersuchen und zu sehen, was Sie aus Ihren Beobachtungen lernen können. Dabei ist es wichtig, Ihre Ergebnisse zu quantifizieren. Zum Beispiel: Wie schnell konnten Sie den Fehler auf Ihren Monitoren sehen, nachdem Sie ihn verursacht hatten? Wie schnell konnten Sie sich erholen?
Fix
Nachdem Sie die Ergebnisse quantifiziert haben, wird es einfacher, sie mit Ihren Annahmen oder Zielen zu vergleichen. Wenn die Ergebnisse nicht Ihren Erwartungen entsprechen, können Sie damit beginnen, Ihre Anwendung zu verbessern, damit sie widerstandsfähiger gegen diese Art von Fehlern wird. Nachdem Sie Ihre Verbesserungen vorgenommen haben, führen Sie das Experiment erneut durch, um zu sehen, ob die Verbesserungen ausreichend sind.
einbetten
Wenn Sie mit diesen Chaos-Experimenten vertrauter werden, möchten Sie sie vielleicht noch weiter in Ihrer Entwicklungskultur verankern. Dies kann durch kontinuierliches Chaos geschehen, wie der ursprüngliche Chaos-Affe, der VMs in zufälligen Abständen neu startet. Wenn Sie wissen, dass es diese Experimente gibt und Sie sich für sie entscheiden können, wird dies von Anfang an zu einem wichtigen Thema für die Entwicklungsteams.
Tools für den Einstieg
Chaos Monkey ist das ursprüngliche Chaos-Engineering-Tool, das bei Netflix entwickelt wurde. Es wird immer noch gepflegt und ist derzeit in Spinnaker integriert, dem CICD-Tool von Netflix. github.com/Netflix/chaosmonkey
Gremlin ist ein Unternehmen, das von einigen der Chaos-Ingenieure von Netflix und Amazon gegründet wurde, die Chaos as a Service (CaaS) entwickelt haben. Gremlin ist ein kostenpflichtiger Dienst, der Ihnen ein CLI, einen Agenten und eine Website zur Verfügung stellt, mit denen Sie Chaos-Experimente einrichten können. Gremlin kündigte vor einem Monat einen kostenlosen Service an, der kostenlose grundlegende Chaos-Experimente wie das Ausschalten von Rechnern oder die Simulation einer hohen CPU-Last bietet. gremlin.de
Chaos Toolkit ist eine Open-Source-Initiative, die versucht, Chaos-Experimente zu vereinfachen, indem sie eine offene API und ein Standard-JSON-Format für die Darstellung von Experimenten schafft. Sie haben mehrere Treiber, um diese Experimente auf AWS, Azure, Kubernetes, PCF und Google Cloud auszuführen. Sie bieten auch Integrationen mit Überwachungssystemen und Chats wie Prometheus und Slack github.com/chaostoolkit/chaostoolkit
Fazit
Die Ausfallsicherheit von Anwendungen ist nicht mehr nur für den Betrieb relevant. Mit der Cloud-Infrastruktur sind Entwickler und Ingenieurteams für ihre kompletten Anwendungen verantwortlich geworden, sowohl auf der Anwendungsebene als auch auf der Infrastrukturebene. Die Cloud-Infrastruktur hat uns die Flexibilität und die Agilität gegeben, uns schnell an neue Geschäftsanforderungen anzupassen, aber ohne darauf zu achten, dass Sie vollständig von der Ausfallsicherheit der Cloud-Infrastruktur selbst abhängig sind. Sie müssen eine Architektur schaffen, die mit diesen Komponenten belastbar ist, und der einzige Weg, um herauszufinden, ob sie so belastbar ist, wie Sie gehofft haben, sind kontrollierte Chaos-Experimente. Fangen Sie also selbst an zu experimentieren, indem Sie einen Spieltag in Ihrem eigenen Unternehmen veranstalten! Haben Sie immer noch ein wenig Angst, den Sprung zu wagen? Lassen Sie mich mit diesem großartigen Zitat von Nora Jones, Senior Chaos Engineer bei Slack und Mitautorin des Buches Chaos Engineering von O'Reilly, schließen
"Chaos Engineering verursacht keine Probleme, es deckt sie nur auf" - Nora Jones, Chaos Engineering Lead Slack
Verfasst von
Vivian Andringa
Contact