
Hintergrund
In meiner täglichen Arbeit als Cloud-Berater arbeite ich viel mit Infrastructure as Code (IaC), und im Grunde ist heutzutage alles IaC. Da sich meine Arbeit auf AWS konzentriert, sind die IaC-Tools, die ich verwende, CloudFormation, manchmal Terraform, aber meistens das AWS Cloud Development Kit (CDK). Wenn ich eine neue Infrastruktur mit CDK-Pipelines schreibe, sind das, was am Ende nach der Synthese Ihres Codes herauskommt, CloudFormation-Vorlagen.
Seit der Veröffentlichung von CloudFormation im Jahr 2011 haben der Anbieter AWS und die Community mehrere Tools entwickelt, um Ihre CloudFormation-Vorlagen zu prüfen und zu validieren. Einige, die ich persönlich bei meiner täglichen Arbeit verwende, sind:
-
Cfn-lint ist das CloudFormation Linter-Tool.
-
Cfn-Nag um Sicherheitsprobleme in Ihren Vorlagen zu finden.
-
pre-commit um Ihre Vorlagen/Code vor der Übergabe an bestimmte Hooks zu prüfen.
Da es viele Blogs zu all diesen coolen Tools gibt, werde ich sie hier nicht beschreiben. Dieser Artikel konzentriert sich vielmehr darauf, wie Sie solche coolen Tools in Ihre CDK-Pipeline einbetten können.
Voraussetzung
-
Zugriff auf ein AWS-Konto mit den entsprechenden Rechten für die Bereitstellung von Ressourcen.
-
CDK-Kenntnisse. Da ich zu Beginn direkt über CDK und CDK-Pipelines sprechen werde, sind Kenntnisse zu diesen Themen eine Voraussetzung. Glücklicherweise hat AWS Workshops zu diesen Themen eingerichtet. Schauen Sie sich diese an, wenn Sie CDK und CDK-Pipelines ausprobieren möchten.
Installation
Die Idee dahinter ist, Tools wie cfn-nag und cfn-lint in Ihre CDK Pipeline einzubetten, um sie robuster und sicherer zu machen. Das wird die Chief Information Security Officers (CISO) in einem Unternehmen glücklich machen.
Lassen Sie uns also zunächst mit der Erstellung eines CDK-Projekts beginnen und von dort aus weiterarbeiten.
➜ mkdir cdkpipeline_mit_cfn_nag && cd cdkpipeline_mit_cfn_nag ➜ cdk init app --Sprache python
Mit diesem letzten Befehl erstellen Sie ein projen-Projekt, in dem wir unser S3 Secure Bucket-Konstrukt aufbauen.
Szenario der realen Welt
In Unternehmen ist es DevOps-Teams oft nicht gestattet, Ressourcen von ihrem lokalen Entwicklungsrechner aus bereitzustellen. Der Standard ist, dafür CI/CD zu verwenden. Der Code wird also in ein Repository gestellt und bei einer Pull-Anforderung wird eine Pipeline ausgeführt, um die Ressourcen in einer Entwicklungs-, Test-, Abnahme- und Produktionsumgebung bereitzustellen.
Lassen Sie uns versuchen, das reale Szenario in unserer CDK-App nachzuahmen. Die Idee ist, einen einfachen S3-Bucket in Ihrem AWS-Konto zu erstellen. Dieser Bucket wird über CDK-Pipelines bereitgestellt, um die Vorteile von CI/CD durch Infrastructure as Code zu nutzen. Ich habe mich für einen Bucket entschieden, weil er erstens einfach ist und zweitens gute cfn-nag-Ergebnisse für einen einfachen Bucket liefert. So können wir das Ergebnis unserer Pipeline sehen.
Bauen gehen
Wir haben unser CDK-Projekt initialisiert. Lassen Sie uns zunächst einige Abhängigkeiten installieren. Das Projekt selbst ist in Python geschrieben. Wenn Sie nicht mitmachen wollen, finden Sie am Ende dieses Blogs einen Link zum Code.
