Übersicht
KI/ML sind heute für Unternehmen unverzichtbar, um ihren Kunden einen Mehrwert zu bieten, die Entscheidungsfindung zu optimieren und einen klaren Wettbewerbsvorteil zu erzielen. Da die Fortschritte in der KI/ML-Technologie immer verfügbarer und nutzbarer werden, ist es offensichtlich, dass die Unternehmen diese für sich selbst schneller nutzen müssen.
Heute kann KI/ML in fast jedem Bereich, den wir uns vorstellen können, dazu beitragen, einige der unlösbaren Probleme zu lösen, die früher nicht gelöst werden konnten. Mit dem Aufkommen von Frameworks und Bibliotheken für maschinelles Lernen ist es einfacher als früher, KI/ML-Lösungen zu entwickeln.
Angesichts dieser Fortschritte erkennen Unternehmen und ihre Stakeholder, dass sie sich KI/ML zu eigen machen müssen. Die Bedeutung erfolgreicher KI/ML-Ergebnisse wird ein Unternehmen in die nächste Wachstumsphase katapultieren oder sogar neue Geschäftszweige schaffen. Aber selbst wenn Unternehmen mehr Ressourcen in KI/ML-Projekte investieren, erzielen die Führungskräfte nicht die erwartete Rendite. Die Realität hat den Hype um dieses Thema nicht eingeholt.
Der Grund dafür ist eine nicht gerade ideale KI/ML-Arbeitslast, bei der die Beteiligten mit vielen unzusammenhängenden Tools arbeiten. Sie müssen sich mit Aufgaben der Datenverwaltung, der Infrastruktur, der Konfiguration, dem Mangel an erstklassigem technischen Support und vor allem mit der Operationalisierung der Ergebnisse auseinandersetzen, um einen geschäftlichen Nutzen zu erzielen.
Infolgedessen beginnen die meisten KI/ML-Projekte mit großem Tamtam (da es sich häufig um eine Initiative der obersten Führungsebene handelt) und versanden dann auf dem Weg durch die Ränge. Bis die Unternehmen dies bemerken, ist das Budget bereits für die Einstellung teurer Ressourcen, für eine kostspielige Infrastruktur und für die Entwicklung zusammenhangloser und unzusammenhängender Artefakte ausgegeben worden, ohne dass ein brauchbares Ergebnis für die Bereitstellung eines End-to-End-Geschäftswerts erzielt wurde.
Warum scheitern KI/ML-Projekte?
Die meisten KI/ML-Projekte scheitern an drei Hauptursachen: Reproduzierbarkeit, Anwendbarkeit und Skalierbarkeit
Reproduzierbarkeit
Im Allgemeinen sammeln Datenwissenschaftler Daten und arbeiten in einer Umgebung, die sich auf ihren lokalen Rechnern befindet, oder auf Code-Notebooks (offline oder online). Da in der KI/ML das Experimentieren ein Bürger erster Klasse ist, beginnt seine Reise als Ideen und Code, die unstrukturiert zusammengestellt werden. Das hat zur Folge, dass sie nicht reproduzierbar, wiederholbar oder skalierbar sind. Die Ergebnisse haben
keine Garantie für Verlässlichkeit und sind stochastischer Natur. Selbst wenn in der Experimentierphase außergewöhnliche Ergebnisse erzielt werden, ist das System nicht in einem Zustand, in dem es von den Geschäftsbereichen genutzt werden kann.
Nutzbarkeit
Die meisten KI/ML-Workloads können nicht von einer einzelnen Person erledigt werden. Sie bestehen aus vielen Teilen. Jeder hat andere Fähigkeiten und Erfahrungsanforderungen. Man kann die Arbeit eines vorgelagerten Teams (z.B. Datenkuratoren) nicht durch nachgelagerte Teams (z.B. Datenwissenschaftler, Feature-Analysten usw.) nutzen. Es sind nicht nur unterschiedliche Fähigkeiten im Spiel, sondern sie sind auch nicht miteinander verbunden. In Verbindung mit der inhärenten Nicht-Reproduzierbarkeit verschärft dies das Problem der Nutzbarkeit nur noch mehr.
