Blog
Datenerfassung durch JDBC mit FlinkSQL ändern

Heutzutage sind Big Data und Business Intelligence-Plattformen einer der am schnellsten wachsenden Bereiche der Informatik. Unternehmen wollen Wissen aus ihren Daten gewinnen und diese in Echtzeit analysieren, um datengesteuerte Geschäftsentscheidungen zu treffen. Bei GetInData kämpfen wir mit diesen Herausforderungen, um die Daten unserer Kunden zu bändigen und erstklassige Lösungen anzubieten, um in Echtzeit Wissen aus Daten zu gewinnen.
Complex Event Processing (CEP) ist ein innovativer Ansatz, der neue Möglichkeiten für Unternehmen eröffnet, die Ereignisse im gesamten Unternehmen überwachen und analysieren und darauf reagieren möchten. Heute möchte ich unsere Erfahrungen mit CEP teilen, indem ich einen neuen Flink-Konnektor vorstelle, den GetInData entwickelt hat. In dem Beispiel werden wir einen einfachen Flink-Job erstellen, der Änderungen aus einer SQL-Datenbank erfassen und die Mustererkennung auf Datenströmen aus vielen Quellen mit FlinkSQL ausführen kann.
Bevor wir beginnen, werde ich einige Begriffe definieren, die in diesem Artikel verwendet werden.
Übersicht
Flink und FlinkSQL
Flink ist ein Open-Source-Framework zur Bekämpfung des Themas der komplexen Ereignisverarbeitung. Es unterstützt die Stream-Verarbeitung mit niedriger Latenz in großem Maßstab. Außerdem ist FlinkSQL eine von Flink bereitgestellte Sprache, mit der Sie komplexe Datenpipelines schreiben können, ohne eine einzige Zeile Java- oder Scala-Code zu verwenden. Wenn Sie SQL kennen, können Sie FlinkSQL erlernen und Ihre Pipelines schnell erstellen. Flink bietet "Konnektoren" und "Senken", die es uns ermöglichen, Daten aus externen Systemen wie Kafka, ElasticSearch oder PostgreSQL als Tabelle zu behandeln, die FlinkSQL verarbeiten kann.
Komplexe Ereignisverarbeitung (CEP)
Der Begriff "komplexe Ereignisverarbeitung" definiert Methoden zur Analyse von Musterbeziehungen zwischen gestreamten Ereignissen. Wenn dies in Echtzeit geschieht, kann es einen erweiterten Einblick in das Datenverarbeitungssystem geben.
Datenerfassung ändern (CDC)
CDC ist eine Methode, um zu erkennen, wann sich Daten in einem Quellsystem geändert haben und diese Änderungen zur weiteren Verarbeitung zu erfassen. Sie können CDC zum Beispiel verwenden, um Datenänderungen in Ihrer SQL-Datenbank zu erfassen und einen Strom von Ereignissen zu erzeugen, die Datenänderungen beschreiben. Der Stream besteht aus einer Abfolge von Ereignissen, die Einfüge-, Aktualisierungs- und Löschvorgänge an Datenbankzeilen beschreiben. Darüber hinaus kann der CDC-Stream von Flink verarbeitet werden, was uns die Ausführung komplexer Analyseaufträge wie komplexe Ereignisverarbeitung oder Mustererkennung ermöglicht.
Anwendungsfall
Ich glaube, der einfachste Weg, einen Ansatz zu verstehen, ist, ihn in Aktion zu zeigen. Daher habe ich einen einfachen Anwendungsfall erstellt, der von den realen Geschäftsanforderungen eines Produktverantwortlichen für eine mobile Bankanwendung inspiriert wurde.
Beginnen wir mit einer User Story:
Als Business Analyst möchte ich die Effektivität der Marketing-Kampagne zur Werbung für Schnellkredite über die mobile Anwendung überprüfen.
Ich möchte eine Übersicht über die Benutzer haben, die:
- eine Transaktion über den Betrag > 1000 durchgeführt hat
- die mobile Anwendung innerhalb von 3 Tagen nach der Transaktion genutzt haben
- keinen Kredit aufgenommen hat
- die mobile Anwendung innerhalb von 7 Tagen nach der letzten Nutzung erneut verwendet haben
Daten werden in vielen Quellen gespeichert:
- Kafka hat Themen mit Transaktionen und Ereignissen aus mobilen Anwendungen
- PostgreSQL enthält Informationen über Benutzerdarlehen
Die Ansicht muss nahezu in Echtzeit aktualisiert werden.