Da wir einen Bucket erstellen, fügen Sie das cdk aws s3 Paket hinzu:
pip install aws_cdk.aws_s3
Lassen Sie uns nun den Bucket innerhalb der CDK App erstellen. Ihr CDK-Projekt sollte wie folgt aussehen:
(hashnode) ➜ cdkpipeline_mit_cfn_nag git:(main) ls -sla gesamt 56 0 drwxr-xr-x 12 yvthepief staff 384 Aug 25 21:46 . 0 drwxr-xr-x 4 yvthepief staff 128 Aug 25 21:41 ... 0 drwxr-xr-x 12 yvthepief staff 384 Aug 25 21:46 .git 8 -rw-r--r-- 1 yvthepief staff 124 Aug 25 21:46 .gitignore 0 drwxr-xr-x 6 yvthepief staff 192 Aug 25 21:46 .venv 8 -rw-r--r-- 1 yvthepief staff 1658 Aug 25 21:46 README.md 8 -rw-r--r-- 1 yvthepief staff 1357 Aug 25 21:46 app.py 8 -rw-r--r-- 1 yvthepief staff 777 Aug 25 21:46 cdk.json 0 drwxr-xr-x 4 yvthepief staff 128 Aug 25 21:46 cdkpipeline_mit_cfn_nag 8 -rw-r--r-- 1 yvthepief staff 5 Aug 25 21:46 requirements.txt 8 -rw-r--r-- 1 yvthepief staff 1017 Aug 25 21:46 setup.py 8 -rw-r--r-- 1 yvthepief staff 437 Aug 25 21:46 source.bat
Ich werde die Verzeichnisse der Einfachheit halber ein wenig umstrukturieren. Beginnen Sie also mit der Erstellung von zwei Verzeichnissen: s3bucket und cdkpipeline.
(hashnode) ➜ cdkpipeline_mit_cfn_nag git:(main) mkdir cdkpipeline s3bucket
S3 Bucket erstellen
Erstellen Sie nun innerhalb des s3bucket-Ordners die eigentliche Python-Datei, die zur Erstellung des S3-Buckets verwendet wird.
(hashnode) ➜ cdkpipeline_with_cfn_nag git:(main) cd s3bucket && touch bucket_stack.py
Öffnen Sie diese bucket_stack.py Datei in Ihrem bevorzugten Editor und schreiben Sie einen Code, um einen S3-Bucket zu erstellen.
from aws_cdk importieren ( aws_s3 as s3, Kern als cdk, ) class BucketStack(cdk.Stack): def __init__(self, scope: cdk.Construct, construct_id: str, **kwargs) -> Keine: super().__init__(scope, construct_id, **kwargs) s3.Bucket(self, 'S3Bucket')
Was hier geschieht: Zunächst importieren wir Pakete zur Verwendung von CDK und S3 (das Paket aws_s3, das wir zuvor installiert haben). Zweitens verwenden wir das importierte Paket s3, um den Bucket zu erstellen.
Wir müssen die Datei app.py im Stammverzeichnis aktualisieren, da sie immer noch auf den Ordner cdk_pipeline_with_cfn_nag und den Stack verweist. Schreiben Sie also die Datei app.py mit folgendem Wortlaut neu:
#!/usr/bin/env python3 importieren os from aws_cdk import core as cdk # Für die Konsistenz mit TypeScript-Code,cdkist der bevorzugte Importname für # das Kernmodul des CDK. Die folgende Zeile importiert es auch alscorezur Verwendung # mit Beispielen aus dem CDK Developer's Guide, die gerade überarbeitet werden # wird aktualisiert und verwendetcdk. Sie können diesen Import löschen, wenn Sie ihn nicht benötigen. from aws_cdk import core from s3bucket.bucket_stack import BucketStack app = core.App() BucketStack(app, "Bucket", # Wenn Sie 'env' nicht angeben, ist dieser Stack umgebungsunabhängig. # Konto-/Regionsabhängige Funktionen und Kontextabfragen funktionieren nicht, # aber eine einzige synthetisierte Vorlage kann überall eingesetzt werden. # Unkommentieren Sie die nächste Zeile, um diesen Stack für das AWS-Konto zu spezialisieren. # und Region, die von der aktuellen CLI-Konfiguration impliziert werden. #env=core.Environment(account=os.getenv('CDK_DEFAULT_ACCOUNT'), region=os.getenv('CDK_DEFAULT_REGION')), # Unkommentieren Sie die nächste Zeile, wenn Sie genau wissen, welches Konto und welche Region Sie # den Stack bereitstellen möchten. */ #env=core.Environment(account='123456789012', region='us-east-1'), # Weitere Informationen finden Sie unter https://docs.aws.amazon.com/cdk/latest/guide/environments.html ) app.synth()
Im Grunde importieren wir hier den erstellten Ordner s3bucket mit der Datei bucket_stack.py. Das reicht aus, um die CDK-App zu synthetisieren. Wenn Sie das tun und cdk synth auf der Befehlszeile ausführen, erhalten Sie eine schöne CloudFormation-Vorlage mit einer angegebenen Bucket-Ressource.
