Blog
Automatisieren Sie den Schutz sensibler Daten mit Metadaten-gesteuerter Maskierung

Data Access Management ist schwierig
Eine der Hauptaufgaben eines Datenexperten ist der verantwortungsvolle Umgang mit Daten. Wenn Sie Zugang zu Daten erhalten und sie anderen zur Nutzung zur Verfügung stellen, müssen Sie sicherstellen, dass Sie wissen, um welche Daten es sich handelt und für welche verschiedenen Zwecke sie verwendet werden können bzw. nicht verwendet werden können. Folglich möchten Sie die Kontrolle darüber haben, wer auf Ihre Daten zugreifen kann und wer nicht.
Ohne einen klaren und einfachen Prozess kann die Verwaltung des Datenzugriffs jedoch sowohl unübersichtlich als auch mühsam werden, insbesondere wenn viele manuelle Schritte erforderlich sind. Irgendwann kann es sich sogar so anfühlen, als ob der Versuch, die Kontrolle zu behalten, Sie davon ablenkt, bei Ihrer Arbeit erfolgreich zu sein.
In diesem Blogbeitrag möchten wir Ihnen von unseren jüngsten Bemühungen berichten, metadatengestützte Datenmaskierung auf eine Art und Weise durchzuführen, die skalierbar, konsistent und reproduzierbar ist. Mit dbt zur Definition und Dokumentation von Datenklassifizierungen und Databricks zur Durchsetzung der dynamischen Maskierung stellen wir sicher, dass der Zugriff automatisch auf der Grundlage von Metadaten gesteuert wird. Solange Sie Ihre Datenklassifizierungen korrekt angeben, wird der Datenzugriff automatisch gewährt.
Lassen Sie uns ein Beispiel nehmen
Angenommen, Ihre Daten sind in zwei Kategorien unterteilt: persönliche und nicht-persönliche Daten. Und dass einige Personen in Ihrem Unternehmen diese persönlichen Daten einsehen dürfen, während andere dies nicht dürfen.
Und nehmen wir an, Sie haben eine Mitarbeitertabelle, die wie folgt aussieht:
| mitarbeiter_id | erster_name | jährliches_einkommen | team_name |
|---|---|---|---|
| 1 | Marta | 123.456 | Daten-Ingenieure |
| 2 | Tim | 98.765 | Daten-Analysten |
Sie können den Zugriff auf diese Tabelle auf verschiedene Arten ermöglichen. In verschiedenen Szenarien könnten Sie:
- überhaupt keinen Zugang gewähren,
- nur Zugriff auf einige Spalten gewähren (z.B. die nicht-persönlichen Spalten)
- nur Zugriff auf einige Zeilen gewähren (z.B. nur die Daten für ein Team)
- nur Zugriff auf einige Spalten und Zeilen gewähren
- Zugang zu allen Daten bieten
In diesem Blog konzentrieren wir uns auf eine Möglichkeit, den Zugriff auf diese Tabelle mit Hilfe von dbt-Metadaten in Kombination mit Databricks Unity Catalog automatisch zu verwalten.
Der Einfachheit halber werden wir uns auf die Unterscheidung zwischen Szenario 2 und 5 konzentrieren. Diese Methode kann jedoch auch auf die anderen Szenarien ausgeweitet werden.
