Blog
Wie man mit LLMs strukturierte Daten aus unstrukturiertem Text extrahiert

In der heutigen Welt streben immer mehr Unternehmen nach einer datengesteuerten Entscheidungsfindung. Sie stehen jedoch häufig vor der Herausforderung, wertvolle Erkenntnisse aus unstrukturierten Textdaten zu gewinnen, z. B. aus Kundenrezensionen oder Feedback.
Dieser Beitrag richtet sich an Datenwissenschaftler, Analysten und Entscheidungsträger, die unstrukturierte Daten nutzen möchten, um nützliche Erkenntnisse zu gewinnen. Wir untersuchen einen Batch-Anwendungsfall für Large Language Models (LLMs) und konzentrieren uns dabei auf die Umwandlung von unstrukturiertem Text in strukturierte Daten. Mit Hilfe dieses Ansatzes können Unternehmen ihre Datenbanken mit strukturierten Informationen anreichern und ihr Verständnis für unstrukturierte Datenquellen verbessern. Um diese Art von Anwendungsfall zu veranschaulichen, werden wir uns mit dem Beispiel der Analyse von Kundenfeedback beschäftigen.
Dieses Repository bietet Ihnen eine allgemeine Einrichtung, die Ihnen den Einstieg in diese Art von LLM-Batch-Anwendung ermöglicht.
Anwendungsfall: Kundenfeedback
Nehmen wir das Beispiel der Kundenrezensionen auf einer Webseite, die sich auf ein bestimmtes Produkt bezieht.

Möglicherweise liegen uns einige strukturierte Informationen vor, wie z.B. die Anzahl der Sterne, die jeder Kunde vergibt. Vielleicht möchten wir aber auch spezifischere Informationen. Zum Beispiel: Warum hat ein Kunde eine hohe oder niedrige Bewertung abgegeben? Um das herauszufinden, müssten wir diese Bewertungen selbst lesen und filtern. Bei Hunderten von Bewertungen für Tausende von Produkten ist dies ein undurchführbarer Prozess.