Ressourcen: S3Bucket07682993: Typ: AWS::S3::Bucket UpdateReplacePolicy: Behalten LöschungPolitik: Behalten Metadaten: aws:cdk:path: Eimer/S3Bucket/Ressource
Die CloudFormation-Vorlage wird ebenfalls in den Ordner cdk.out geschrieben. Wenn Sie nun lokal den Befehl cfn-nag ausführen, können Sie sehen, dass das Tool cfn-nag 3 Warnungen in der Vorlage findet:
(hashnode) ➜ cdkpipeline_mit_cfn_nag git:(main) ✗ cfn_nag_scan --input-path cdk.out/Bucket.template.json ------------------------------------------------------------ cdk.out/Bucket.template.json ------------------------------------------------------------------------------------------------------------------------ | WARN W51 | | Ressourcen: ["S3Bucket07682993"] | Zeilennummern: [4] | | S3 Bucket sollte wahrscheinlich eine Bucket Policy haben ------------------------------------------------------------ | WARN W35 | | Ressourcen: ["S3Bucket07682993"] | Zeilennummern: [4] | | S3 Bucket sollte die Zugriffsprotokollierung konfiguriert haben ------------------------------------------------------------ | WARN W41 | | Ressourcen: ["S3Bucket07682993"] | Zeilennummern: [4] | | S3 Bucket sollte die Verschlüsselungsoption eingestellt haben Ausfälle zählen: 0 Warnungen zählen: 3
Stellen Sie sich vor, Sie haben ein CDK-Projekt mit mehreren Ressourcen, die von einem kompletten DevOps-Team bearbeitet werden. Diese Liste würde wachsen und wachsen, wenn sie nicht korrekt gehandhabt wird. Um also Sicherheitsfehler und -warnungen in der Unternehmensumgebung abzufangen, müssen wir cfn-nag in die CDK-Pipeline einbetten.
CodeCommit Repository
Damit der Code automatisch ausgeführt werden kann, wenn eine Änderung vorgenommen wurde, müssen wir den Code irgendwo speichern. Ich habe mich für ein CodeCommit-Repository entschieden, um den Code zu speichern. Installieren Sie das Paket aws_codecommit:
(hashnode) ➜ cdkpipeline_mit_cfn_nag git:(main) ✗ pip install aws_cdk.aws_codecommit
Erstellen Sie eine Python-Datei namens repository.py in dem zuvor erstellten Ordner cdkpipeline.
from aws_cdk importieren ( aws_codecommit als codecommit, Kern als cdk ) class RepositoryStack(cdk.Stack): def __init__(self, scope: cdk.Construct, construct_id: str, **kwargs) -> Keine: super().__init__(scope, construct_id, **kwargs) # Codecommit-Repository zum Speichern von Dateien erstellen codecommit.Repository( self, 'Repository', repository_name='cdkpipeline_mit_cfn_nag', description='Repository für CDK-Pipeline mit CFN Nag' )
Fügen Sie dies zu Ihrer app.py Datei hinzu, damit sie bereitgestellt werden kann. Dies ist eines der beiden Dinge, die von Ihrem lokalen Rechner aus bereitgestellt werden sollten. Die zweite Sache ist die Erstellung der "ersten" Pipeline. Alles andere wird bereitgestellt, wenn Änderungen am Code vorgenommen und in das Repository übertragen werden.
< schnipsel app.py > from cdkpipeline.repository import RepositoryStack < schnipsel app.py > RepositoryStack(app, 'SourceRepository')
Wenn Sie nun den Befehl cdk synth in Ihrem Terminal ausführen, werden Sie eine andere Ausgabe sehen. Das liegt daran, dass Sie innerhalb von app.py 2 Stapel definiert haben:
(hashnode) ➜ cdkpipeline_mit_cfn_nag git:(main) ✗ cdk synth Erfolgreich synthetisiert in /Users/yvthepief/Code/Hashnode/cdkpipeline_with_cfn_nag/cdk.out Geben Sie eine Stack-ID (Bucket, SourceRepository) an, um die entsprechende Vorlage anzuzeigen.