In unserem Beispiel möchten wir, dass einige Personen (in der Gruppe can_handle_personal_data) die gesamte Tabelle nutzen können. Während Personen, die nicht zu dieser Gruppe gehören, nur die nicht-personenbezogenen Daten sehen können. Wenn sie die Tabelle abfragen, soll sie wie folgt aussehen:
| mitarbeiter_id | erster_name | jährliches_einkommen | team_name |
|---|---|---|---|
| 1 | NULL | NULL | Daten Ingenieure |
| 2 | NULL | NULL | Daten-Analysten |
Optionen
Wenn es darum geht, diese Art des Datenzugriffs in unserem Databricks- und dbt-Setup zu implementieren, gibt es zwei primäre Ansätze, die wir in Betracht ziehen können:
1. Aufteilung der Daten in "maskierte" und "unmaskierte" Schemata
Ein gängiger Ansatz ist die Erstellung separater Schemata innerhalb Ihrer Datenplattform: "maskierte" Schemas und "unmaskierte" Schemas. In diesem Fall verwalten Sie den Zugriff effektiv, indem Sie die Datensätze in zwei Versionen aufteilen: eine mit normalen, unmaskierten Daten und eine andere, in der alle sensiblen Daten maskiert sind. Durch diese Trennung können Sie festlegen, dass nur Benutzer mit höheren Zugriffsrechten die unmaskierten Daten einsehen können, während andere (normale) Benutzer mit den maskierten Daten interagieren.
- Vorteile: Diese Methode bietet eine einfache Möglichkeit, den Zugriff zu kontrollieren und ermöglicht eine klare Unterscheidung zwischen Daten, auf die frei zugegriffen werden kann, und solchen, die nicht frei zugänglich sind.
- Beschränkungen: Während die Aufteilung von Daten in maskierte und unmaskierte Bereiche für einfache Fälle funktioniert, ist es schwer, auf Situationen zu skalieren, die eine granularere Maskierung erfordern, bei der eine einfache maskierte/unmaskierte Aufteilung nicht ausreichend ist. In solchen Fällen sind weitere Verfeinerungen oder zusätzliche Datenbanken erforderlich, was die Datenverwaltung erschwert. Außerdem können sich die Speicher- und Rechenkosten erhöhen, da Sie Ihre Daten erneut verarbeiten und für jeden "Split" separate Kopien aufbewahren müssen.
2. Dynamische Maskierung verwenden
Eine flexiblere Lösung ist die Verwendung einer dynamischen Datenmaskierung, um zu steuern, welche Daten jeder Benutzer oder jede Benutzergruppe auf der Grundlage ihrer Zugriffsstufe sehen kann. Bei diesem Ansatz werden die Maskierungsfunktionen on-the-fly angewendet und der Datensatz entsprechend den Berechtigungen des Betrachters geändert. So kann ein und derselbe Datensatz je nach Zugriffsstufe des Benutzers unterschiedlich dargestellt werden.
- Vorteile: Die dynamische Maskierung bietet mehr Flexibilität und macht es einfacher, mehr Aufteilungen als nur maskiert-unmaskiert einzuführen und zu handhaben und diese konsistent anzuwenden. Sie senkt die Speicher- und Rechenkosten, da die Notwendigkeit mehrerer Versionen derselben Daten entfällt. Alle Benutzer können dieselben Daten nutzen, sehen aber je nach Zugriffsebene unterschiedliche Versionen.
- Beschränkungen: Die dynamische Maskierung kann als etwas weniger eindeutig empfunden werden. Der Name Ihres Schemas wird keinen Hinweis wie "maskiert" enthalten. Sie müssen die Tabellendefinitionen (oder einen Katalog) überprüfen, um zu sehen, welche Spalten maskiert sind und wie. Benutzer, die nur auf maskierte Daten zugreifen können, werden sich daran gewöhnen müssen.
Metadatengesteuerte dynamische Maskierung
In diesem Blog stellen wir Ihnen eine Lösung vor, bei der die automatische Datenmaskierung auf der Grundlage eines genau definierten Klassifizierungssystems implementiert wird. Die Lösung besteht aus drei Hauptschritten:
- Vereinbaren Sie eine Datenklassifizierung: Der erste Schritt besteht darin, ein klares Klassifizierungssystem für Ihre Daten zu definieren, das festlegt, welche Daten maskiert werden sollen. Diese Vereinbarung legt den Grundstein für einen konsistenten Umgang mit sensiblen Informationen in Ihrem gesamten Team und sollte idealerweise auf Unternehmensebene standardisiert werden.