Skalierbarkeit
Wenn wir die beiden oben genannten Fehlerursachen erfolgreich beseitigt haben, stellt sich das Problem der Skalierung der Ausgabe, um die Kunden in großem Umfang zu bedienen. Wenn in der Regel alles in der Entwicklung und im Staging funktioniert, heißt das schon eine Menge. Aber wenn wir zu Szenarien auf Produktionsebene kommen, scheitert es, da es die Grenzen der Skalierbarkeit erreicht, die für tatsächliche Geschäftsszenarien erforderlich sind.
Neben den drei oben genannten Hauptursachen gibt es sieben weitere Probleme, die die Operationalisierung von KI/ML-Workloads behindern.
- Wie verteilen Sie die Arbeitslast auf die Teams?
- Wie können die Ergebnisse der einzelnen Teams (vor- und nachgelagert) integriert werden?
- Sicherheit für jedes Arbeitsobjekt. So sollte z.B. ein einzigartiger Algorithmus oder eine ML-Architektur, die verwendet wurde, für niemanden im Unternehmen zugänglich sein.
- Einfaches Heraufstufen von lokal > Entwicklung > Testen > Staging > Produktion
- Metriken zum Fortschritt der Entwicklung
- Versionierung von Modellartefakten, so dass wir zu einer bestimmten Version zurückkehren können.
- Leichte Integration mit Geschäftsbereichen, die keine Erfahrung mit KI/ML haben
Warum brauchen wir angewandte KI?