Im Grunde genommen müssen Sie den Namen der Stack-ID mit Ihrem cdk synth Befehl hinzufügen, um die Vorlage zu synthetisieren. Stellen Sie die SourceRepository-Vorlage bereit, damit das CodeCommit-Repository verfügbar ist.
(hashnode) ➜ cdkpipeline_mit_cfn_nag git:(main) ✗ cdk deploy SourceRepository SourceRepository: Bereitstellen... SourceRepository: CloudFormation-Änderungssatz erstellen... ✅ SourceRepository Stack ARN: arn:aws:cloudformation:eu-west-1:012345678910:stack/SourceRepository/340ef5f0-05e8-11ec-8ea0-02e6d12e35b9
Prüfen Sie Ihren Code in dem neu erstellten Repository. Ich verwende dazu das Python-Paket git-remote-codecommit.
(hashnode) ➜ cdkpipeline_mit_cfn_nag git:(main) ✗ git remote add origin codecommit::eu-west-1://cdkpipeline_mit_cfn_nag (hashnode) ➜ cdkpipeline_mit_cfn_nag git:(main) ✗ git commit -a -m "repository stack und bucket hinzugefügt"[main 9051190] repository stack und bucket hinzugefügt 3 Dateien geändert, 4 Einfügungen(+), 18 Löschungen(-) Modus löschen 100644 cdkpipeline_mit_cfn_nag/__init__.py Modus löschen 100644 cdkpipeline_mit_cfn_nag/cdkpipeline_mit_cfn_nag_stack.py (hashnode) ➜ cdkpipeline_mit_cfn_nag git:(main) ✗ git push origin main Objekte aufzählen: 15, fertig. Zählen der Objekte: 100% (15/15), erledigt. Delta-Kompression mit bis zu 8 Fäden Objekte komprimieren: 100% (13/13), erledigt. Objekte schreiben: 100% (15/15), 3.78 KiB | 1.89 MiB/s, erledigt. Insgesamt 15 (delta 3), wiederverwendet 0 (delta 0), pack-reused 0 An codecommit::eu-west-1://cdkpipeline_mit_cfn_nag * [neuer Zweig] main -> Haupt
Das war's also. Das Repository ist erstellt und der anfängliche Code für den CDK S3-Bucket-Stack wird gepusht. Fügen Sie nun eine CDK-Pipeline hinzu.
CDK-Pipeline
Für die CDK-Pipeline müssen wir eine Datei cdkpipeline.py im Ordner cdkpipeline erstellen, in dem sich auch die Datei repository.py befindet. Der Inhalt sollte wie folgt aussehen, ich habe Kommentare zur Erklärung hinzugefügt:
# Module importieren
from aws_cdk importieren (
aws_codecommit als codecommit,
Pipelines,
Kern als cdk
)
# Klasse für den CDK-Pipeline-Stack
class CdkPipelineStack(cdk.Stack):
def __init__(self, scope: cdk.Construct, construct_id: str, **kwargs) -> Keine:
super().__init__(scope, construct_id, **kwargs)
# Erstelltes Repository nach Namen verwenden, im Grunde das mit cdk erstellte Repository importieren deploy SourceRepository
repository = codecommit.Repository.from_repository_name(self, 'pipeline_repository', 'cdkpipeline_with_cfn_nag')
# CDK-Pipeline erstellen
pipeline = pipelines.CodePipeline(
selbst, "CDKPipeline",
pipeline_name="CDKPipeline",
# Synthezisieren und prüfen Sie alle Vorlagen im cdk.out Verzeichnis mit cfn_nag
synth=pipelines.ShellStep("Synth",
# Verweisen Sie die Quelle auf das Codecommit-Repository.
input=pipelines.CodePipelineSource.code_commit(repository, "main"),
# Tatsächliche Befehle, die im CodeBuild-Build verwendet werden.
befehle=[
"npm install -g aws-cdk",
"gem install cfn-nag",
"pip install -r requirements.txt",
"cdk synth",
"mkdir ./cfnnag_output",
"for template in $(find ./cdk.out -type f -maxdepth 2 -name '*.template.json'); do cp $template ./cfnnag_output; done",
"cfn_nag_scan --input-path ./cfnnag_output",
]
)
)
Achten Sie auf die Liste der Befehle in der Synth-Konfiguration. Innerhalb der Synth-Konfiguration gibt es zusätzliche Befehle nach dem cdk synth.