- Klassifizieren Sie Ihre Daten: Wenn das Klassifizierungssystem eingerichtet ist, wenden wir es systematisch auf alle relevanten Spalten in unseren Datensätzen an. Indem wir die Datenklassifizierung und den Datentyp in dbt YAML-Dateien dokumentieren, schaffen wir ein versionskontrolliertes, zentrales Repository von Metadaten, das unsere Maskierungsstrategie steuert, insbesondere durch die Verwendung der dbt Dokumentationsfunktionen.
- Maskierung der Funktionsgenerierung: Wir erstellen SQL-Funktionen in Databricks getrennt von deren Anwendung. Diese Trennung von Funktionserstellung und Anwendung sorgt für Flexibilität, Sicherheit und minimale manuelle Eingriffe.
- Automatische Anwendung der Maskierung auf Ihre Daten: Schließlich implementieren wir eine automatische Datenmaskierung mit einer Kombination aus Databricks SQL-Funktionen und dbt-Post-Hooks. Die Maskierungsfunktionen werden in dbt dynamisch auf der Grundlage der dokumentierten Klassifizierungen angewendet.
1. Einigen Sie sich auf Arten der Datenklassifizierung
Der erste Schritt bei der Implementierung besteht darin, sich darauf zu einigen, welche Daten maskiert werden müssen. Dazu gehört die Einrichtung eines Klassifizierungssystems, mit dem das gesamte Team zwischen Daten, die für jedermann zugänglich sind, und Daten, die einem breiteren Publikum vorenthalten werden sollten, unterscheiden kann. Wenn Sie mit personenbezogenen Daten umgehen, ist die GDPR-Klassifizierung ein gängiger Rahmen, um klare Zugriffsgrenzen zu definieren. In unserem Beispiel werden wir eine vereinfachte Klassifizierung mit zwei Kategorien verwenden: non-personal und personal Daten. Natürlich sollten wir die personenbezogenen Daten maskieren. Es ist wichtig, von Anfang an einen flexiblen Klassifizierungsrahmen zu entwerfen, der zukünftige Erweiterungen zulässt. Wenn neue Datenquellen integriert werden oder sich die geschäftlichen Anforderungen ändern, müssen Sie möglicherweise neue Kategorien hinzufügen oder bestehende verfeinern. Unsere Beispielklassifizierung kann z.B. durch die Einführung einer Kategorie sensitive-personal oder das Hinzufügen einer zweiten Klassifizierungsebene für geschäftliche Sensibilität erweitert werden.
Hier sind wieder unsere Beispieldaten, jetzt mit den Klassifizierungen:
| employee_id (nicht-personal) | vor_name (persönlich) | Jahreseinkommen (persönlich) | team_name (nicht-personenbezogen) |
|---|---|---|---|
| 1 | Marta | 123.456 | Daten-Ingenieure |
| 2 | Tim | 98.765 | Daten-Analysten |
2. Klassifizieren Sie alle Ihre Daten
Es gibt mehrere Möglichkeiten, die für die Maskierung erforderlichen Metadaten - GDPR-Klasse und Datentyp - zu speichern. Die wichtigste Voraussetzung ist, dass die Daten überall dort zugänglich sein müssen, wo die Maskierung angewendet wird. Beispielsweise können Tags in Data Warehouses als zusätzliche Metadatenattribute verwendet werden, oder Sie können einen Datenkatalog zum Speichern von Metadaten verwenden. Alternativ können diese Metadaten auch in separaten Dateien in einem zentralen Repository für eine einzige Quelle der Wahrheit gespeichert werden.
