Apache NiFi ist eine beliebte Big-Data-Verarbeitungs-Engine mit grafischer Web-UI, die Nicht-Programmierern die Möglichkeit bietet, Daten-Pipelines schnell und codelos zu erstellen und sie von den schmutzigen, textbasierten Methoden der Implementierung zu befreien. Dadurch wird NiFi zu einem weit verbreiteten Tool, das eine breite Palette von Funktionen bietet.
Wenn Sie mehr über den Einsatz von Apache NiFi in der Produktion aus der Sicht eines Entwicklers und über alle Kompromisse, die mit seiner Einfachheit einhergehen, lesen möchten, dann sollten Sie die Blog-Serie lesen:
Apache NiFi - warum lieben und hassen Dateningenieure es gleichzeitig?
Teil I - Schnelle Entwicklung, mühsame Pflege
Teil II - Wir haben bereitgestellt, aber zu welchem Preis... - CI/CD des NiFi-Flows
Teil III - Kein Programmieren, einfach ziehen und ablegen, was Sie brauchen, aber wenn es nicht da ist... - benutzerdefinierte Prozessoren, Skripte, externe Dienste
Teil IV - Ein Universum aus Flow-Dateien - NiFi-Architektur
Teil V - Es geht schnell und einfach, was kann da schon schiefgehen - ein Jahr Geschichte eines bestimmten NiFi-Flusses
Ich habe nur eine Regel und die lautet ... - Empfehlungen für die Verwendung von Apache NiFi
Warum Kubernetes?
Kubernetes ist ein Open-Source-System zur Verwaltung von containerisierten Anwendungen auf mehreren Hosts. Es wird immer beliebter, auch in der Big Data-Welt, da es heutzutage eine ausgereifte Lösung ist und für viele Benutzer interessant ist. Kubernetes ist nicht nur beliebt, sondern bietet auch die Möglichkeit einer schnelleren Bereitstellung der Ergebnisse und vereinfacht die Bereitstellung und Aktualisierung (wenn wir die CICD- und Helm-Charts bereits vorbereitet haben).
Die größten Herausforderungen mit NiFi auf Kubernetes
Die Übertragung einiger Anwendungen auf Kubernetes ist ziemlich einfach, aber das ist bei Apache NiFi nicht der Fall. Es ist eine Statefulset-Anwendung und wird in den meisten Fällen als Cluster auf dem Bare-Metal-System oder einer virtuellen Maschine bereitgestellt. Das wäre perfekt, wenn es nicht einen wichtigen Punkt in der Architektur gäbe: Jeder NiFi-Knoten teilt oder repliziert die Verarbeitungsdaten nicht zwischen den Clusterknoten. Das macht den gesamten Prozess komplizierter. Glücklicherweise gibt es eine Lösung, um die Probleme von NiFi im Zusammenhang mit der Arbeit im Clustermodus zu überwinden, die eine zusätzliche Installation von Zookeeper erfordert. Bei dieser Idee geht es darum, die Pipelines in separate NiFi-Instanzen aufzuteilen, wobei jede Instanz als eigenständige Instanz arbeiten würde. Das scheint der richtige Weg zu sein, um stabile NiFis auf Kubernetes zu erstellen und wir können ihre Konfigurationen leicht vom Repository aus verwalten, indem wir z.B. Helm-Charts mit einer speziellen Wertedatei verwenden.