Eine typische KI/ML-Arbeitslast besteht aus den folgenden Hauptkomponenten: Daten, Feature Engineering, Modelltraining und -generierung, Model Serving und eine Anwendung, die die Vorhersagen zur Erzielung eines Geschäftswerts nutzt.
Jede der Hauptkomponenten kann weiter untergliedert werden:
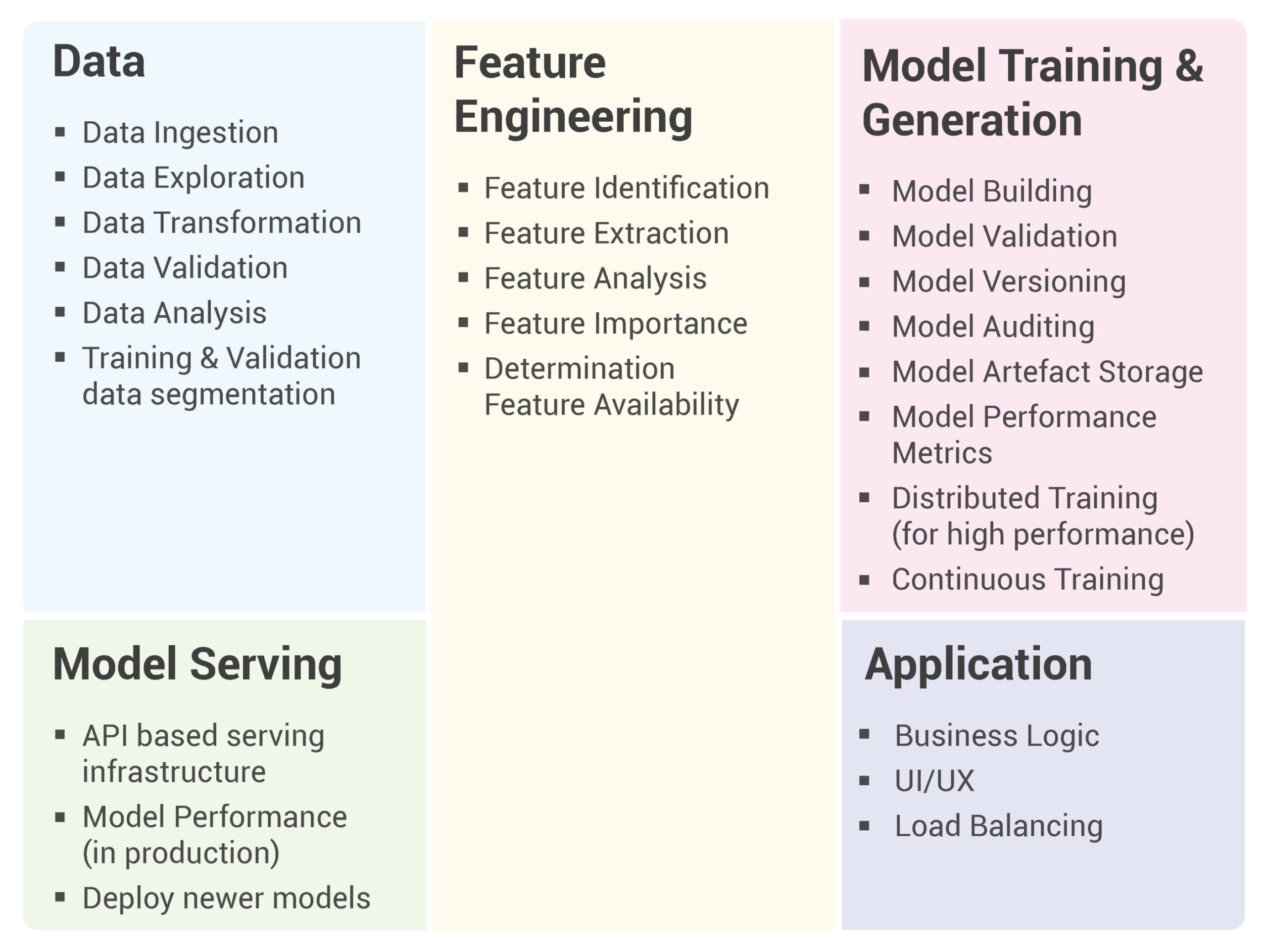
Wie Sie sehen, gibt es eine Vielzahl von Aufgaben, die einzeln und gemeinsam ausgeführt werden müssen, um ein erfolgreiches KI/ML-Projekt zu ermöglichen. In der Regel wird jede dieser Aufgaben von einem anderen Team mit unterschiedlichen Fähigkeiten und Erfahrungen ausgeführt.
Außerdem konzentrieren sich die meisten aktuellen KI/ML-Workload-Planungen nur auf das Training, die Validierung und die Generierung von Modellen. Der Rest der Komponenten ist ein nachträglicher Gedanke oder wird bestenfalls ad-hoc implementiert, was weder reproduzierbar, nutzbar noch skalierbar ist.
Wahrnehmung vs. Realität
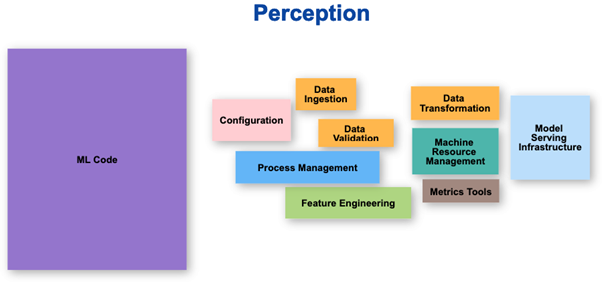
Der Teil, auf den sich das ML-Team konzentriert, macht bestenfalls 10 % der gesamten Arbeit aus, die auf strukturierte Weise erledigt werden muss. Die Wahrnehmung ist, dass der größte Teil der Arbeit ML-Code ist, aber die Realität sieht ganz anders aus.
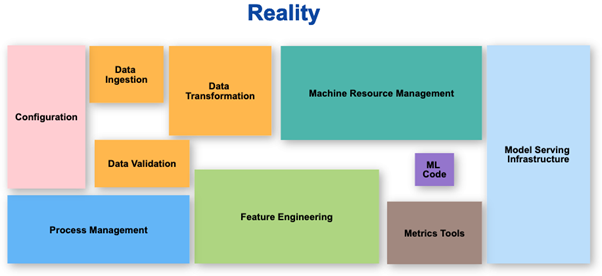
Angewandte KI wird benötigt, um reale KI/ML-Workloads von Anfang bis Ende zu entwickeln, zu verwalten, einzusetzen und anzupassen.
Was ist angewandte KI?
