
Aufbau einer Datenpipeline mit einem modernen Datenstapel
Eine moderne Datenpipeline, das klingt schick, finden Sie nicht auch? Wenn dieser moderne Datenstapel ein neuer Begriff ist, lesen Sie bitte den ausgezeichneten Blog von Guillermo Sánchez Dionis unter Modern Data Stack The road to democratizing data .
Kürzlich haben wir bei GoDataDriven ein Code-Frühstück veranstaltet, um morgens ein paar Denkanstöße zu geben. Wir haben gezeigt, wie man eine Pipeline mit dem modernen Data Stack aufbaut.
Der Zweck der Pipeline, die wir aufbauen, ist es, alle Metadaten aus der GoDataDriven Github-Organisation zu erhalten. Wir möchten diese Daten regelmäßig abrufen, um die Nutzung zu analysieren und zu sehen, ob wir irgendwelche Trends erkennen können. Zum Beispiel, wer am Wochenende arbeitet, indem wir die Zeitstempel der Commits analysieren.
Wir folgen hier dem Prinzip des Extract Load Transform (ELT). Das macht es einfach, die Teile in der Pipeline zu segmentieren:
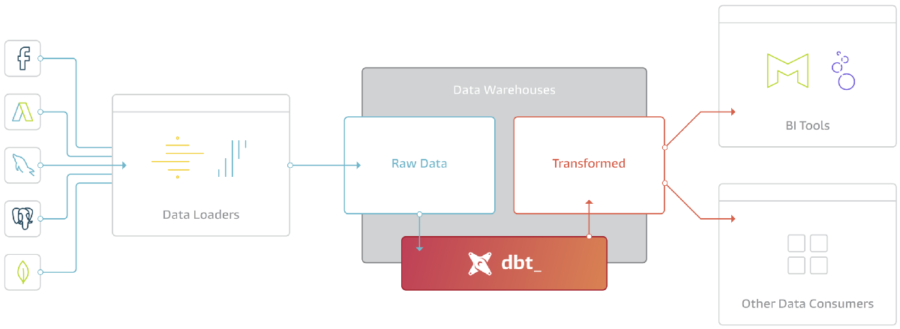
Auf der linken Seite sehen wir den Data Loader, d.h. den Prozess oder Dienst, der die Daten aus einer externen Quelle in das Data Warehouse lädt. Das Data Warehouse stellt den Schritt des Ladens dar. Es folgen die Transformationen mit dbt, bei denen wir die Daten schneiden und würfeln, um die Informationen zu destillieren, die wir für datengestützte Entscheidungen benötigen.
Auszug
Für den Extrakt-Teil wollen wir die Github-API abfragen, um alle Daten zu erhalten, die wir benötigen. Wir könnten eine Python-Anwendung schreiben, die dies für uns erledigt, die Anwendung in Docker verpacken und sie jede Nacht mit Apache Airflow planen.
Das hört sich nach einem unterhaltsamen Projekt an, und wahrscheinlich ist es das auch. Aber es wird einige Zeit in Anspruch nehmen, um das Ganze zum Laufen zu bringen. Wir müssen die Anwendung selbst schreiben, die Überwachung und Benachrichtigung einrichten. Wir müssen dafür sorgen, dass wir mit Sonderfällen umgehen können, z. B. wenn ein neues Feld in der API von Github hinzugefügt wird. Letztendlich kann dies eine ganze Weile dauern.