Ideal wäre es, wenn wir für jedes Thema Bewertungen sehen könnten, z. B. für Qualität, Versand, Preis usw. Dies hat zwei Vorteile:
- Wir wären dann besser in der Lage zu erkennen, was wir verbessern können.
- Wir würden Kunden helfen, bessere Entscheidungen beim Kauf eines Produkts zu treffen.
In der Abbildung unten sehen Sie eine solche Übersicht der Bewertungen pro Thema.
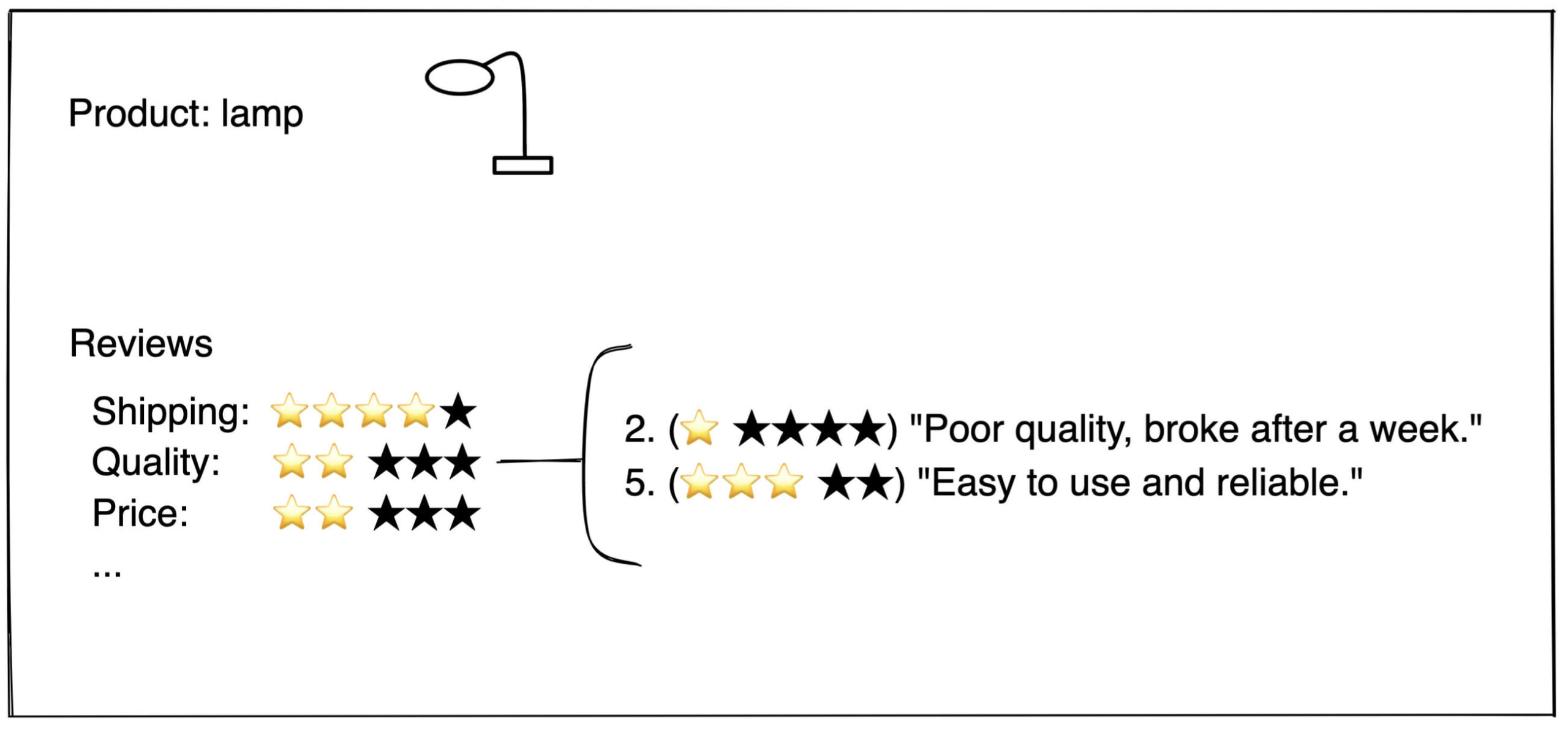
Einem aufmerksamen Auge wird auffallen, dass wir die Bewertungen aller Rezensionen, die ein bestimmtes Thema erwähnen, mitteln. Das funktioniert nicht so gut, wenn wir eine Bewertung erhalten, in der mehrere Themen erwähnt werden: "Tolle Qualität, schlechter Versand". In diesem Fall könnten wir fälschlicherweise der Qualität eine niedrige oder dem Versand eine hohe Bewertung zuweisen. Um unser Beispiel jedoch einfach zu halten, ignorieren wir diese Art von Bewertungen vorerst.
Sie fragen sich vielleicht, warum Sie den Kunden nicht direkt zu jedem dieser Themen Feedback geben lassen? Nun, in diesem Fall wird der Bewertungsprozess noch komplexer. Das kann dazu führen, dass der Kunde überhaupt keine Bewertung abgibt.
Wie machen wir das also? Wir brauchen eine skalierbare Methode, um strukturierte Informationen, d.h. das Thema, aus dem unstrukturierten Text, d.h. der Rezension, zu extrahieren.
Das könnte Sie auch interessieren: Cloud-Schulungen | Daten & KI-Schulungen
Extrahieren Sie strukturierte Informationen mit Hilfe eines LLM
In diesem Beispiel verwenden wir einen LLM wegen seiner Flexibilität und Benutzerfreundlichkeit. Er ermöglicht es uns, die Aufgabe zu erledigen, ohne ein Modell zu trainieren. Beachten Sie aber, dass für sehr strukturierte Ausgaben auch ein einfaches Klassifizierungsmodell trainiert werden könnte, sobald genügend Proben gesammelt wurden.