In unserem Setup verwenden wir dbt und die YAML-Dokumentation von dbt, die einen zuverlässigen, versionskontrollierten Ort für die Speicherung der für die Maskierung erforderlichen Metadatenklassen bietet. YAML ist für diesen Anwendungsfall besonders gut geeignet, da es sowohl maschinenlesbar als auch für Menschen lesbar ist. Anhand der Beispieltabelle von oben dokumentieren wir sie wie folgt:
models:
- name: data_masking_example
description: Dummy data to show data masking
columns:
- name: employee_id
data_type: int
description: Data identifier
meta:
gdpr_class: Non-Personal
primary_key: Y
tests:
- not_null
- unique
- name: first_name
data_type: string
description: First name of employee
meta:
gdpr_class: Non-Personal
primary_key: N
- name: yearly_income
data_type: string
description: Yearly income of employee
meta:
gdpr_class: Personal
primary_key: N
- name: team_name
data_type: string
description: Name of team employee is part
meta:
gdpr_class: Personal
primary_key: N
Bei großen dbt-Projekten oder mehreren Projekten kann die Pflege der Dokumentation eine Herausforderung sein. Obwohl es in der Verantwortung jedes Entwicklers liegt, die Dokumentation nach jeder Änderung zu aktualisieren, kann es schwierig sein, dies durchzusetzen. Hier sind einige Tools, die dabei helfen können:
- dbt-osmosis: Dieses Tool unterstützt die automatische Generierung von Dokumentation durch Vererbung von Metadaten aus anderen Modellen. Es kann den Dokumentationsprozess erheblich rationalisieren, indem es Listen von Spalten und Datentypen generiert, was nützlich ist, um die Pflege der Dokumentation im Laufe der Zeit zu minimieren.
- dbt-bouncer: Dieses Tool erzwingt die Einhaltung der erforderlichen Dokumentationsfelder und stellt sicher, dass die Benutzer die festgelegten Dokumentationsstandards einhalten.
Beachten Sie, dass Sie, wenn Ihr Unternehmen ein Datenkatalog-Tool erwirbt, die Metadaten, die Sie in Ihrem dbt-Projekt zu sammeln begonnen haben, dazu verwenden können, den Datenkatalog mit wertvollen Metadaten zu füllen.
3. Maskierungsfunktionen erstellen
Um Sicherheit und Kontrolle zu gewährleisten, haben wir die Erstellung der Maskierungsfunktionen von ihrer Anwendung getrennt. Wir stellen sicher, dass Benutzer, die die Maskierungsfunktionen anwenden, diese nicht ändern können. Tatsächlich stellen wir sicher, dass niemand die Maskierungsfunktionen ändern kann, ohne einen Überprüfungsprozess zu durchlaufen.
Das folgende Python-Skript durchläuft die Kombinationen von GDPR-Klassen und Datentypen in unserer Konfiguration und erstellt für jede eine Maskierungsfunktion. Beachten Sie, dass wir für jeden Datentyp eine eigene Funktion benötigen, da die maskierten Daten denselben Typ haben sollten wie die Originaldaten, um Typinkongruenzen zu vermeiden. Für jede Funktion prüfen wir, welche Benutzergruppen Zugriff auf unmaskierte Daten haben sollten, und geben andernfalls NULL zurück.
Beachten Sie, dass wir keine Maskierungsfunktionen für die Klasse "nicht-personal" erstellen müssen, da diese Daten nicht maskiert werden müssen.
