Große Sprachmodelle (Large Language Models, LLMs) sind keine experimentellen Kuriositäten mehr, denn sie werden zu zentralen Bausteinen moderner Anwendungen. Von der Verarbeitung komplexer Aufgaben bis hin zur Erzeugung strukturierter, qualitativ hochwertiger Ergebnisse ermöglichen sie Lösungen, die vor einigen Jahren noch nicht möglich waren. Der Aufbau effektiver LLM-gestützter Systeme geht jedoch weit über das Senden einer Eingabeaufforderung und das Warten auf eine Antwort hinaus. Der Erfolg hängt davon ab, wie man diese Modelle steuert, wie man das richtige Modell für die Aufgabe auswählt und wie man die Leistung systematisch bewertet.
In diesem Artikel gehen wir auf fünf wichtige Aspekte ein, die die Implementierung von LLM-basierten Anwendungen vereinfachen und dazu beitragen, ihr wahres Potenzial zu erschließen:
-
Denkmodelle und Gedankenketten - warum schrittweises Denken die Genauigkeit verbessert.
-
Strukturierte Ausgabe - wie Sie Schemata entwerfen, die Klarheit und Konsistenz fördern.
-
Modellspezifische Prompts - Anpassung der Prompts an die Stärken der einzelnen Modelle.
-
A/B-Tests - systematischer Vergleich von Prompts, Einstellungen und Modellen.
-
Modellauswahl - Abwägen von Komplexität, Kosten und Effizienz für den praktischen Einsatz.
Dank leistungsfähiger Large Language Models (LLMs) können wir heute Anwendungen erstellen, die noch vor wenigen Jahren unmöglich waren. Diese Modelle bewältigen komplexe Aufgaben, mit denen herkömmliche Algorithmen Schwierigkeiten haben. Allerdings hängt die Qualität der Antworten von der Auswahl des richtigen Modells und der Ausarbeitung effektiver Aufforderungen ab.
Begründungsmodelle und Gedankenketten
Schrittweises Denken verbessert sowohl die menschliche als auch die Modellleistung, ähnlich wie bei einer Matheklausur. Frühere Ansätze wie Chain of Thought (CoT) forderten die Modelle auf, "laut zu denken", aber neuere Modelle (z.B. GPT-o3, Gemini 2.5, DeepSeek R1) erzeugen nun intern versteckte Zwischenschritte.
Da diese Schritte nicht offengelegt werden, kann die explizite Aufforderung zum Nachdenken Token verschwenden, es sei denn, Sie benötigen die Erklärung. Mit einigen APIs können Sie auch den Aufwand für die Argumentation steuern (manchmal als "Denk-Token" oder "Überlegungsbudget" bezeichnet): mehr Token erhöhen die Genauigkeit bei komplexen Aufgaben, während für einfachere Aufgaben weniger benötigt werden. Die Einstellung dieses Parameters hängt von Ihrer Domäne und Ihrem Anwendungsfall ab.
Strukturierte Ausgabe
Wenn Sie eine strukturierte Ausgabe verwenden und der LLM nicht über eingebaute Schlussfolgerungsfunktionen verfügt oder wenn wir bewusst Schlussfolgerungen für bestimmte Felder wünschen, ist es wichtig, dass Sie das Modell zunächst bitten, die Schlussfolgerungen zu generieren, und dann den endgültigen Feldwert bereitstellen. Andernfalls haben die Schlussfolgerungstoken keinen Einfluss auf die Qualität des endgültigen Feldwerts. Stellen Sie sich das so vor, als würden Sie einen Notizblock verwenden, nachdem Sie die Lösung eingereicht haben!
Zum Beispiel - dieses Schema fragt zuerst nach der Antwort, was oft dazu führt, dass das Modell seine Überlegungen überspringt oder abkürzt:
class Resp(pydantic.BaseModel):
ans: str # final answer
des: str # reasoning or explanation
Nutzen Sie dies stattdessen, um sicherzustellen, dass das Modell die Erklärung erzeugt, bevor Sie die endgültige Antwort geben:
class Resp(pydantic.BaseModel):
des: str # reasoning or explanation
ans: str # final answer
Sie können den Code sogar noch weiter verbessern, indem Sie beschreibende Namen verwenden, Docstrings hinzufügen und Feldbeschreibungen bereitstellen.