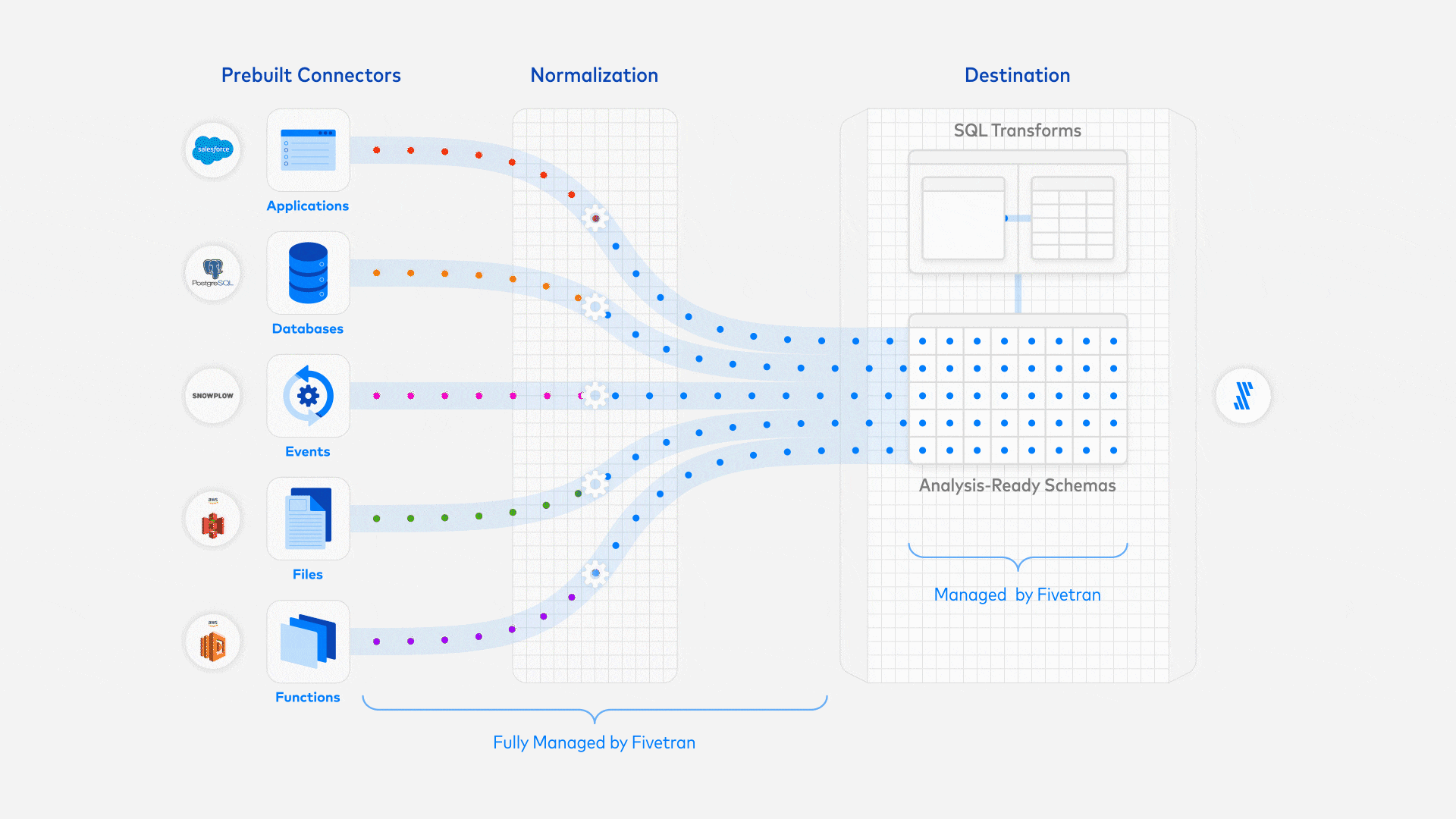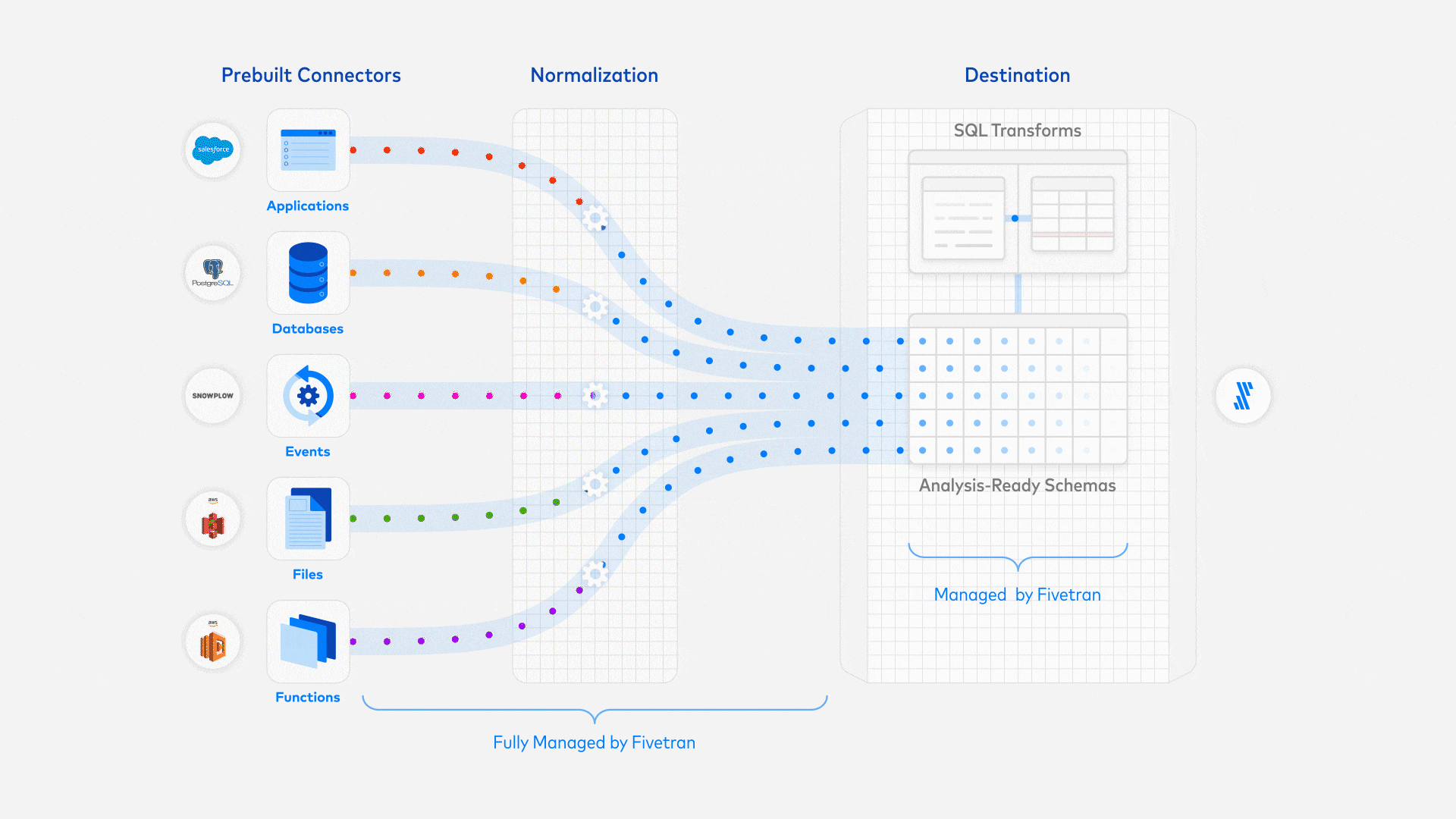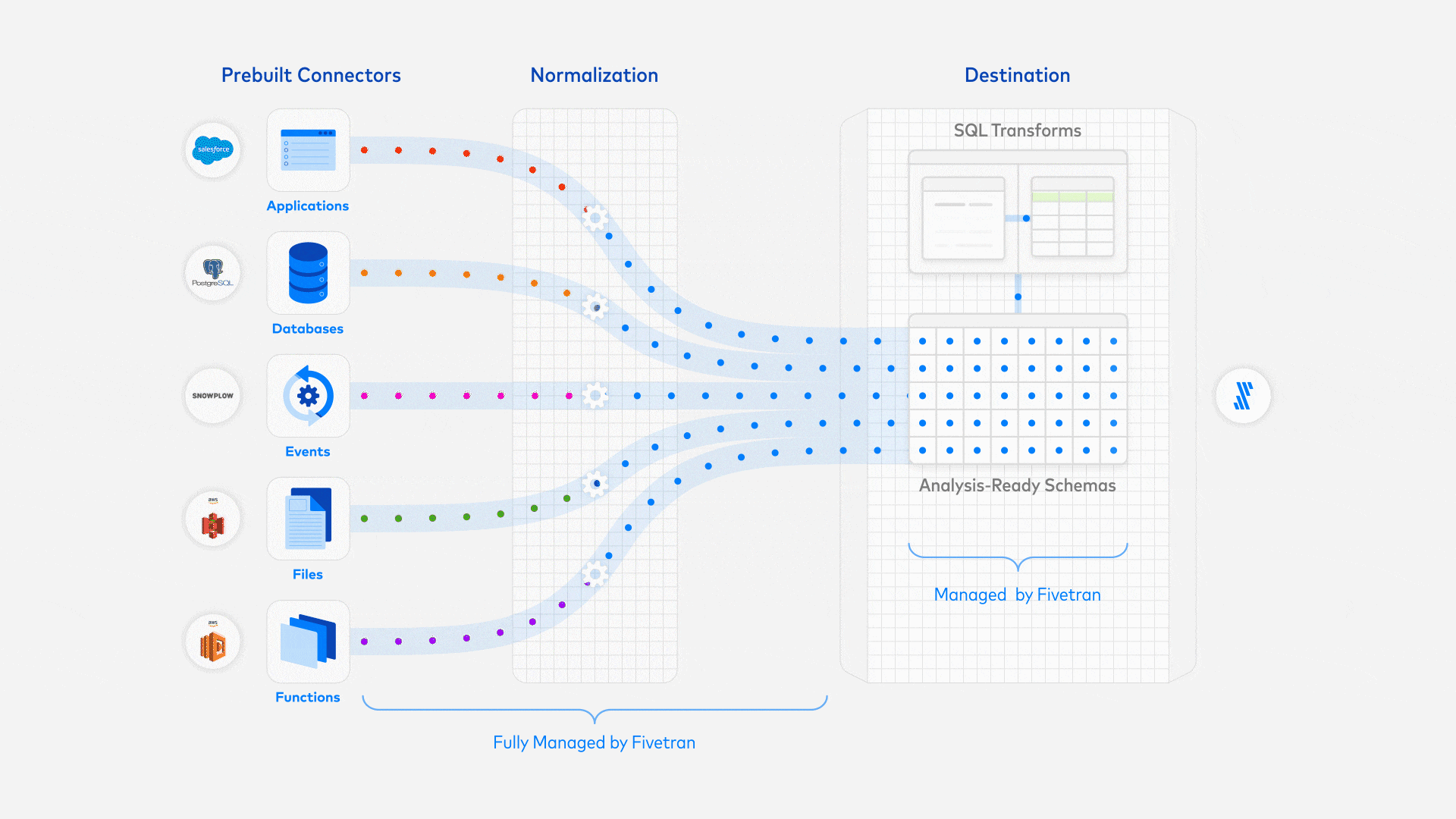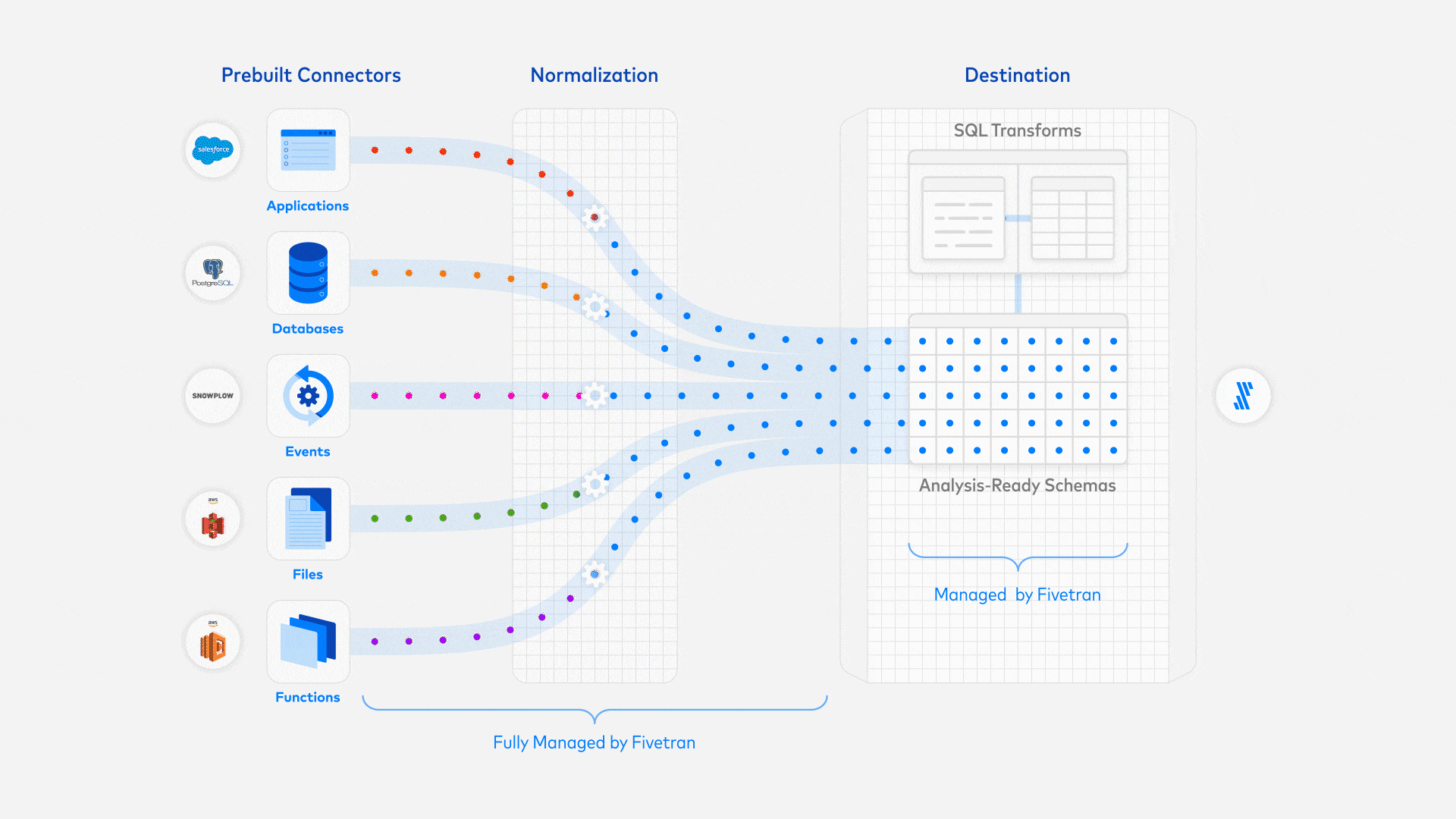
Für die moderne Datenpipeline nutzen wir stattdessen Fivetran, um die Daten automatisch von Github in BigQuery zu importieren. Dies erfordert nur wenig technisches Wissen und ist in wenigen Minuten statt in Tagen eingerichtet. Sie konfigurieren Fivetran über sein Portal und der größte Teil der Arbeit besteht darin, die Authentifizierung zwischen den verschiedenen Diensten einzurichten. Hervorzuheben ist, dass die Daten nicht transformiert werden, sondern dass dies alles in die Transformationsschicht verlagert wird. Voraussetzungen für den Übergang zur Produktion wie die Überwachung sind standardmäßig eingerichtet. Außerdem zahlen Sie, wie bei vielen
Was ich sehr wichtig finde, ist, dass Sie alle Daten in die Plattform einspeisen. Das erhöht zwar die Kosten ein wenig, weil Sie Daten laden, die Sie nicht nutzen, aber es trägt zu dem übergeordneten Ziel der Demokratisierung von Daten bei. Wenn die Daten nicht vorhanden sind, werden sie mit Sicherheit nicht genutzt, und es gibt eine Barriere, um nach den Daten zu fragen.
Die verfügbaren Konnektoren finden Sie in unserem Verzeichnis der Konnektoren. Andernfalls können Sie einen eigenen Konnektor implementieren und dabei die Funktionen von Fivetran wie Überwachung und Schemaentwicklung nutzen.