# simplified examples of the config
data_types = ["string", "int"]
gdpr_classes = ["personal"]
# mapping of the GDPR levels per access groups
access_groups = {"can_handle_personal_data": ["personal"]}
for data_type in data_types:
for gdpr_class in gdpr_classes:
print(f"Creating masking function for {data_type}, {gdpr_class}")
# Get the access group which has access to the data
gdpr_specific_groups = [
group_name
for group_name, gdpr_classes in access_groups.items()
if gdpr_class in gdpr_classes
]
groups = " OR ".join([f"is_account_group_member('{group}')" for group in gdpr_specific_groups])
# Create the function name by combining data type and the GDPR class
function_name = f"mask_{data_type}_{gdpr_class}"
sql_query = f"""
CREATE OR REPLACE FUNCTION {function_name}(val { data_type })
RETURN
CASE WHEN { groups } THEN val ELSE cast(null as { data_type })
END
"""
spark.sql(sql_query)
Jede Iteration im Python-Skript erzeugt eine SQL-Funktion innerhalb eines bestimmten Schemas. Um eine nahtlose Funktionalität zu gewährleisten, ist es wichtig, dass alle Entwickler und Stellen in allen relevanten Umgebungen "USE"-Zugriff auf diese Funktionen haben. Die Funktionsnamen sind eine Kombination aus dem Datentyp und der GDPR-Klasse und sie werden später in dbt unter Verwendung derselben Namenskonvention referenziert. Daher ist die Beibehaltung einer klaren und konsistenten Benennungsstrategie von entscheidender Bedeutung.
In unserer Implementierung ersetzt die Maskierungsfunktion die Werte durch NULL. Es gibt jedoch auch andere Ansätze, die Sie in Betracht ziehen können, z.B. das Hashing von Strings, das Binning numerischer Werte oder die Verwendung von Platzhalterdaten. Das folgende Beispiel zeigt eine Funktion, die Integer-Werte mit persönlichen Daten maskiert und Benutzern, die nicht zur Gruppe can_handle_personal_data gehören, NULL anzeigt.
CREATE OR REPLACE FUNCTION mask_int_personal(val int)
RETURN
CASE WHEN is_account_group_member('can_handle_personal_data')
THEN val
ELSE cast(null as int)
END;
Ein letzter Hinweis zur Funktionserstellung: Stellen Sie sicher, dass die Worker oder Serviceprinzipale, die automatisierte Aufträge ausführen, Zugriff auf unmaskierte Daten haben. Das bedeutet, dass sie in die Gruppe aufgenommen werden müssen, die den unmaskierten Zugriff auf die Daten erlaubt.
4. Maskierungsfunktionen anwenden
Die Anwendung der Maskierungsfunktion ist absichtlich von ihrer Erzeugung getrennt. Die Masken werden mit einem Post-Hook auf die Daten in dbt angewendet, den wir in der Datei dbt_project.yml so konfiguriert haben, dass er für alle Modelle gilt. Indem Sie diese Funktion direkt unter models einstellen, wird sie universell ausgeführt, unabhängig vom Modellpfad.
models:
+post-hook:
- "{{ dbt_macros.apply_masking_to_model(this) }}"
In unserem Fall haben wir das folgende Makro für die Anwendung der Maskierungsfunktionen erstellt:
{% macro apply_masking_to_model(model) %}
{# Apply dynamic masking function to a model. We assume the model is materialized as a table to be able to re-create the table each time. #}
{% if execute %}
{{ log("Model: " ~ model) }}
{# Get the model equal for which this post-hook is executed #}
{% for node in graph.nodes.values() | selectattr("resource_type", "equalto", "model") | selectattr("name", "equalto", model.table) | selectattr("schema", "equalto", model.schema) %}
{# Iterate over each column and apply masking function to each #}
{% for column_name, column in node["columns"].items() %}
{# Extract metadata from documentation #}
{% set data_type = column_data["data_type"] %}
{% set gdpr_class = column_data.get("meta", {}).get("gdpr_class", "sensitive-personal") %}
{# Generate function names #}
{% set function_name = "mask_" ~ data_type ~ "_" ~ gdpr_class %}
{# Apply function #}
{% set apply_masking_code -%}
ALTER TABLE {{ model }} ALTER COLUMN {{ column_data["name"] }} SET MASK {{ function_name }}
{%- endset %}
{% do run_query(apply_masking_code) %}
{% endfor %}
{% endfor %}
{%endif%}
{%- endmacro %}
In dem Makro nutzen wir die Knoten des dbt-Graphen, um die für die Maskierung benötigten Felder zu extrahieren. Mit graph.nodes.values() können wir über alle Knoten im Graphen iterieren. Um bestimmte Knoten effizient zu finden, verwenden wir selectattr, um den Graphen bis zum gewünschten Knoten zu filtern. Sobald das richtige Modell ausgewählt ist, fahren wir mit den Operationen für jede Spalte fort und extrahieren die GDPR-Klasse und den Datentyp aus dem Diagrammknoten.