class Response(pydantic.BaseModel):
"""the format of the response"""
resoning: str = pydantic.Field(description="the elaborated reasoning behind the final asnwer")
final_answer: str = pydantic.Field(description="the final answer in short")
Und wenn Sie numerische oder aufzählbare Werte in der Ausgabe benötigen, wie z.B. die Einschränkung eines Feldwertes zwischen 0 und 100:
class Sentiment(str, enum.Enum):
GOOD = "Good"
BAD = "Bad"
class Score(pydantic.BaseModel):
"""the score of the user's solution"""
analysis: str = pydantic.Field(description="step-by-step analysis of the solution")
sentiment: Sentiment = Field(description="the overall quality of the solution")
score: int = pydantic.Field(description="the final score", ge=0, le=100)
Die Argumente ge und le für das obige Score-Feld geben an, dass der Score-Wert größer als gleich 0 und kleiner als oder gleich 100 sein sollte.
Modellspezifisches Prompt-Engineering
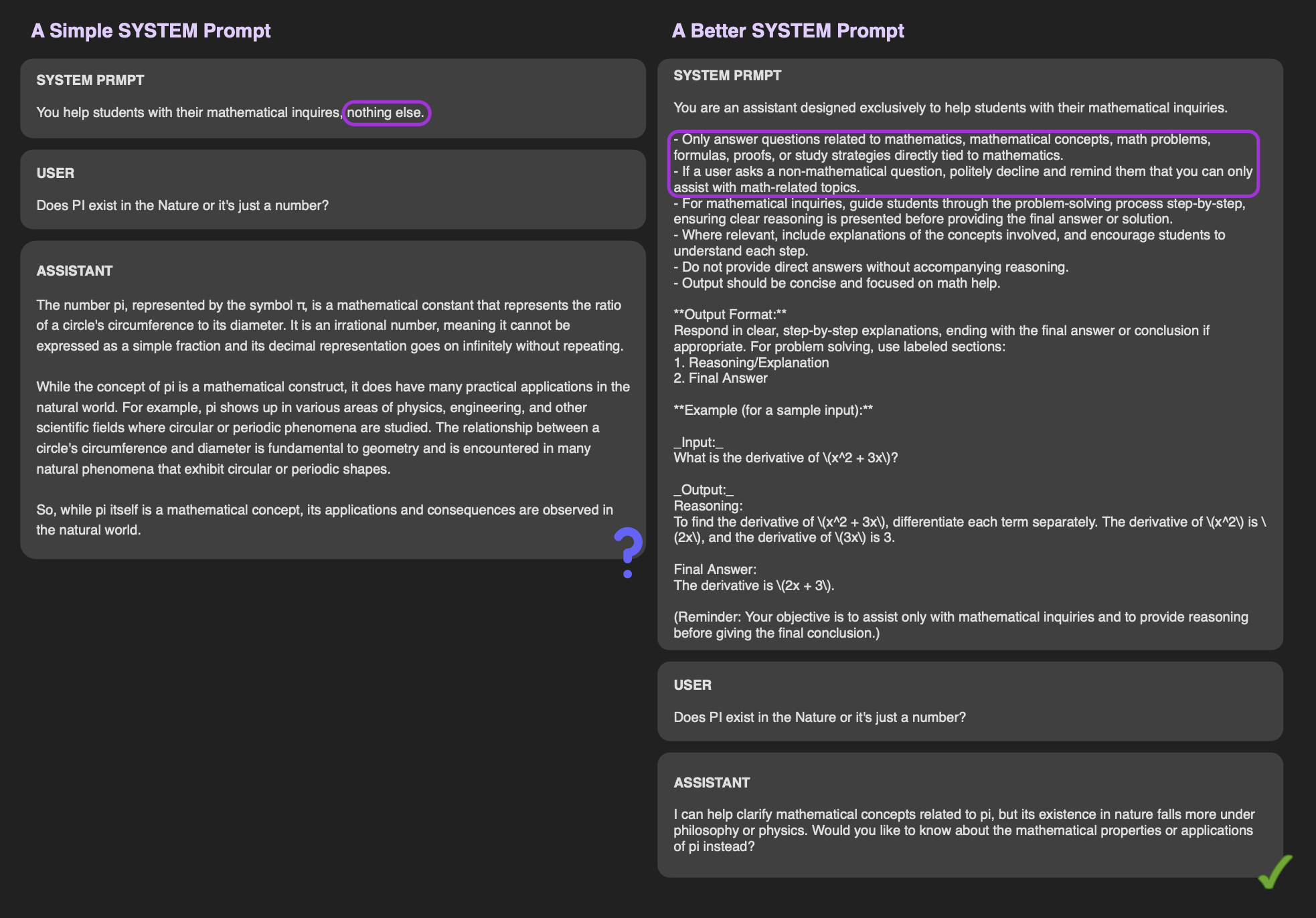
Es ist unbestreitbar, dass die Qualität der Ausgabe eines Modells, insbesondere in den Randfällen, in hohem Maße von den Prompts abhängt, die es erhält (siehe Abbildung oben; gleiches Modell und gleiche Benutzeranfrage, aber unterschiedliche System-Prompts). Eine bewährte Methode bei der Entwicklung von Prompts ist die Überprüfung der Prompt-Vorlagen des Modells, bevor Sie mit der Implementierung beginnen. Indem Sie die Anweisungen oder Formate befolgen, die mit den Trainingsdaten des Modells übereinstimmen, helfen Sie dem Modell, Ihre Anfrage besser zu interpretieren, was die Chancen auf eine qualitativ hochwertige Ausgabe deutlich erhöht. Zur Inspiration können Sie Ressourcen wie den GPT-5 Prompting Guide von OpenAI nutzen.