Hier kommen wir zum ersten wichtigen Punkt über NiFi. NiFi nutzt eine große Menge an Lese- und Schreibvorgängen auf der Festplatte, insbesondere wenn wir viele Pipelines haben, die ständig Daten lesen, Operationen darauf ausführen und Daten senden oder die Prozesse auf der Grundlage des Inhalts des Datenflusses planen und überwachen. Das erfordert einen ziemlich performanten Speicher unter der Haube. Ein langsamer Festplatten- oder Netzwerkspeicher scheint nicht die richtige Lösung zu sein, daher empfehle ich hier die Verwendung eines Objektspeichers (vor Ort, wie CEPH) oder eines schnelleren Speichers. Bei einer hohen Auslastung von NiFi wäre die richtige Lösung die Verwendung einer lokalen SSD-Festplatte, aber das bietet keine echte Hochverfügbarkeit des Dienstes. 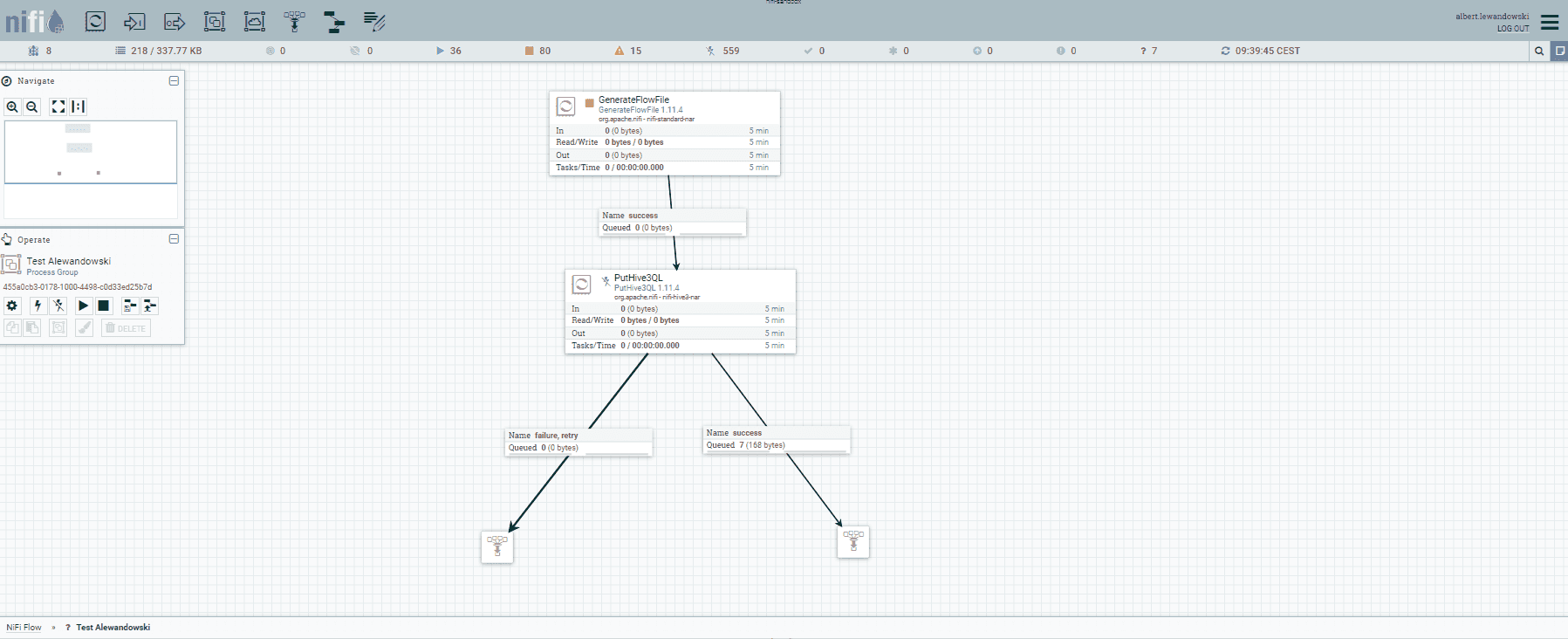 NiFi
NiFi
Der zweite Punkt ist die Netzwerkleistung zwischen Kubernetes-Clustern und Hadoop-Clustern oder Kafka-Clustern. Sicherlich lesen wir Daten aus der Quelle, verarbeiten sie und speichern sie dann irgendwo - wir müssen eine stabile, schnelle Netzwerkverbindung haben, um sicher zu sein, dass es keine Engpässe gibt. Dies ist besonders wichtig beim Speichern der Datei, z.B. beim Speichern der Datei im HDFS und dem anschließenden Wiederaufbau der Hive-Tabelle.
Der dritte Punkt ist der Migrationsprozess. Es geht nicht darum, die NiFis an einem Tag zu ändern - wir sollten mindestens eine Woche einplanen, um eine Pipeline nach der anderen zu verschieben und zu prüfen, ob NiFi wie erwartet funktioniert.
Die vierte Herausforderung besteht darin, die richtige CICD-Pipeline für unsere Bedürfnisse zu erstellen. Diese besteht in der Tat aus mehreren Schichten. In der ersten geht es um die Erstellung des Basis-Docker-Images, hier können wir auch das offizielle verwenden. Es geht um die Erstellung spezifischer Images, die unsere benutzerdefinierten NARs enthalten - glücklicherweise funktioniert die Verwendung von mehrstufigen Dockerfiles in diesen Fällen und ist hier die richtige Wahl. Im zweiten Teil geht es um die Erstellung der Bereitstellung in Kubernetes. Die Verwendung von Helm oder Helmfile ist umfangreich und darauf vorbereitet, als Basis für viele Deployments verwendet zu werden, und es ist einfach, sich mit allen Details vertraut zu machen.