Die GDPR-Klasse ist optional. Wenn ein Benutzer die GDPR-Klasse nicht angibt, verwenden wir zur Sicherheit die restriktivste Klasse, um sicherzustellen, dass die Daten geschützt sind, auch wenn die Dokumentation unvollständig ist. Der Datentyp ist jedoch ein Pflichtfeld und muss für alle Spalten angegeben und auf dem neuesten Stand gehalten werden. Anhand dieser beiden Werte generieren wir den entsprechenden Namen der Maskierungsfunktion und wenden ihn auf jede Spalte im Modell an. Nachfolgend finden Sie ein Beispiel für den SQL-Code, der von diesem Makro angewendet wird:
ALTER TABLE masking.example.test_masking_table ALTER COLUMN yearly_income SET MASK USING mask_int_personal;
In unserem Beispiel wird die ALTER TABLE-Anweisung für jede Spalte des Modells ausgeführt. Wenn Sie mit Modellen arbeiten, die eine große Anzahl von Spalten enthalten, sollten Sie ALTER TABLE-Anweisungen gruppieren, um die Ausführungsgeschwindigkeit zu optimieren.
Nachdem Sie die Maskierung auf jede Spalte angewendet haben, können Sie die Ergebnisse in Databricks validieren. Jede Tabelle sollte die neue spaltenspezifische Maskierungsfunktion widerspiegeln, wie im folgenden Beispiel zu sehen:
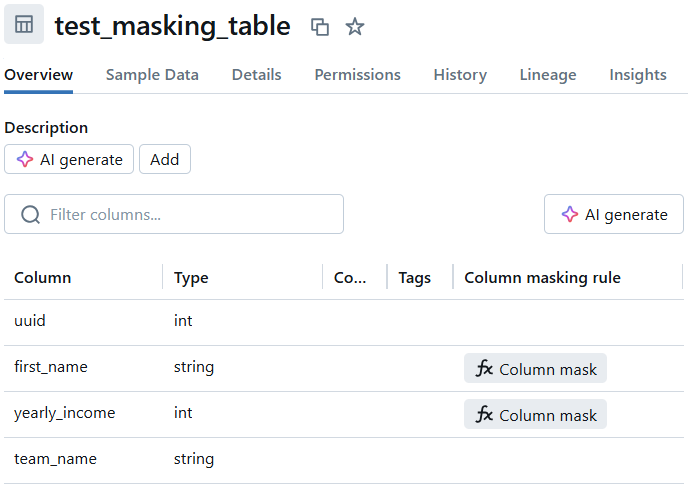
Eine SELECT * FROM example_table sollte dann die angewandte Maskierung widerspiegeln, wobei die persönlichen Spalten nicht mehr zu sehen sein sollten, wie zuvor vorgeschlagen:
| mitarbeiter_id | erster_name | jährliches_einkommen | team_name |
|---|---|---|---|
| 1 | NULL | NULL | Daten Ingenieure |
| 2 | NULL | NULL | Daten-Analysten |
Für Benutzer in der Gruppe can_handle_personal_data sollte das Ergebnis der gleichen Abfrage wie folgt aussehen:
| mitarbeiter_id | erster_name | jährliches_einkommen | team_name |
|---|---|---|---|
| 1 | Marta | 123.456 | Daten-Ingenieure |
| 2 | Tim | 98.765 | Daten-Analysten |
Beschränkungen
Obwohl unsere Lösung für die automatische Datenmaskierung eine flexible und skalierbare Möglichkeit zur Verwaltung sensibler Daten bietet, gibt es einige Einschränkungen und Verbesserungsmöglichkeiten. Diese sind zwar nicht (alle) nur bei der von uns gewählten Implementierung gegeben, aber wir möchten hier einige davon aufführen:
Leistungseinbußen im dbt
Für eine effektive Maskierung muss jedes Modell sofort nach seiner Erstellung auf persönliche Daten überprüft werden. Jedes Mal, wenn eine Maskierungsfunktion angewendet wird, muss eine ALTER TABLE SQL-Anweisung ausgeführt werden. Im Databricks SQL-Dialekt können diese Anweisungen nicht kombiniert werden, d.h. jeder Maskierungsvorgang wird separat ausgeführt. Dies kann sehr zeitaufwändig sein, insbesondere wenn Sie mit einer großen Anzahl sensibler Spalten arbeiten. Um dies zu vermeiden, müssen Sie sorgfältig abwägen, welche Spalten wirklich maskiert werden müssen und unnötige Maskierungen vermeiden, um langwierige Aufgaben zu vermeiden. Außerdem sollten wir versuchen, die ALTER-Anweisungen zu vermeiden, indem wir MASK Klauseln in die CREATE TABLE Anweisungen einfügen (hier beschrieben).