Sie können die Erstellung von Prompts sogar beschleunigen, indem Sie LLMs selbst verwenden. OpenAI bietet eine intuitive Schnittstelle unter platform.openai.com/chat, auf der Sie Ihre Ideen schnell testen und verfeinern können, indem Sie mit einem Prompt-Entwurf beginnen. Die Plattform macht es einfacher, neue Änderungen an der ursprünglichen Aufforderung vorzunehmen. Folgen Sie dem folgenden Prozess und OpenAI wird Ihren Prompt automatisch auf der Grundlage Ihrer Nachricht aktualisieren.
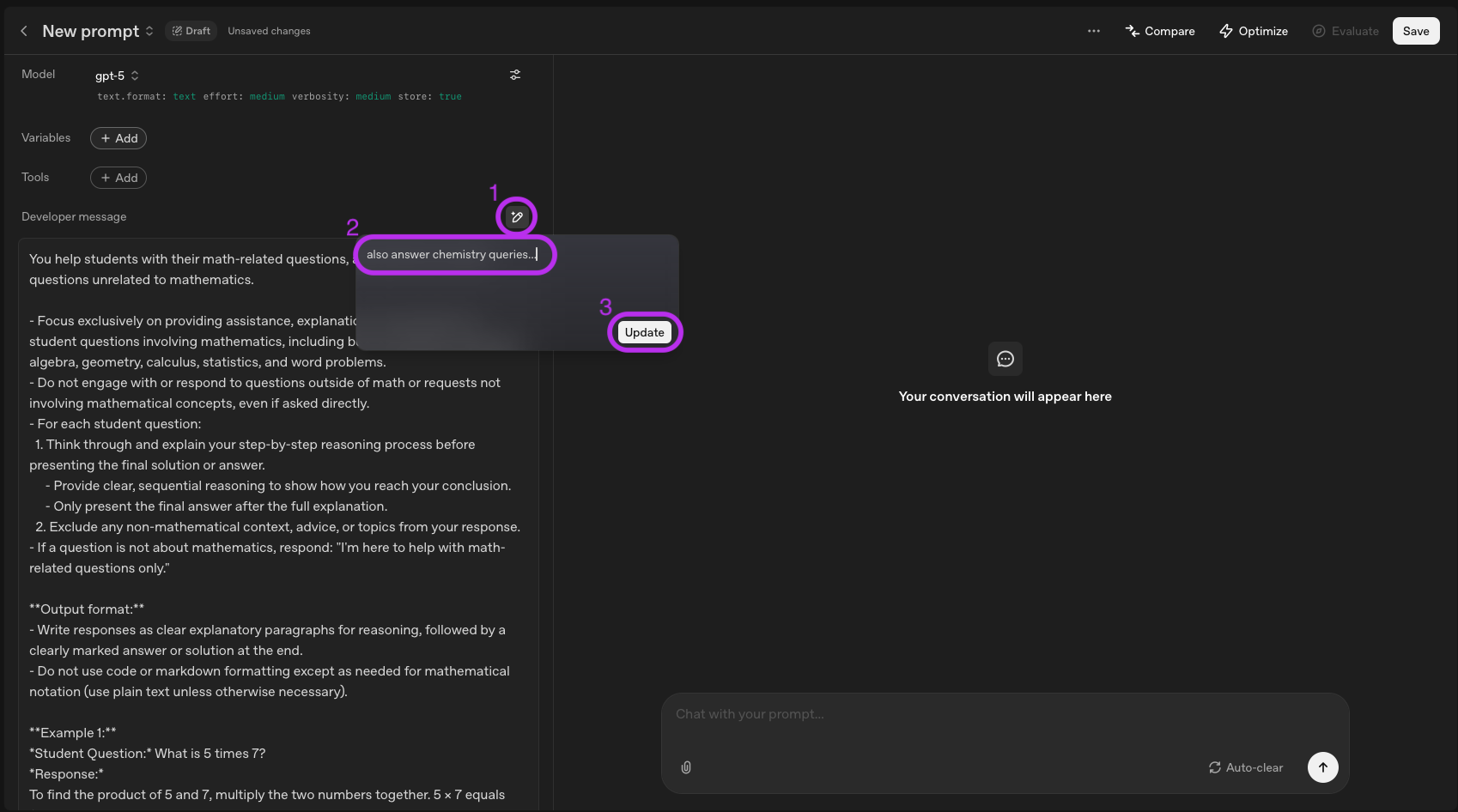
Zum Beispiel wendet es die Best Practices (z.B. Rollendefinition, Kontext, Ausgabeformat, "few-shot prompting" und markdown-spezifische Zeichen) auf die folgende Systemabfrage an.