Angewandte KI ist ein Rahmenwerk mit einer Reihe kompatibler Tools und Artefakte, die es ermöglichen, KI/ML-Workloads vom Experimentieren bis hin zu Anwendungen auf Produktionsebene zu operationalisieren. Es zielt darauf ab, die meisten der Probleme zu lösen, die zum Scheitern von KI/ML-Projekten führen.
Gegenwärtig schreiben wir KI/ML-Anwendungen und starten sie in der Cloud oder in einer On-Premise-Infrastruktur. Aber das fehlende Glied ist die ML-Plattform, die zwischen der Anwendung und der Infrastruktur vermittelt. Das Framework, das all diese drei Elemente miteinander verbindet und integriert, ist ein Applied AI Framework.
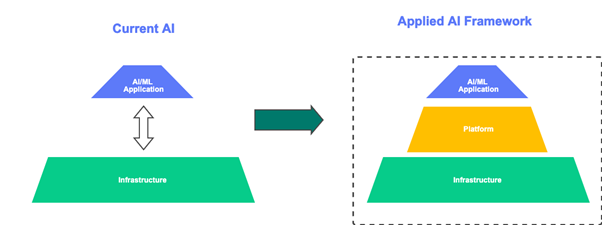
Ein grundlegender Bestandteil des Applied AI-Frameworks ist die Kompositionsfähigkeit von Komponenten unter Verwendung von Pipelines. Eine Pipeline kann (auch visuell) so konfiguriert werden, dass die Ausgabe von vorgelagerten Komponenten nahtlos als Eingabe für nachgelagerte Komponenten konfiguriert werden kann. Da die Kompositionsfähigkeit eingebaut ist, kann jede Komponente für mehrere KI/ML-Projekte wiederverwendet und kombiniert werden. Damit wird das Problem der Wiederverwendbarkeit gelöst, das bei der herkömmlichen Entwicklung von KI/ML-Projekten auftritt.
Ein weiteres wichtiges Merkmal ist die Möglichkeit, die Infrastrukturebene zu abstrahieren, so dass wir dieselbe Arbeitslast (mit minimalen Änderungen) auf den verschiedenen Cloud-Plattformen (AWS, Azure, GCP usw.) oder auf einer On-Premise-Infrastruktur oder einer Hybrid-Infrastruktur bereitstellen können. Dies trägt zur Skalierbarkeit bei und ermöglicht in Verbindung mit der Verwaltung der Infrastrukturressourcen eine hochleistungsfähige Anwendung. Die Möglichkeit, mehrere Experimente durchzuführen, Modellversionen zu erstellen, Audits durchzuführen und Modell-Metadaten zu erfassen, gewährleistet Reproduzierbarkeit und Rückverfolgung.
Wie macht man angewandte KI?
Nachdem wir nun wissen, warum und was Angewandte KI ist, können wir nun beschreiben, wie wir Angewandte KI implementieren wollen. Es gibt also einige vorbereitende Phasen (und Meilensteine), die abgeschlossen werden müssen.
Die erste Phase ist die Entdeckungs- und Definitionsphase . In dieser Phase gibt es 6 Meilensteine, die erreicht werden müssen: Projektstart, Datenlandschaft, Prozesse & Technologie, Business Use Cases, Skills Landscape und KI-Strategie.
Projekt-Auftakt
- Führen Sie Einzelgespräche mit wichtigen Interessenvertretern, um die Ziele von AI zu ermitteln.
- Bestimmen Sie einen oder mehrere Executive Sponsor(en).
- Bestimmen Sie eine Kontaktperson, die die Koordination mit den Sponsoren übernimmt.
- Schaffen Sie eine Kernarbeitsgruppe.
- Dokumentieren Sie die wichtigsten aktuellen Geschäftsanwendungen.
- Erstellen Sie eine KI-Vision und Ziele für den Geschäftswert.
Daten-Landschaft
- Dokumentieren Sie die aktuellen Datenquellen und das Format: strukturiert, unstrukturiert usw.
- Ermitteln Sie die aktuelle Verfügbarkeit und Qualität der Daten.