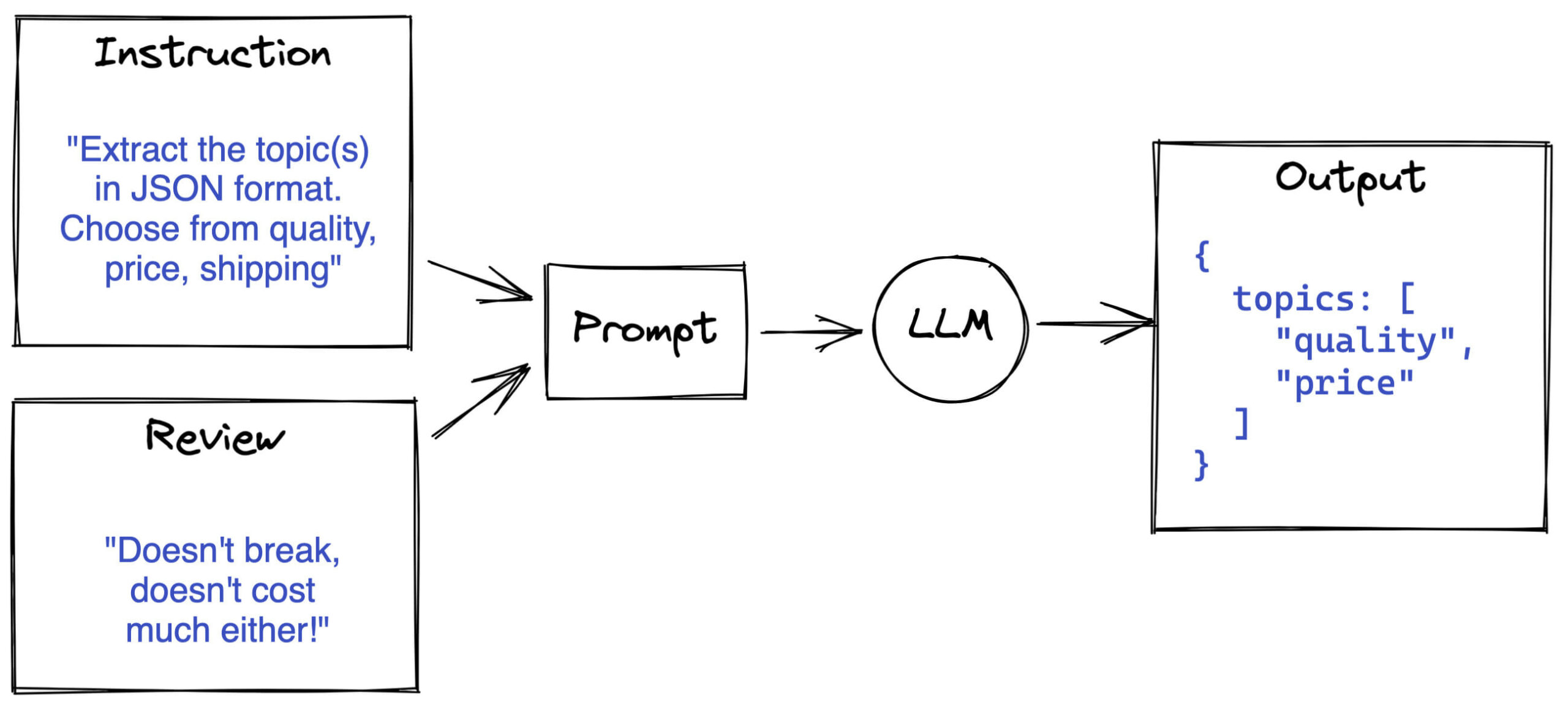
Wir können den folgenden Ansatz wählen:
- Erstellen Sie eine clevere Eingabeaufforderung
- Geben Sie den unstrukturierten Text an einen LLM
- Rufen Sie die strukturierte Ausgabe aus dem LLM ab
- (Speichern Sie sie in einer Datenbank)
Wir versuchen, den LLM zur Ausgabe von gültigem JSON zu zwingen, da wir rohes JSON leicht als Objekt in Python laden können. Wir können zum Beispiel ein Pydantic BaseModel definieren und es zur Validierung der Modellausgaben verwenden. Darüber hinaus können wir seine Definition verwenden, um dem Modell sofort die richtigen Formatierungsanweisungen zu geben. Wenn Sie mehr darüber erfahren möchten, wie Sie ein LLM für strukturierte Ausgaben erzwingen können, lesen Sie unseren früheren Blogbeitrag.