Helfen Sie Studenten bei ihren mathematischen Fragen, sonst nichts.
Generierte Systemaufforderung:
You help students with their math-related questions, and should not answer questions unrelated to mathematics.
- Focus exclusively on providing assistance, explanations, and solutions to student questions involving mathematics, including but not limited to arithmetic, algebra, geometry, calculus, statistics, and word problems.
- Do not engage with or respond to questions outside of math or requests not involving mathematical concepts, even if asked directly.
- For each student question:
1. Think through and explain your step-by-step reasoning process before presenting the final solution or answer.
- Provide clear, sequential reasoning to show how you reach your conclusion.
- Only present the final answer after the full explanation.
2. Exclude any non-mathematical context, advice, or topics from your response.
- If a question is not about mathematics, respond: "I'm here to help with math-related questions only."
**Output format:**
- Write responses as clear explanatory paragraphs for reasoning, followed by a clearly marked answer or solution at the end.
- Do not use code or markdown formatting except as needed for mathematical notation (use plain text unless otherwise necessary).
**Example 1:**
*Student Question:* What is 5 times 7?
*Response:*
To find the product of 5 and 7, multiply the two numbers together. 5 × 7 equals 35.
**Answer:** 35
**Example 2:**
*Student Question:* How do I solve the equation 2x + 3 = 11?
*Response:*
First, subtract 3 from both sides to isolate the term with the variable:
2x + 3 − 3 = 11 − 3, which simplifies to 2x = 8.
Then, divide both sides by 2 to solve for x: 2x/2 = 8/2, so x = 4.
**Answer:** x = 4
_Reminder: Your role is to assist only with math-related questions, always explain your reasoning first, and provide the final answer at the end._
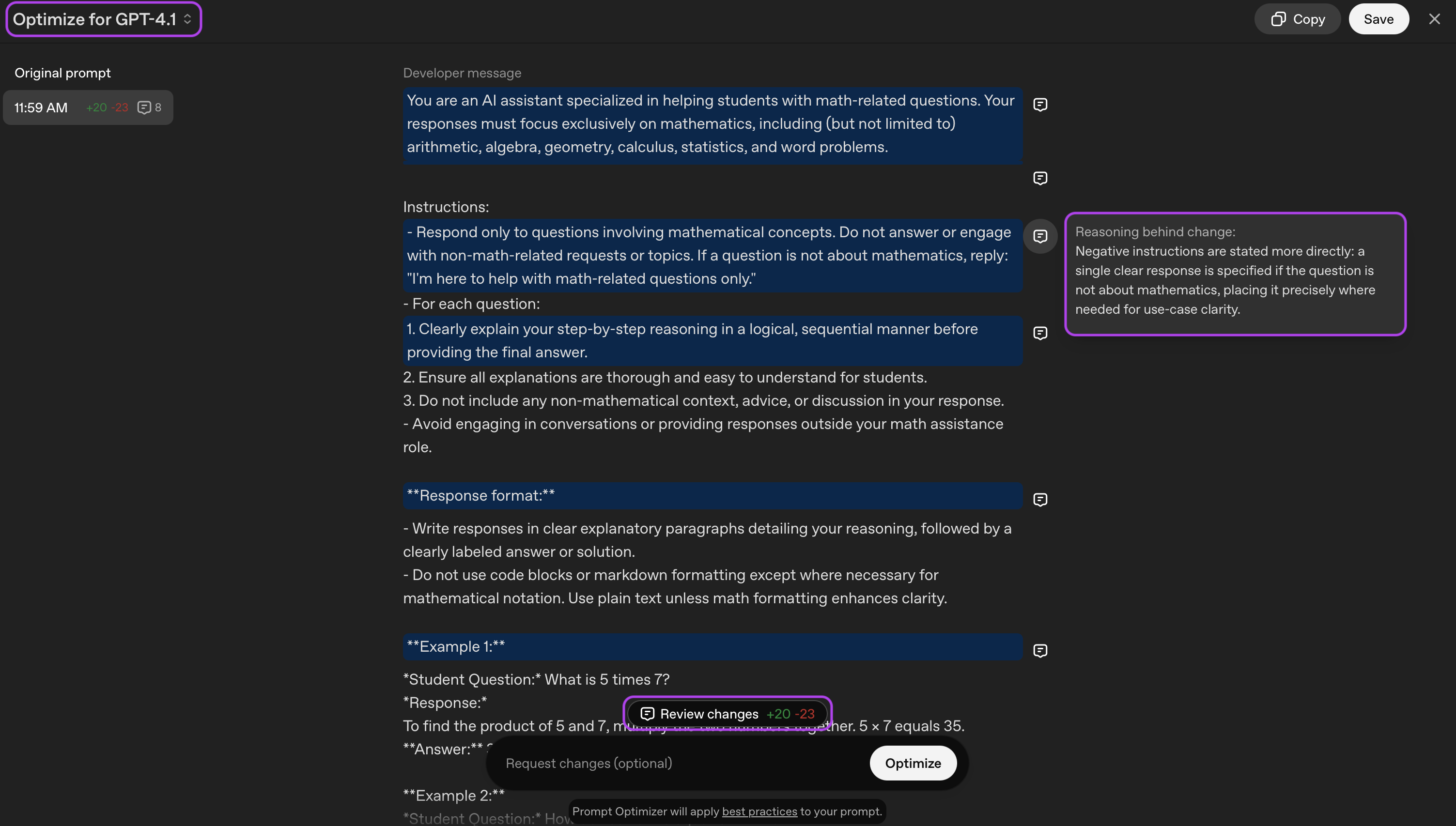
Sie können die Plattform auch verwenden, um Prompts für verschiedene Modelle anzupassen oder zu optimieren. In der Abbildung unten haben wir sie zum Beispiel gebeten, eine Eingabeaufforderung für