Wir werden Flink und die Mustererkennung von FlinkSQL verwenden, um eine Lösung zu erstellen, die den Geschäftsanforderungen gerecht wird. Flink bietet einen Connector zu Kafka, der ein Topic als Tabelle in FlinkSQL behandelt. Damit können wir Informationen über Transaktionen und Ereignisse in mobilen Anwendungen verarbeiten, aber die Erfassung von Änderungen aus der DB ist ein schwierigeres Problem. Wir müssen Datenänderungen aus den SQL-Datenbanken in einen Strom von Ereignissen umwandeln. Es gibt mehrere Tools auf dem Markt, die uns bei dem CDC-Problem helfen können, also lassen Sie uns einen Blick auf sie werfen.
Debezium
Dies ist eines der beliebtesten Open-Source CDC-Tools, das von Red Hat gepflegt wird. Debezium erfasst Datenänderungen aus DB-Transaktionsprotokollen und veröffentlicht entsprechende Ereignisse auf Kafka.
Vorteile:
- hat keinen Einfluss auf die DB-Leistung
- Daten in Echtzeit erfassen
- kann Löschungen erfassen
- verpasst kein Ereignis (es wird jede Änderung in der Tabelle erfasst)
Nachteile:
- schwierige Einrichtung - es erfordert die Verwendung von Kafka
- benötigt Zugriff auf eine Datenbank binlog
- unterstützt nur wenige Datenbanken
- einige alte Versionen von Datenbanken unterstützen CDC nicht
Ververica Flink CDC Verbinder
Ververica bietet flink-cdc-connectors, die einfach mit Flink verwendet werden können, um Datenänderungen zu erfassen. Außerdem hat der Konnektor Debezium als CDC-Engine integriert, so dass es keinen zusätzlichen Aufwand erfordert, einen vollständigen Debezium-Stack einzurichten.
Vorteile:
- Funktionen von Debezium, aber ohne eine "vollständige Umgebung" einzurichten.
Nachteile:
- unterstützt nur MySQL (5.7, 8.0.x), PostgreSQL (9.6, 10, 11, 12) und MongoDB (4.0, 4.2, 5.0)
- benötigt Zugriff auf eine Datenbank binlog
- einige alte Versionen von Datenbanken unterstützen CDC nicht
Flink Connector JDBC
Connector, mit dem wir Daten aus SQL-Datenbanken direkt in FlinkSQL schreiben und lesen können. Er ist einer der offiziellen Konnektoren, die von Apache Flink gepflegt werden.
Vorteile:
- ermöglicht es uns, Ergebnisse in SQL-Datenbanken zu schreiben
- eingebaut in Flink, Sie müssen nichts hinzufügen
Nachteile:
- liest Daten aus einer Tabelle nur einmal - der Connector bietet keine CDC
- unterstützt nur wenige DBs (MySQL, PostgreSQL, Derby)
GetInData CDC von JDBC Connector
Von GetInData entwickelter Konnektor für CDC-Zwecke. Der Connector ermöglicht es uns, Daten aus SQL-Datenbanken zu lesen, indem er in regelmäßigen Abständen Daten aus Tabellen ausliest.
Vorteile:
- benötigt keine zusätzlichen Komponenten, wie Debezium es tut.
- kann problemlos mit jeder beliebigen Datenbank wiederverwendet werden. Stellen Sie einfach SQL-Abfragen für die CDC und den JDBC-Treiber bereit.
- verwendet reines SQL für CDC, so dass die spezielle Konfiguration einer Datenbank nicht erforderlich ist.
Nachteile:
- unterstützt keine Löschvorgänge.
- einige CDC-Strategien erfordern zusätzliche Spalten, z.B. last_modify_date.
- kann sich auf eine Datenbank auswirken, da es Daten durch eine periodisch ausgeführte SQL-Abfrage liest.
- aktualisiert die Daten nahezu in Echtzeit. Die CDC-Logik wird in bestimmten Intervallen ausgeführt.
- kann ein CDC-Ereignis in häufig wechselnden Zeilen (Einfügen und Löschen einer Zeile, bevor der Connector die Daten aktualisiert) auslassen.