"mkdir ./cfnnag_output", "for template in $(find ./cdk.out -type f -maxdepth 2 -name '*.template.json'); do cp $template ./cfnnag_output; done", "cfn_nag_scan --input-path $template",
Im Grunde genommen wird zunächst ein Verzeichnis cfnnag_output angelegt. Dann kopieren wir für jede Vorlage (Datei), die sich im cdk.out Verzeichnis befindet, die Vorlagendatei in das cfnnag_output Verzeichnis. Nach dem Kopieren führen Sie einen cfn_nag_scan über das Ausgabeverzeichnis durch. CFN_NAG scannt alle template.json Dateien im Verzeichnis cfnnag_output.
Der Grund, warum wir die *.template.json-Dateien zunächst in ein separates Verzeichnis kopieren, liegt darin, dass sich im Verzeichnis cdk.out, das von CDK synth erstellt wird, mehr json-Dateien befinden. Zweitens, wenn wir den CFN_NAG-Scan direkt in der for-Schleife durchführen, wird CodeBuild nicht mit einem Fehler beendet, da es als letztes eine korrekte Vorlage zum Testen finden könnte, und somit wird die CodePipeline immer erfolgreich sein. Und die ganze Idee hier ist, zu testen und die Pipeline bei Fehlern in der Ausgabe von CFN_NAG fehlschlagen zu lassen
Fügen Sie die Python-Pakete, von denen wir abhängig sind, mit den import-Anweisungen hinzu:
(hashnode) ➜ cdkpipeline_mit_cfn_nag git:(main) ✗ pip install aws_cdk.aws_codecommit aws_cdk.pipelines
Der nächste Schritt besteht darin, eine Stage zu erstellen, so dass die Stage, die den S3-Bucket erstellt, von der CDK-Pipeline verwendet wird. Beginnen Sie mit dem Importieren des zuvor erstellten S3-Bucket-Stacks, der Datei bucket_stack.py, in die Datei cdkpipeline.py:
from s3bucket.bucket_stack import BucketStack
Fügen Sie auch im cdkpipeline.py die Bühne hinzu, vorzugsweise über dem class CdkPipelineStack(cdk.Stack):
# Klasse für die Erstellung des S3Bucket Stage Klasse S3BucketStage(cdk.Stage): def __init__(self, scope: cdk.Construct, construct_id: str, **kwargs) -> Keine: super().__init__(scope, construct_id, **kwargs) # Erstellen Sie den Bucket Stack, der die bucket_stack.py verwendet, um einen S3-Bucket zu erstellen. s3_bucket = BucketStack(self, "S3BucketStack")
Nun ist es an der Zeit, die neu erstellte Stufe innerhalb der CDK-Pipeline aufzurufen. Fügen Sie die Stufe zur Pipeline hinzu, also unterhalb der Pipeline-Definition innerhalb der Klasse CdkPipelineStack:
# Bereitstellen der S3 Bucket Stage s3Deplpoy = pipeline.add_stage( S3BucketStage( self, 'S3BucketStage', # env=cdk.Environment( # account="123456789012", # region="eu-west-1" ) ) )
Wenn Sie den Bucket Stack für ein anderes Konto oder eine andere Region bereitstellen möchten, heben Sie die Kommentare in den Zeilen auf, um die env mit einer Kontonummer oder Region zu versehen.
CDK Versionierung
Diese CDK-Pipelines verwenden Vorabversionen des CDK-Frameworks, die Sie aktivieren können, indem Sie Folgendes zu cdk.json hinzufügen:
{
// ...