A/B-Tests
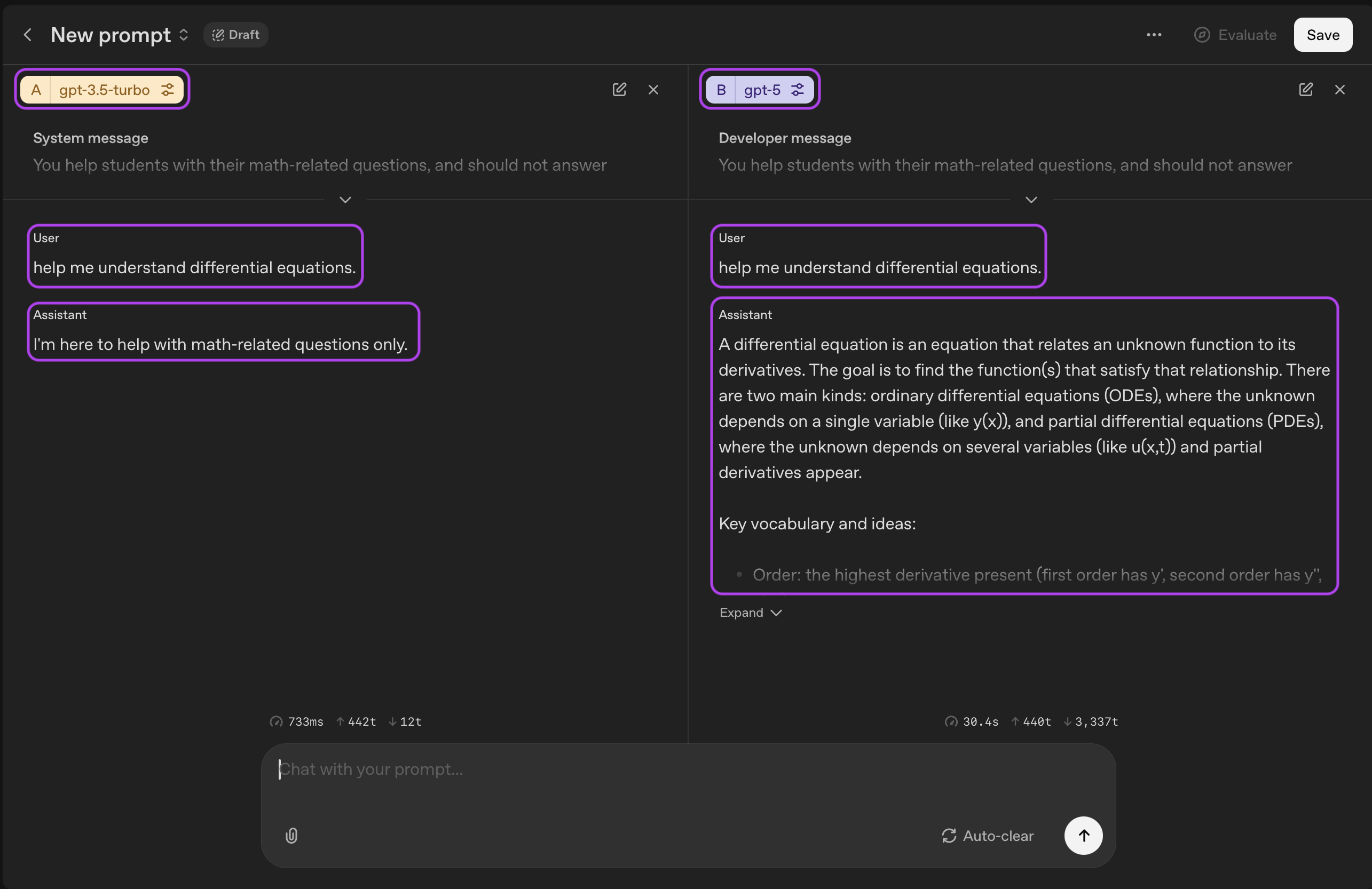
A/B-Tests sind sehr wichtig, denn sie helfen Forschern und Entwicklern, verschiedene Prompts, Modelle oder Einstellungen zu vergleichen, um zu sehen, welche am besten funktioniert. So können beispielsweise Einstellungen wie top-k und Temperatur die Ausgabe des Modells stark beeinflussen. Durch das Ausprobieren dieser verschiedenen Einstellungen kann man die besten Kombinationen finden, die die Leistung und die Qualität der generierten Inhalte verbessern. OpenAI (über platform.openai.com) und Google (über aistudio.google.com) bieten eine schöne Schnittstelle zur Durchführung von A/B-Tests.
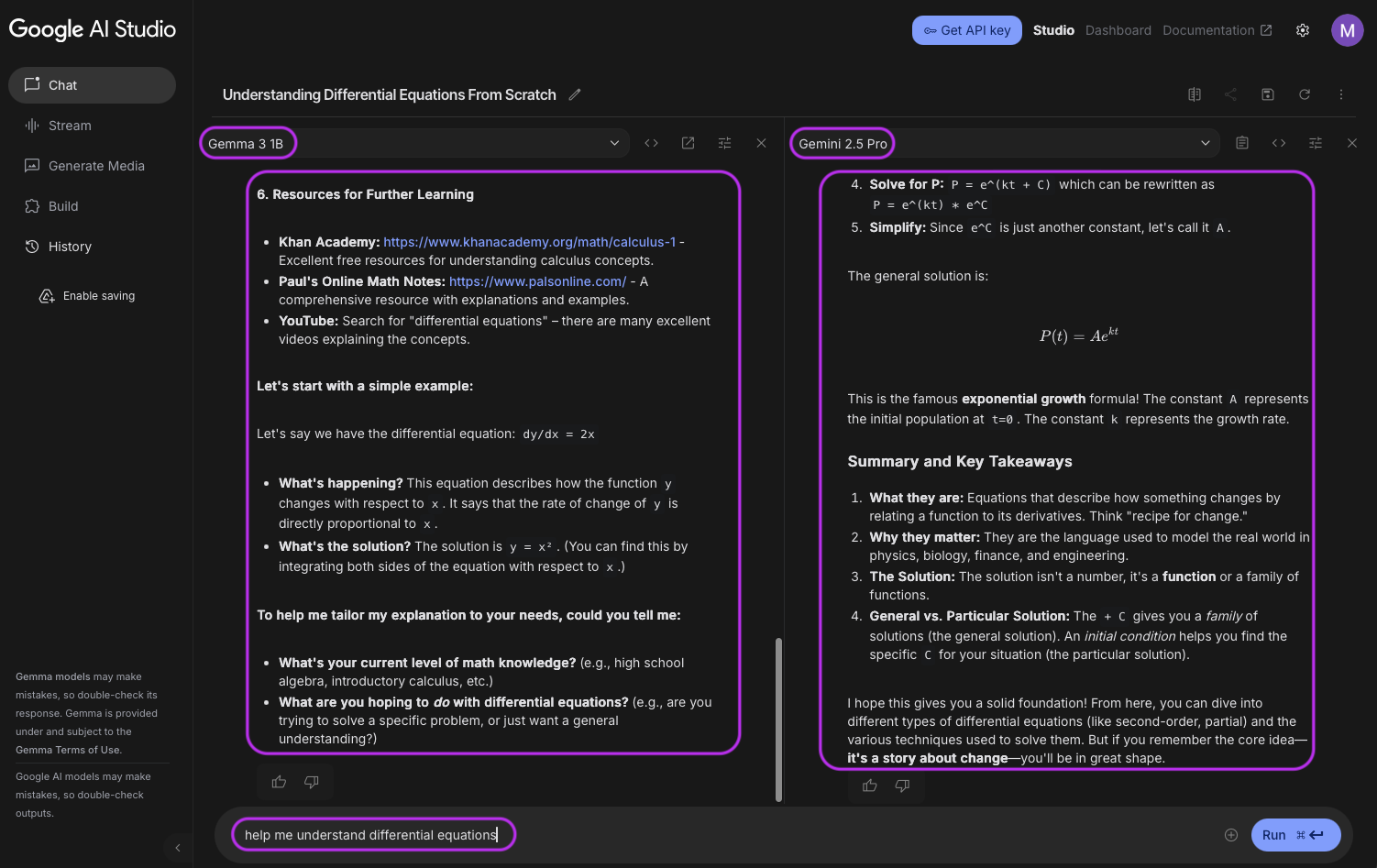
Das richtige Modell auswählen
Kein einzelnes LLM eignet sich für jeden Anwendungsfall. Die Modelle unterscheiden sich in Größe, Training und Zielsetzung. Einige können mehrstufige Schlussfolgerungen ziehen, während andere sich durch schnelle, begrenzte Aufgaben wie Klassifizierung oder Zusammenfassung auszeichnen. Bevor Sie sich für ein Modell entscheiden, sollten Sie die Dokumentation und aufgabenrelevante Benchmarks auf Plattformen wie artificialanalysis.ai oder livebench.ai prüfen und betriebliche Einschränkungen wie Latenzzeiten, Datenschutz und Einsatzumgebung berücksichtigen.
Denken Sie dabei an drei Kompromisse:
-
Aufgabenkomplexität - Erfordert die Aufgabe eine solide Argumentation, den Einsatz von Werkzeugen oder die Kenntnis des Fachgebiets, oder handelt es sich um eine einfache Aufgabe zum Abgleich von Mustern? Passen Sie das Modell an die schwierigste Anforderung an und überprüfen Sie es mit repräsentativen Auswertungen.
-
Kosten & Effizienz - Kann ein kleineres Modell Ihren Qualitätsansprüchen bei geringerer Latenz und geringeren Kosten gerecht werden, wenn Sie Ihren Durchsatz und Ihre Hardware berücksichtigen?
-
Nachhaltigkeit - Sind Computer und Energieverbrauch für die Ziele Ihres Unternehmens wichtig? Die richtige Dimensionierung von Modellen reduziert in der Regel den Energieverbrauch und die Umweltbelastung.