Entwicklung bei maskierten Daten
Die Arbeit mit maskierten Daten kann für Entwickler Probleme mit sich bringen. Das Testen von Implementierungen oder die Analyse der Daten kann problematisch sein, wenn der Entwickler keinen Zugriff auf die unmaskierte Version hat. Ein ähnliches Problem kann bei der Durchführung von Operationen wie JOINauftreten, bei denen maskierte Daten möglicherweise durch Null oder Platzhalter wie *** ersetzt werden. Dieses Problem betrifft nicht nur unseren Ansatz, es ist ein allgemeines Problem bei der Arbeit mit maskierten Daten. Eine bewährte Methode ist es, Entwicklern die Arbeit mit "sicheren" oder synthetischen Datensätzen zu ermöglichen, bei denen eine Maskierung nicht erforderlich ist. Indem wir diese Quellen eindeutig als sicher für die Entwicklung kennzeichnen, können wir die Notwendigkeit der Maskierung in diesen Umgebungen verringern.
Fehlklassifizierung von Daten
Wenn das Projekt wächst und neue Datensätze hinzugefügt werden, können sich die Anwendungsfälle und Datenanforderungen ändern. Angesichts der Performance-Kosten von Maskierungsvorgängen ist es wichtig, die Klassifizierung von Datensätzen regelmäßig zu überprüfen, um die Genauigkeit sicherzustellen. Dies ist besonders wichtig, wenn es sich um personenbezogene Daten handelt, da die Klassifizierung möglicherweise aktualisiert werden muss, um den sich ändernden Vorschriften zu entsprechen. Regelmäßige Audits und Überprüfungen können dazu beitragen, dass Daten korrekt klassifiziert werden und dass die Maskierung angemessen angewendet wird.
Ausdehnung auf weitere Materialisierungen
Der obige Ansatz funktioniert problemlos für jede dbt-Materialisierung, die zu einer Tabelle führt, aber nicht für Views. Das liegt daran, dass Views nicht die gleichen MASK Klauseln unterstützen. Um die Unterstützung für Views hinzuzufügen, wäre ein anderer Ansatz erforderlich.
Technische Beschränkungen der dynamischen Maskierung
Es gibt immer noch einige Einschränkungen bei der Anwendung der dynamischen Maskierung und bei der Verwendung von Datensätzen mit dynamischer Maskierung. Diese sind hier aufgelistet und Beispiele umfassen die Art des Compute-Clusters, den Sie verwenden können.
Verfasst von
Marta Radziszewska
Data Engineer




Contact