Laden Sie
Wir laden alle Daten in ein Cloud Warehouse, in unserem Fall BigQuery auf Google Cloud. BigQuery ist ein verwaltetes Cloud Data Warehouse, das tabellarische Daten unterstützt. Es ist hochgradig skalierbar, und Sie müssen den zugrunde liegenden Speicher oder die Rechenleistung nicht verwalten.
Eine Gemeinsamkeit von verwalteten Data Warehouses ist, dass sie von Haus aus mit einer Vielzahl von Funktionen ausgestattet sind. Zum Beispiel:
- Unterstützung für
DELETE, um dem Recht auf Vergessenwerden von Nutzern zu entsprechen. Das klingt trivial, war aber aufgrund der unveränderlichen Natur des zugrunde liegenden Speichers traditionell nicht einfach zu bewerkstelligen. - Die Möglichkeit, Zeilen- und Spaltenmaskierungen vorzunehmen. Auch dies ist etwas, das in herkömmlichen Hadoop-basierten Systemen nicht einfach zu implementieren wäre, da die Spalten physisch zusammen in einem einzigen Containerformat gespeichert würden.
Auch bei BigQuery zahlen Sie pro Nutzung, d.h. Sie zahlen nicht, wenn der Cluster im Leerlauf ist oder ähnliches. Wenn Sie jedoch ein Power-User sind, könnte es interessant sein, zum Pauschalgebührenmodell zu wechseln.
Transformieren
Wir haben alle Rohdaten in BigQuery und möchten diese Daten in leicht verdauliche Tabellen zerlegen, die von vielen Abteilungen in Ihrem Unternehmen genutzt werden können. Hier kommt in der Regel das Data Build Tool (dbt) ins Spiel.
Ich glaube, dass dbt ein sehr leistungsfähiges Tool ist. In der Vergangenheit wurde die Analyse mit einer Art GUI durchgeführt, die moderne Praktiken wie DevOps nicht unterstützt. dbt implementiert ein Data Ops, bei dem wir mit Hilfe von Best Practices wie Datentests und integrierter Dokumentation in Richtung Datenqualität iterieren können. Es ist wichtig, dass die Dokumentation direkt neben dem Code liegt, denn wenn die Pipeline erweitert wird, muss auch die Dokumentation aktualisiert werden. So wird sichergestellt, dass die Dokumentation immer auf dem neuesten Stand ist und nicht in einem anderen System liegt.
Unten sehen wir, wie dbt die Abhängigkeiten modelliert. Durch das Schreiben von Sql in Verbindung mit Python Jinja2 Templating können Sie einen Abhängigkeitsgraphen zwischen Sql-Dateien erstellen. Alle diese Dateien zusammen bilden einen vollständigen Graphen, der von dbt ausgeführt wird. So können Sie ganz einfach neue Quellen hinzufügen und sie in die bestehenden Pipelines integrieren.
dbt ist in seiner Arbeitsweise eigenwillig, und ich persönlich halte das für eine gute Sache, wenn Sie möglicherweise mit vielen verschiedenen Leuten an derselben Codebasis arbeiten müssen. dbt ist nur SQL, und Sie können Metadaten wie Einschränkungen oder Dokumentation mit yaml und Markdown hinzufügen.
Während Sie Ihre Pipeline schrittweise verbessern, können Sie mit vielen Leuten zusammenarbeiten, indem Sie Pull Requests verwenden und sicherstellen, dass die Pipeline vom Team verstanden wird und dass Sie auf derselben Seite stehen.
In der Demo verwenden wir dbt, um einige Statistiken aus den Github-Daten zu berechnen, die wir in BigQuery gespeichert haben.
Video
Sehen Sie sich das Video an, in dem Misja Pronk die gesamte Pipeline durchgeht. Lehnen Sie sich zurück und genießen Sie, oder noch besser, programmieren Sie mit!
Sie benötigen ein paar Voraussetzungen:
Die Schritte sind auch auf Github zu finden: code_breakfast_tutorial
Wenn Sie auf Probleme stoßen, öffnen Sie bitte ein Issue auf Github, damit wir sehen können, was los ist. Wenn Sie der Meinung sind, dass dies etwas ist, das Sie in Ihrem Unternehmen einführen möchten, melden Sie sich bitte.




Contact