"Kontext": {
"@aws-cdk/core:newStyleStackSynthesis": true
}
}
Anpassen app.py
Der letzte Punkt, den Sie ändern müssen, ist, dass wir CDK in der Datei app.py nicht mehr so konfiguriert haben, dass es das SourceRepository und den Bucket bereitstellt, sondern dass wir dies in das SourceRepository und die CDKPipeline ändern müssen. Beginnen Sie also mit dem Importieren der neu erstellten cdkpipeline.py Datei:
from cdkpipeline.cdkpipeline import CdkPipelineStack
und entfernen Sie den Import des BucketStack. Ändern Sie nun die BucketStack-Definition in CdkPipelineStack:
CdkPipelineStack(app, "CdkPipeline")
Nachdem app.py für die Bereitstellung des SourceRepository und der CdkPipeline konfiguriert wurde, haben wir die CDK-Konfiguration abgeschlossen.
An CodeCommit binden
Übertragen Sie alles in das CodeCommit-Repository, das wir bereits bereitgestellt haben. Da die CDK-Pipeline sich selbst mutiert, wird sie nach der Bereitstellung dieses Repository als Quelle verwenden.
<p>(hashnode) ➜ cdkpipeline_mit_cfn_nag git:(main) ✗ git status Auf Abzweigung Haupt Unverfolgte Dateien: (verwenden Sie "git add..." in das, was begangen werden soll, aufzunehmen) cdkpipeline/ s3bucket/ der Übertragung wurde nichts hinzugefügt, aber es sind noch nicht verfolgte Dateien vorhanden (verwenden Sie "git add" zum Verfolgen) (hashnode) ➜ cdkpipeline_mit_cfn_nag git:(main) ✗ git add -A (hashnode) ➜ cdkpipeline_with_cfn_nag git:(main) ✗ git commit -a -m "added cdkpipeline to deploy s3bucket"[main e7bac04] added cdkpipeline to deploy s3bucket 4 Dateien geändert, 93 eingefügt(+) Modus erstellen 100644 cdkpipeline/cdkpipeline.py Modus erstellen 100644 cdkpipeline/repository.py Modus erstellen 100644 s3bucket/__init__.py Modus erstellen 100644 s3bucket/bucket_stack.py (hashnode) ➜ cdkpipeline_mit_cfn_nag git:(main) git push origin main Objekte aufzählen: 15, fertig. Zählen der Objekte: 100% (15/15), erledigt. Delta-Kompression mit bis zu 8 Fäden Objekte komprimieren: 100% (12/12), erledigt. Objekte schreiben: 100% (13/13), 2.36 KiB | 1.18 MiB/s, erledigt. Insgesamt 13 (delta 4), wiederverwendet 0 (delta 0), pack-reused 0 An codecommit::eu-west-1://cdkpipeline_mit_cfn_nag 9051190..b9e5f62 main -> Haupt
CDK-Pipeline bereitstellen
Da sich nun alles im CodeCommit befindet, müssen wir den CdkPipelineStack nur noch einmal über die Befehlszeile bereitstellen. Dadurch wird die CDK-Pipeline eingerichtet. Da sie sich selbst verändert, aktualisiert sie sich selbst, wenn Änderungen an der Pipeline in das CodeCommit-Repository übertragen werden. Zum Beispiel durch das Hinzufügen zusätzlicher Phasen, die sich auf andere Regionen oder andere Konten beziehen können.
(hashnode) ➜ cdkpipeline_mit_cfn_nag git:(main) cdk synth Erfolgreich synthetisiert in /Users/yvthepief/Code/Hashnode/cdkpipeline_with_cfn_nag/cdk.out Geben Sie eine Stack-ID an (CdkPipeline, SourceRepository), um die Vorlage anzuzeigen. (hashnode) ➜ cdkpipeline_mit_cfn_nag git:(main) cdk deploy CdkPipeline Bei dieser Bereitstellung werden potenziell sensible Änderungen gemäß Ihrer aktuellen Sicherheitsgenehmigungsstufe (--require-approval broadening) vorgenommen. Bitte bestätigen Sie, dass Sie die folgenden Änderungen vornehmen möchten: <....SNIPPIT....> (HINWEIS: Es kann sicherheitsrelevante Änderungen geben, die nicht in dieser Liste enthalten sind. Siehe https://github.com/aws/aws-cdk/issues/1299) Möchten Sie diese Änderungen übernehmen (ja/nein)?
Drücken Sie y und Enter, um die CDK-Pipeline einzusetzen.