Übersicht über benutzerdefinierte Anschlüsse
Wir haben die von Flink bereitgestellte Tabellen-API verwendet, um unseren CDC-Konnektor zu entwickeln. Flink bietet Schnittstellen, die durch eine benutzerspezifische Logik implementiert werden müssen, um externe Datenquellen wie eine Tabelle zu behandeln. Anschließend kann die Tabelle mit FlinkSQL verarbeitet werden. Flink verändert keine externen Daten, während eine Abfrage ausgeführt wird. Stattdessen verwendet die Flink-Ausführungsengine eine in einer CatalogTable gespeicherte Tabellendefinition, um während der Ausführung der Abfrage alle Daten aus der Quelle zu lesen.
Weitere Details zum Schreiben von benutzerdefinierten Konnektoren finden Sie in der Flink-Dokumentation.
Beispiel
In diesem Beispiel möchte ich Ihnen zeigen, wie Sie GetInData CDC by JDBC Connector mit Mustererkennung in FlinkSQL verwenden können, was den Geschäftsanforderungen unserer User Story entspricht.
Bevor wir mit der Erstellung von Flink-Aufträgen beginnen, möchte ich das in diesem Beispiel verwendete Datenmodell definieren.
Zu Kafka werden wir die folgenden Themen behandeln:
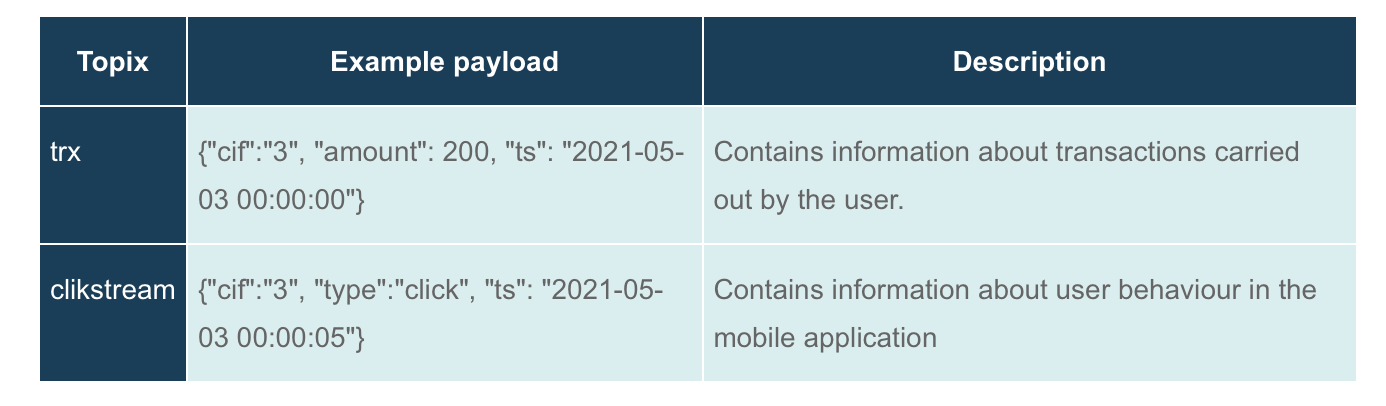
In PostgreSQL werden wir Tabellen haben:

Enthält Informationen über die vom Benutzer aufgenommenen Kredite
In diesem Beispiel möchte ich unsere Umgebung mit Hilfe von docker-compose einrichten. Das Skript wird einen Flink-Cluster, Kafka und Postgres in Docker-Containern einrichten.