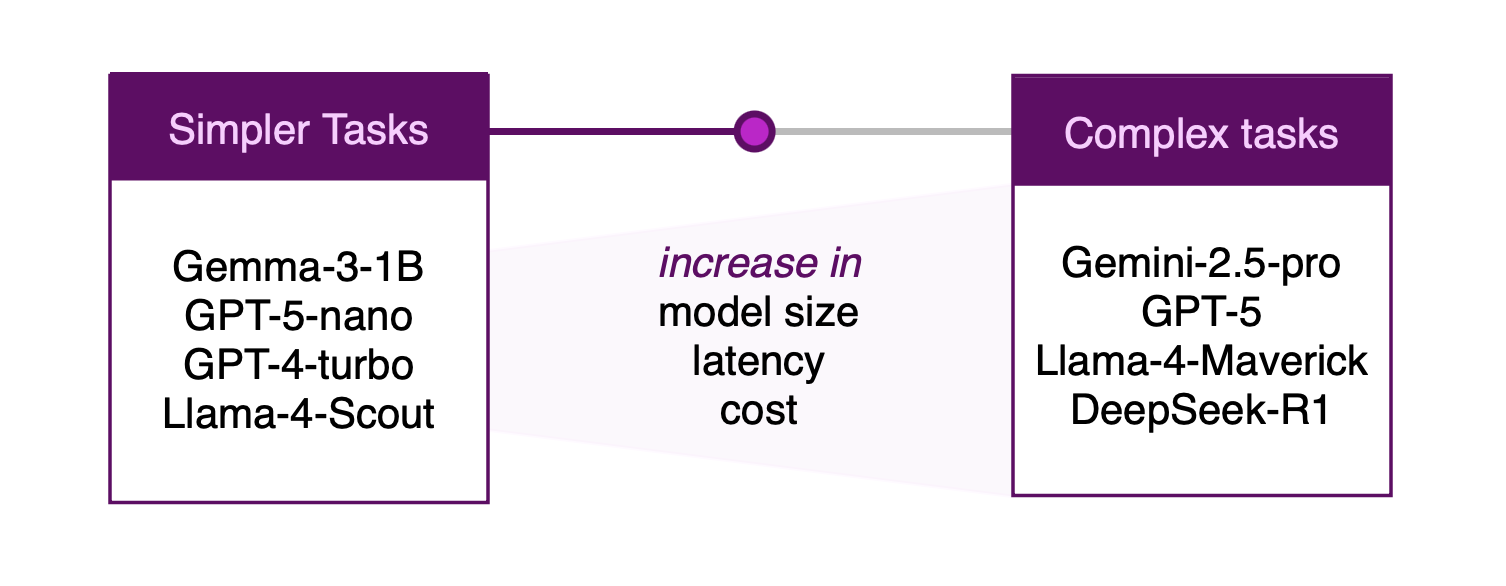
Fazit: Wägen Sie kleinere gegen größere Modelle ab. Beginnen Sie mit dem kleinsten Modell, das Ihre Vorgaben bei realen Proben zuverlässig erfüllt. Erhöhen Sie die Kapazität nur, wenn die gemessene Leistung oder die Sicherheitsanforderungen die zusätzliche Kapazität eindeutig rechtfertigen. Ziehen Sie abgestufte Ansätze in Betracht (z.B. die Weiterleitung leichter Fälle an ein kleines Modell, schwierigerer Fälle an ein größeres Modell), um ein Gleichgewicht zwischen Qualität und Effizienz herzustellen.
Fazit
Die Entwicklung effektiver LLM-gestützter Anwendungen erfordert mehr als den bloßen Aufruf einer API; sie erfordert:
-
Nutzung von Argumentationsmodellen und Anpassung ihres "Deliberationsbudgets" an die Komplexität der Aufgabe.
-
Entwurf strukturierter Ausgaben, die die Modelle dazu anleiten, klare Argumente und genaue Antworten zu liefern.
-
Anwendung von modellspezifischen Prompt-Engineering-Praktiken und iterative Verfeinerung von Prompts.
-
Verwenden Sie A/B-Tests, um Eingabeaufforderungen, Parameter und Modellauswahlen unter realen Bedingungen zu validieren.
-
Auswahl des richtigen Modells durch Abwägen von Aufgabenkomplexität, Kosteneffizienz und Nachhaltigkeit.
LLMs sind leistungsstarke Werkzeuge, aber ihr volles Potenzial entfaltet sich nur, wenn sie mit einem durchdachten Design, sorgfältigem Prompt-Engineering und einer strategischen Modellauswahl gepaart sind. Indem sie sich auf Argumentation, Struktur und Bewertung konzentrieren, können Entwickler Anwendungen erstellen, die nicht nur genau und zuverlässig, sondern auch effizient und skalierbar sind. Der Schlüssel dazu ist, klein anzufangen und kontinuierlich zu experimentieren.
Wenn Sie mehr erfahren möchten, besuchen Sie unsere Kurse: Einführung in die generative KI für Grundlagen und Prompt-Engineering, und Building LLM Applications für fortgeschrittene Themen.
Verfasst von

Mahdi Massahi
Machine Learning Engineer
Contact