Die fünfte Herausforderung besteht darin, NiFi für die Benutzer zugänglich zu machen. In der Kubernetes-Welt können wir die Anwendung über den Service oder Ingress zugänglich machen. Das ist einfach, wenn wir über NiFi mit HTTP sprechen, aber mit HTTPS wird es komplizierter. Im Ingress muss die Option eingerichtet werden, die für den SSL-Passthrough verantwortlich ist. Das einzige Problem, das bei diesem Projekt auftrat, war, dass das Zertifikat von Ingress von NiFi als Versuch der Benutzerauthentifizierung behandelt wurde. Andererseits würde es mit dem folgenden Szenario funktionieren: Der HTTPS-Verkehr wird an den Webservice weitergeleitet, der für die SSL-Terminierung zuständig ist, und verschlüsselt den Verkehr erneut an NiFi.
Die sechste Herausforderung basiert auf der Überwachung. Wir verwenden in unseren Projekten vor Ort hauptsächlich Prometheus, und die Konfiguration des Prometheus-Exporters ist so einfach wie das Hinzufügen eines separaten Prozesses in NiFi, der für das Pushen der Metriken an das PushGateway zuständig ist, von dem Prometheus sie lesen kann. Hier kommen wir zu dem Problem von NiFi - bei einigen Prozessoren scheint es Speicherlecks zu geben. Es ist wichtig, NiFi in Kubernetes laufen zu lassen, die Nutzung seiner Ressourcen zu überwachen und zu überprüfen, wie es mit den Verarbeitungsdaten umgeht. Ein Ratschlag: Setzen Sie den Mindestwert für die JVM auf die gleiche Höhe und lassen Sie eine größere Differenz zwischen dem JVM-Speicherwert und dem Limit des RAM für den gesamten Pod.
Im siebten Teil geht es um die Verwaltung von Zertifikaten, denn es gibt mehrere Möglichkeiten, dies zu erreichen. Die einfachste Lösung besteht darin, jedes Mal ein Zertifikat mit dem NiFI Toolkit zu erzeugen und es als Sidecar für NiFI auszuführen. Eine andere Möglichkeit besteht darin, das erstellte Zertifikat, den erstellten Truststore und den Keystore zu verwenden (speichern Sie sie als geheime Dateien als Kubernetes-Geheimnisse oder, wie empfohlen, unter Verwendung eines Geheimnis-Managers wie Google Cloud Secrets Manager oder Hashicorp Vault) und sie dann in das NiFi-Statefulset einzubinden. Wenn wir ein Zertifikat zum Truststore hinzufügen müssen, können wir es importieren, indem wir den Truststore erneut hochladen oder es bei jedem Start dynamisch importieren.
Wie Sie NiFi auf Kubernetes einsetzen.
Das Helm-Diagramm von Apache NiFi und NiFi Registry ist hier verfügbar.
NiFi Registry auf Kubernetes - Voraussetzungen und Einsatz
Apache NiFi Registry wurde entwickelt, um eine Art Git-Repository für Apache NiFi-Pipelines zu werden. Unter der Haube verwendet NiFi Registry ein Git-Repository und speichert alle Informationen über die Änderungen in seiner eigenen Datenbank (standardmäßig ist es eine H2-Datenbank, aber wir können stattdessen auch eine PostgreSQL- oder MySQL-Datenbank einrichten). Es ist keine perfekte Lösung, es gibt viele Schwierigkeiten bei der Verwendung als Teil der CICD-Pipeline, aber ganz ehrlich, es scheint die richtige Lösung für das NiFi Ökosystem zu sein, um alle Pipelines und ihre Geschichte an einem Ort zu speichern. Die größte Herausforderung bei der Verwaltung scheint die Speicherung und Aktualisierung des Keystore und Truststore zu sein, genau wie bei Apache NiFi. 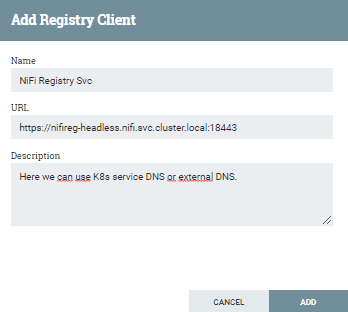
NiFi-Register
Wie das Apache NiFi ist auch NiFi Registry eine zustandsorientierte Anwendung. Sie benötigt Speicherplatz für ein lokal geklontes Git-Repository und eine Datenbank (wenn wir uns für die Verwendung von Standard-H2 entscheiden). Hier empfehle ich die Verwendung von PostgreSQL oder MySQL, die im Vergleich zu H2 eine robuste Lösung darstellen und die wir getrennt von NiFi Registry verwalten können.