version: "3"
services:
jobmanager:
image: flink:1.13.2-scala_2.12-java11
hostname: jobmanager
expose:
- "6123"
ports:
- "8081:8081"
command: jobmanager
environment:
JOB_MANAGER_RPC_ADDRESS: "jobmanager"
networks:
- flink_jdbc_connector
taskmanager:
image: flink:1.13.2-scala_2.12-java11
expose:
- "6121"
- "6122"
depends_on:
- jobmanager
command: taskmanager
links:
- jobmanager:jobmanager
environment:
JOB_MANAGER_RPC_ADDRESS: "jobmanager"
networks:
- flink_jdbc_connector
postgres:
image: postgres
environment:
POSTGRES_PASSWORD: example
volumes:
- ./init.sql:/docker-entrypoint-initdb.d/init.sql
ports:
- "5432:5432"
networks:
- flink_jdbc_connector
kafka:
image: wurstmeister/kafka:2.12-2.4.0
ports:
- "9092:9092"
depends_on:
- zookeeper
environment:
HOSTNAME_COMMAND: "route -n | awk '/UG[ \t]/{print $$2}'"
KAFKA_ADVERTISED_HOST_NAME: kafka
KAFKA_AUTO_CREATE_TOPICS_ENABLE: 'true'
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
volumes:
- /var/run/docker.sock:/var/run/docker.sock
networks:
- flink_jdbc_connector
networks:
flink_jdbc_connector:
driver: bridgeEs könnte eine Herausforderung sein, eine komplette Umgebung mit einer mobilen Beispielanwendung einzurichten. Daher habe ich ein kleines Python-Skript vorbereitet, mit dem wir das Benutzerverhalten simulieren können. Das Skript simuliert zwei Szenarien - den glücklichen Pfad, der der Benutzergeschichte entspricht, und den unglücklichen Pfad, der nicht der Mustererkennungsanfrage entsprechen sollte.
import json
import time
from kafka import KafkaProducer
from datetime import datetime, timezone
from sqlalchemy import create_engine
from sqlalchemy.sql import text
kafka_server = "local-dev_kafka_1:9092"
producer = KafkaProducer(bootstrap_servers=kafka_server)
def send_to_kafka(topic: str, record: bytes):
producer.send(topic, record)
producer.flush()
def generate_clickstream_record(cif: str, eventType: str, ts: datetime):
payload = {'cif': cif, 'type': eventType, 'ts': ts.replace(tzinfo=timezone.utc).strftime("%Y-%m-%d %H:%M:%S.%f")}
send_to_kafka('clickstream', json.dumps(payload).encode('utf-8'))
def generate_trx_record(cif: str, amountPLN: float, ts: datetime):
payload = {'cif': cif, 'amount': amountPLN, 'ts': ts.replace(tzinfo=timezone.utc).strftime("%Y-%m-%d %H:%M:%S.%f")}
send_to_kafka('trx', json.dumps(payload).encode('utf-8'))
engine = create_engine('postgresql+pg8000://postgres:example@postgres:5432/postgres')
con = engine.connect()
def generate_loan(cif: str, day: datetime):
stmt_loan = text("""
INSERT INTO V_LOAN
VALUES (default, :cif, :account, :day)
""")
data = {'cif': cif, 'account': cif, 'day': day}
con.execute(stmt_loan, **data)
def generate_scenario_happy_path(cif: str):
generate_trx_record(cif, 2000, datetime(2021, 4, 1, 0, 0, 0))
generate_clickstream_record(cif, 'click', datetime(2021, 4, 2, 12, 0, 0))
generate_clickstream_record(cif, 'click', datetime(2021, 4, 4, 12, 0, 0))
generate_scenario_happy_path("happy")
def generate_scenario_not_happy_path(cif: str):
generate_trx_record(cif, 400, datetime(2021, 4, 1, 0, 0, 0))
generate_clickstream_record(cif, 'click', datetime(2021, 5, 2, 12, 0, 0))
generate_scenario_not_happy_path("nothapp")Das erste, was wir tun müssen, bevor wir eine Pipeline zur Mustererkennung aufbauen, ist die Definition von Datenquellen in FlinkSQL. Um eine Verbindung zu Datenquellen herzustellen, verwenden wir Konnektoren. Konnektoren ermöglichen es uns, in PostgreSQL und Kafka gespeicherte Daten als Tabellen zu behandeln.