Unser Pydantic BaseModel würde etwa so aussehen:
from typing import List, Literal
from pydantic import BaseModel, Field
class DesiredOutput(BaseModel):
topics: List[
Literal[
"quality",
"price",
"shipping",
]
] = Field("Topic(s) in the input text")
Es kann jedoch sein, dass das Modell nicht gleich beim ersten Mal richtig liegt. Wir können dem Modell ein paar Versuche geben, indem wir die Validierungsfehler in die Eingabeaufforderung zurückführen. Ein solcher Ansatz kann als ein Algorithmus vom Typ Las Vegas betrachtet werden. Der Ablauf sieht dann so aus:
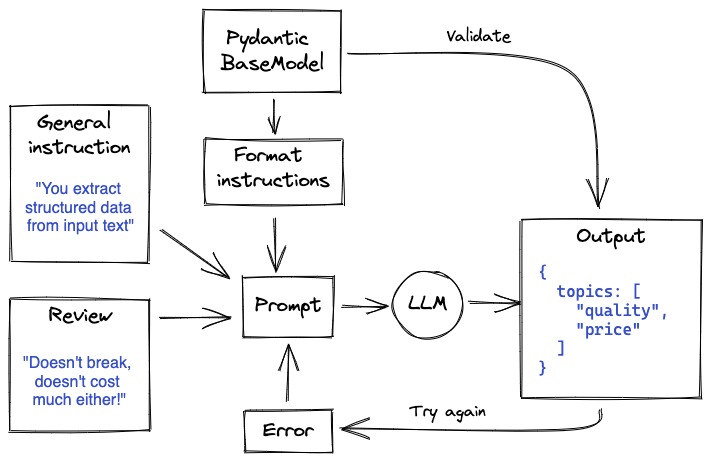
Das war's! Zumindest für die Grundlagen. Wir können dies erweitern, indem wir zum Beispiel ein allgemeines benutzerdefiniertes Schema zulassen, das dann in ein Pydantic BaseModel geparst werden kann. 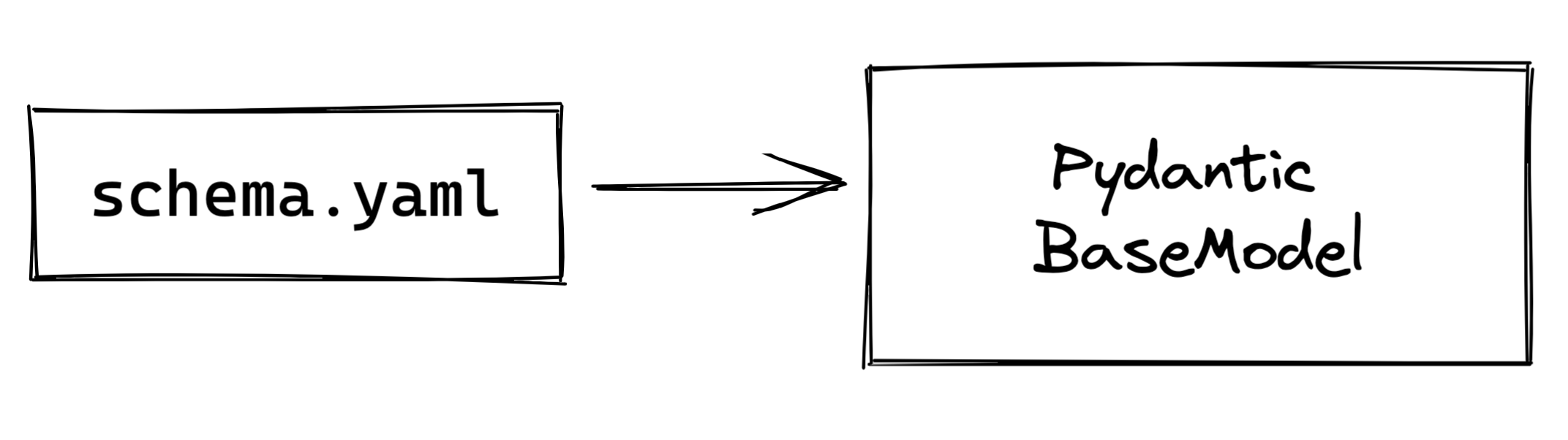
Strukturierung als Stapelverarbeitung
In einem letzten Schritt trennen wir unsere Logik von unseren Ein- und Ausgaben, damit wir diese Operationen problemlos auf neue Datenstapel anwenden können. 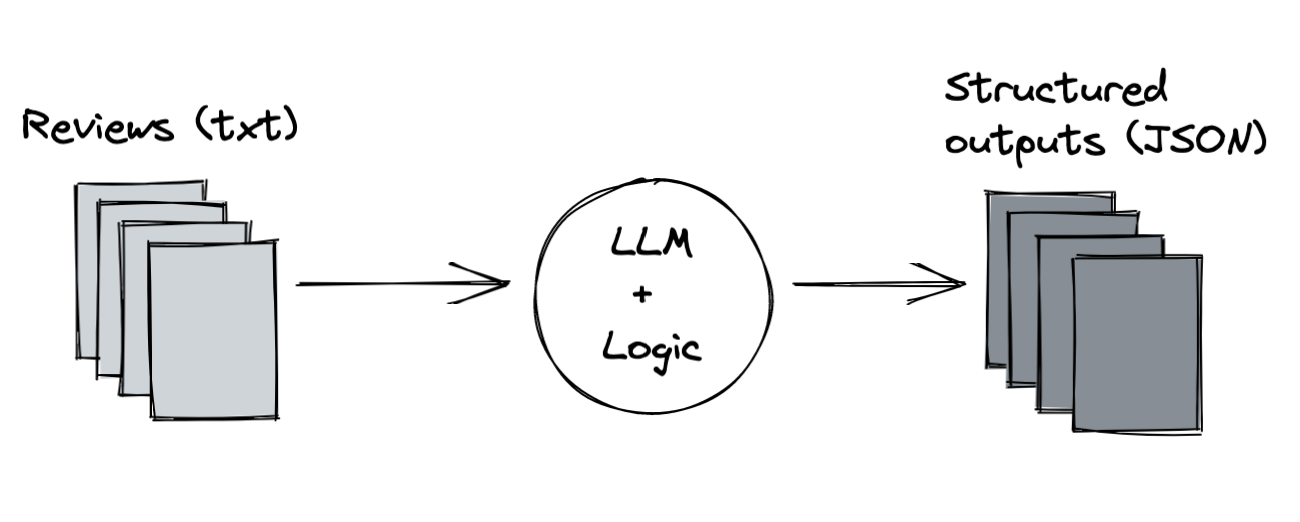 Wir können dies tun, indem wir den Speicherort für die Eingabebewertungen und den Ausgabeort für die JSON-Dateien parametrisieren. Wir verwenden diese, um die Bewertungen zu laden und die Ausgabedateien zu speichern, wenn wir unseren Batch ausführen.