CdkPipeline: Bereitstellen... [0%] starten: Publishing f440c606564105ef3cc7d78e8454da66e58d752539fbaa74fc5bc25c379465e2:current_account-current_region [100%] Erfolg: Published f440c606564105ef3cc7d78e8454da66e58d752539fbaa74fc5bc25c379465e2:current_account-current_region CdkPipeline: CloudFormation-Änderungssatz erstellen... ✅ CdkPipeline Stack ARN: arn:aws:cloudformation:eu-west-1:123456789012:stack/CdkPipeline/28870680-0bd5-11ec-bec5-06eb6afe4d91
Überprüfen der CFN_NAG-Ergebnisse
Wenn also die CDK-Pipeline eingerichtet ist, wird der erste Lauf automatisch gestartet. Das Ergebnis ist ein erfolgreicher Lauf, bei dem als Endziel ein S3-Bucket erstellt wird. Siehe Bildschirmfoto unten.
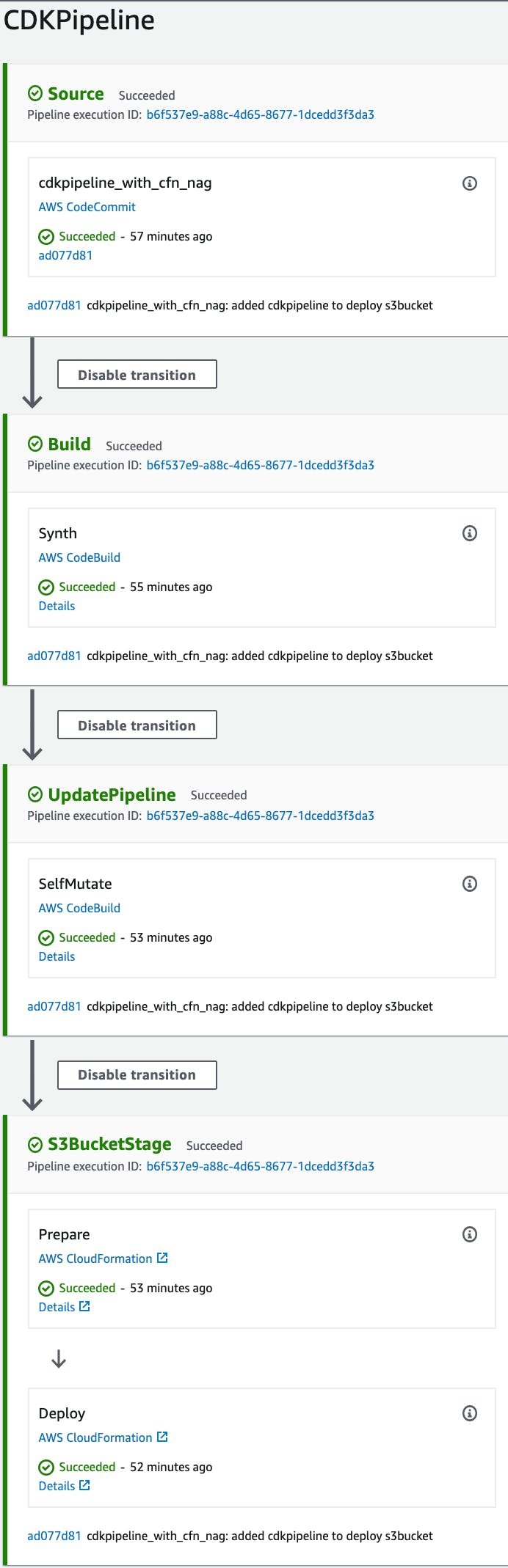
Während der Ausführung der CodeBuild-Phase, die für die Generierung der CloudFormation-Vorlage verantwortlich ist, wird auch unsere CFN_NAG for-Schleife ausgeführt. Alle Vorlagen werden also mit CFN_NAG validiert. Dieses Ergebnis kann innerhalb des CodeBuild-Schrittes der Pipeline überprüft werden. Klicken Sie einfach auf Details in der Synth Stage der Pipeline.