CREATE TABLE v_loan
(
id INT,
customer_id VARCHAR,
account_id VARCHAR,
decision_dttm AS PROCTIME(),
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc-cdc',
'url' = 'jdbc:postgresql://local-dev_postgres_1:5432/postgres',
'table-name' = 'v_loan',
'username' = 'postgres',
'password' = 'example',
'cdc.strategy' = 'SIMPLE',
'cdc.simple-strategy.ordering-columns' = 'id'
);
CREATE TABLE trx (
cif STRING,
amount DOUBLE,
ts AS PROCTIME()
) WITH (
'connector' = 'kafka',
'topic' = 'trx',
'properties.bootstrap.servers' = 'local-dev_kafka_1:9092',
'scan.startup.mode' = 'earliest-offset',
'format' = 'json'
);
CREATE TABLE clickstream (
cif STRING,
type STRING,
ts AS PROCTIME()
) WITH (
'connector' = 'kafka',
'topic' = 'clickstream',
'properties.bootstrap.servers' = 'local-dev_kafka_1:9092',
'scan.startup.mode' = 'earliest-offset',
'format' = 'json'
);
CREATE VIEW events AS
SELECT UUID() AS event_id,
customer_id AS customer_id,
'loan_event' AS type,
CAST(account_id AS STRING) AS payload,
decision_dttm AS ts
FROM v_loan
UNION ALL
SELECT UUID() AS event_id,
cif AS customer_id,
'trx_event' AS type,
CAST(amount AS STRING) AS payload,
ts AS ts
FROM trx
UNION ALL
SELECT UUID() AS event_id,
cif AS customer_id,
'clickstream_event' AS type,
type AS payload,
ts AS ts
FROM clickstream;Dieses Beispiel zeigt, wie Sie die Mustererkennung mithilfe von FlinkSQL definieren können.
Zunächst einmal müssen wir unsere Ereignisse definieren.
- TRX - ein Ereignis, das eine Transaktion mit einem Betrag von mehr als 1000 beschreibt.
- APP_1 - ein Ereignis, das die Benutzerinteraktion mit der Anwendung innerhalb von 3 Tagen nach der Transaktion darstellt.
- NO_LOAN - ein Ereignis, das Sie darüber informiert, dass der Benutzer keinen Kredit aufgenommen hat.
Zweitens müssen wir die Reihenfolge der Ereignisse und die erwartete Ausgabe festlegen. Wir suchen nach einem Muster aus der User Story. Um das Muster zu definieren, verwenden wir den Musterausdruck aus der Flink-Dokumentation. Die Syntax des Musterausdrucks ist einer Syntax für reguläre Ausdrücke sehr ähnlich.
SELECT *
FROM events
MATCH_RECOGNIZE(
PARTITION BY customer_id
ORDER BY ts
MEASURES
TRX.event_id AS trx_event_id,
TRX.customer_id AS trx_customer_id,
TRX.type AS trx_type,
TRX.payload AS trx_payload,
TRX.ts AS trx_ts,
APP_1.event_id AS app_1_event_id,
APP_1.customer_id AS app_1_customer_id,
APP_1.type AS app_1_type,
APP_1.payload AS app_1_payload,
APP_1.ts AS app_1_ts
ONE ROW PER MATCH
PATTERN (TRX APP_1 NOT_LOAN*? APP_2) WITHIN INTERVAL '10' DAY
DEFINE
TRX AS TRX.type = 'trx_event' AND TRX.payload > 1000,
APP_1 AS APP_1.type = 'clickstream_event' AND APP_1.ts < TRX.ts + INTERVAL '3' DAY,
APP_2 AS APP_2.type = 'clickstream_event' AND APP_2.ts > APP_1.ts AND APP_2.ts < APP_1.ts + INTERVAL '7' DAY,
NO_LOAN AS NOT_LOAN.type <> 'loan_event'
) MR;Wie wir sehen, funktioniert die Abfrage der Mustererkennung wie erwartet.
Schlussfolgerungen - Komplexe Ereignisverarbeitung mit Flink
Flink ist eine leistungsstarke Plattform für den Aufbau von Echtzeit-Datenverarbeitungsplattformen, die aus vielen Quellen gespeist werden können. Mit GetInData CDC by JDBC Connector können wir damit beginnen, Wissen aus Legacy-Anwendungen zu extrahieren und eine "datengesteuerte Kultur" in einem Unternehmen einzuführen.
Daten gehören zu den wertvollsten Vermögenswerten Ihres Unternehmens, und wenn Sie sie geschickt einsetzen, können Sie Ihr Geschäft auf eine neue Ebene heben.
Wir planen, den Code des Konnektors als Open-Source-Projekt zu veröffentlichen, also bleiben Sie dran!
Wenn Sie mehr über Complex Event Processing erfahren möchten, besuchen Sie unsere CEP-Plattform.
Verfasst von
Jakub Jurczak
Unsere Ideen
Weitere Blogs




Contact