Wir können dies tun, indem wir den Speicherort für die Eingabebewertungen und den Ausgabeort für die JSON-Dateien parametrisieren. Wir verwenden diese, um die Bewertungen zu laden und die Ausgabedateien zu speichern, wenn wir unseren Batch ausführen.
Wenn wir unseren Batch-Job ausführen, fordern wir den LLM (unter Verwendung der im vorherigen Abschnitt beschriebenen Logik) einmal pro Überprüfung auf. Die Überprüfung selbst kann dynamisch in unsere Eingabeaufforderung eingefügt werden, indem wir eine Eingabeaufforderungsvorlage verwenden, die hier im Quellcode-Repository implementiert wurde.
Anschließend können wir die ausgegebenen JSONs verwenden, wie wir wollen. Sie sollten alle Informationen enthalten, die wir in unserem BaseModel angegeben haben. Im Beispiel der Kundenrezensionen können wir die Rezensionen jetzt ganz einfach mit den verfügbaren strukturierten Informationen nach Themen gruppieren.
Nachdem wir dies lokal zum Laufen gebracht haben, müssen wir nur noch dafür sorgen, dass dieser Batch-Vorgang auf einem Server für ein bestimmtes Zeitintervall ausgeführt wird. Aber das lassen wir in diesem Beitrag außen vor.
Verallgemeinerung der Lösung
Die obige Lösung ist bereits auf viele Anwendungsfälle anwendbar, bei denen wir strukturierte Informationen aus unstrukturierten Eingabedaten extrahieren möchten. Um die Lösung noch weiter zu verallgemeinern, können wir die Funktionalität jedoch auch für die Verarbeitung von PDF-Dokumenten hinzufügen, da diese oft der Ausgangspunkt für textbezogene Anwendungsfälle sind.