- Verstehen Sie die bestehenden Systeme zur Datenerfassung, -verteilung und -validierung.
- Identifizieren Sie die verschiedenen verfügbaren Datentypen, ihre Bedeutung, ihren Ort, ihren Ursprung und ihre Struktur.
- Bewerten Sie, wie die Daten gespeichert, analysiert, verarbeitet und geschützt werden.
- Überprüfen Sie alle bestehenden Richtlinien für Data Governance.
- Kuratieren Sie nützliche Datensätze für die mögliche Verwendung in KI/ML-Anwendungen.
Prozess & Technologie
- Dokumentieren Sie die aktuelle IT-Infrastruktur und -Landschaft im Hinblick auf KI/ML-Workloads.
- Lückenanalyse von Tools, Rahmenwerken und Ressourcen.
Business Use Cases
- AI Business Anwendungsfälle. Mindestens zwei 'Pilot'-KI-Projekte Definition.
- KI-Panels : Panels zu Wirtschaft, Technik und Ökosystem.
- Definieren und vereinbaren Sie KPIs zur Messung des AI-Projekterfolgs.
Landschaft der Fertigkeiten
- Identifizieren Sie die vorhandenen Fähigkeiten der derzeitigen Entwickler in Bezug auf KI/ML.
- Schulungsbedarf und Qualifizierungsstrategie.
- Einstellungsbedarf: Intern & Extern.
KI-Strategie
- KI-Adoptionsstrategie
- Definieren Sie die Schlüsselelemente und die Architektur eines Applied AI Frameworks.
- Definieren Sie die Einführungs-, Produkt- und Wachstumsstrategie für KI/ML aus der Unternehmensperspektive.
Die nächste Phase ist die Phase des Wertnachweises. In dieser Phase nehmen wir die Ergebnisse aus der Entdeckungs- und Definitionsphase (insbesondere in Bezug auf Daten, Anwendungsfälle, Ressourcen und Strategie) und erstellen
eine Liste mit priorisierten Initiativen, die dann den jeweiligen Teams zur Erfüllung zugewiesen werden können.
Das Herzstück eines jeden Frameworks für angewandte KI ist das Konzept der "Pipelines". Hier können wir verschiedene Aufgaben miteinander verknüpfen, um Kompositionsfähigkeit zu erreichen. Hier ist eine Liste von Frameworks, die
derzeit beliebt:
Apache Airflow :(airflow apache.org)
MLFlow :(mlflow.org)
Kubeflow :(kubeflow.org)
Von diesen drei sind MLFlow und Kubeflow spezialisierte Plattformen für den KI/ML-Lebenszyklus, während Airflow eher eine universelle Workflow-Plattform ist.
Sobald die Auswahl getroffen ist, sollte die Infrastruktur für die Einführung eines dieser Frameworks eingerichtet werden. Dann müssen die in der Entdeckungs- und Definitionsphase identifizierten Pilotprojekte implementiert werden. Durch die Durchführung von zwei Piloten im Gegensatz zu einem ist man gezwungen, eine Vielzahl von organisatorischen Szenarien in Bezug auf Ressourcenaufteilung, Sicherheit, Fachwissen usw. zu behandeln.
Zwar haben alle diese Tools und Frameworks unterschiedliche Schwerpunkte und Stärken, aber kein einziges wird Ihnen einen kopfschmerzfreien Prozess aus dem Ärmel schütteln. Bevor Sie sich für ein Tool entscheiden, sollten Sie sicherstellen, dass Sie über gute Prozesse verfügen. Dazu gehören eine gute Teamkultur, Retrospektiven ohne Schuldzuweisungen und langfristige Ziele.
Fazit
Zusammenfassend lässt sich sagen, dass ein direkter Start mit KI/ML-Anwendungen zum Scheitern verurteilt ist. Wir haben hier einen Prozess und eine Methodik beschrieben, die einen konsistenten Wert liefern und gleichzeitig die Komplexität bewältigen, die mit der Implementierung von KI/ML-Workloads in großem Umfang in Unternehmen einhergeht.
Verfasst von
Sai Panyam
Consulting Architect, cOMakeIT




Contact