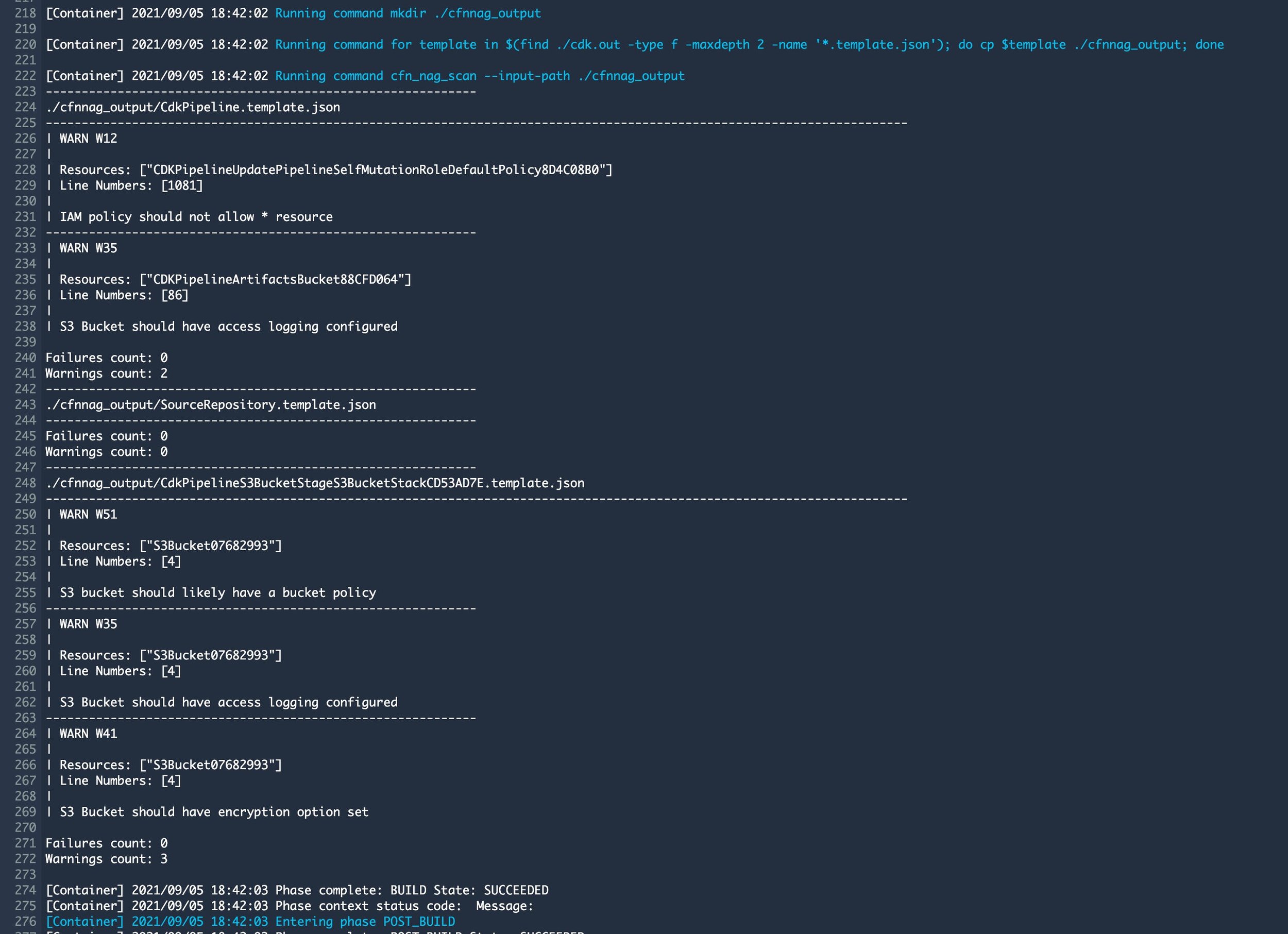
Wie Sie sehen können, werden zwei Vorlagen getestet und enthalten nur Warnungen. Dies kann behoben werden, indem Sie ein sicheres Bucket CDK-Konstrukt erstellen, das ich in einem nächsten Blog beschreiben werde.
Versuchen Sie es selbst
Der Code kann in meinem GitHub gefunden werden. Sehen Sie sich auch seinen nächsten Blog zu diesem Thema an.
Verfasst von
Yvo van Zee
I'm an AWS Cloud Consultant working at Oblivion. I specialised myself in architecting and building high available environments using automation (Infrastructure as Code combined with Continuous Integration and Continuous Delivery (CI/CD)). Challenging problems and finding solutions which fit are my speciality.
Unsere Ideen
Weitere Blogs




Contact