Im Großen und Ganzen lautet die Lösung dann ungefähr so:
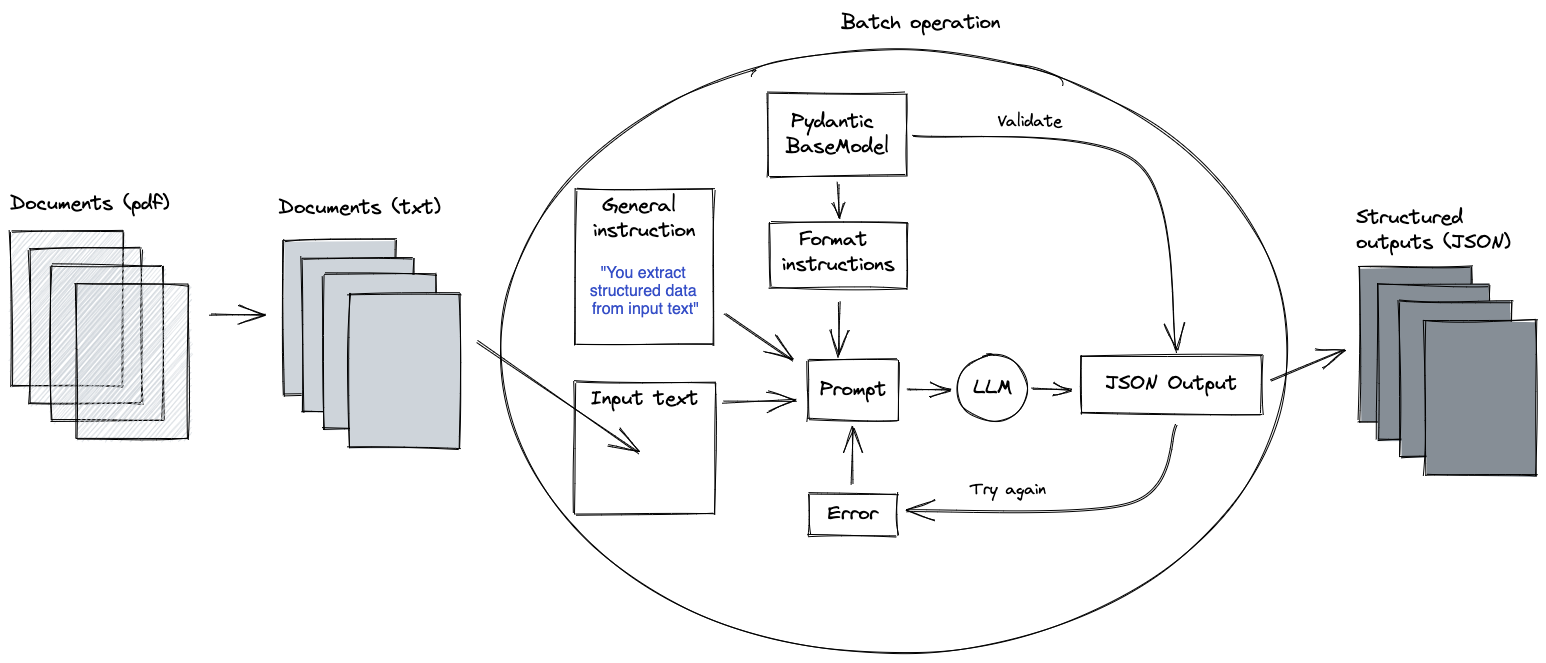
Im Quell-Repository sind wir von dem einfachen Fall ausgegangen, dass die Dokumente klein genug sind, um auf einmal durch einen LLM zu laufen. In einigen Fällen erstrecken sich die PDFs jedoch über Dutzende von Seiten. Die Eingabe wird dann zu groß für einen LLM, und es muss eine zusätzliche Verarbeitung implementiert werden.
Fazit
In diesem Blogbeitrag haben wir einen typischen Batch-Anwendungsfall für LLMs untersucht und uns dabei auf die Extraktion strukturierter Daten aus unstrukturiertem Text konzentriert. Wir haben diesen Ansatz anhand des Beispiels der Analyse von Kundenfeedback demonstriert. Durch den Einsatz eines LLM und einer gut durchdachten Prompting-Strategie können wir unstrukturierte Textdaten effizient in strukturierte Informationen umwandeln. Mit diesen Informationen können wir dann unsere Datenbanken anreichern und eine bessere Entscheidungsfindung ermöglichen.
Das bereitgestellte Repository zeigt diese Art von Anwendungsfall in seiner Grundform und kann leicht an Ihre spezifischen Bedürfnisse angepasst werden. Wir ermutigen Sie, es mit Ihren eigenen Daten auszuprobieren und die Möglichkeiten der Nutzung von LLMs zur Gewinnung wertvoller Erkenntnisse aus unstrukturiertem Text zu erkunden.
Foto von Brett Jordan auf Unsplash
Verfasst von
Yke Rusticus




Contact