NiFi auf Kubernetes und Apache Ranger - wie sollten Sie sie kombinieren?
Ein wichtiger Aspekt jeder unternehmenstauglichen Datenplattform ist die Verwaltung von Berechtigungen für alle Dienste. Die einfachste Variante ist die Verwaltung von Berechtigungen, Benutzern und Gruppen direkt in Apache NiFi oder Apache NiFi Registry, aber zum Glück können wir auch etwas Komplexes und Flexibles verwenden. Ich meine hier Apache Ranger. Dabei handelt es sich um ein Framework zur Aktivierung, Überwachung und Verwaltung umfassender Datensicherheit auf der gesamten Hadoop-Plattform. 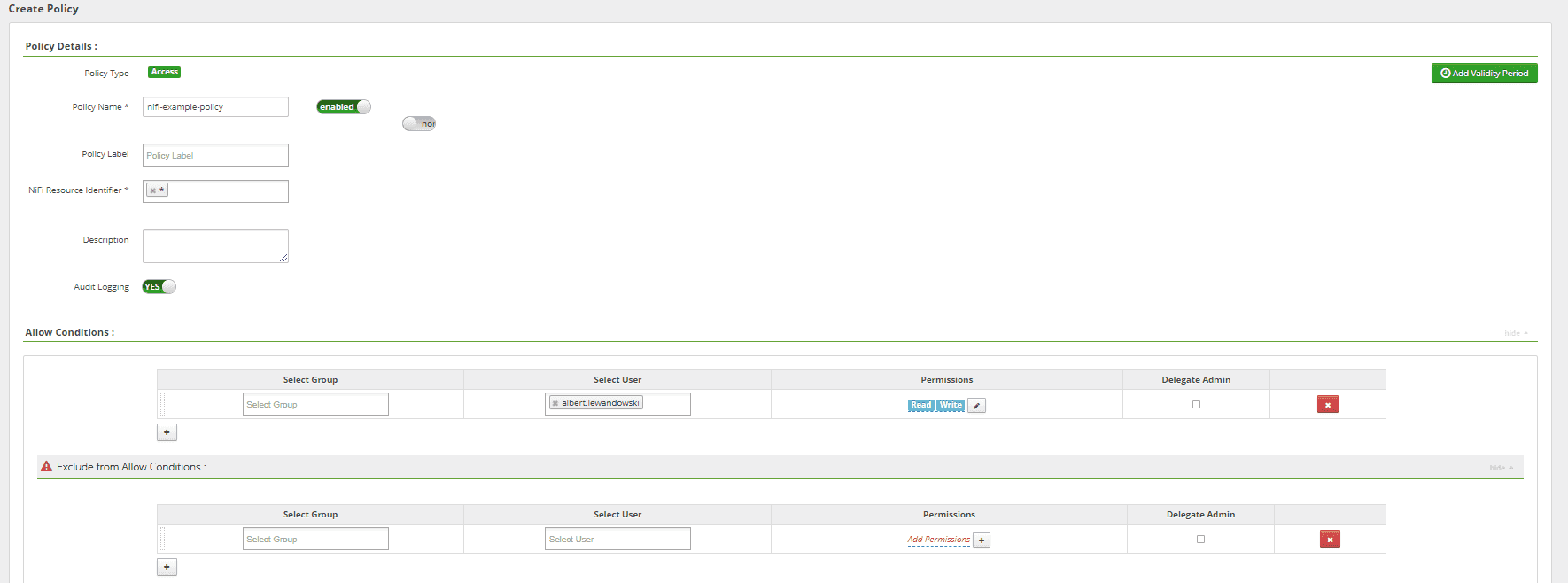
Mit seinen umfangreichen Funktionen können wir NiFi- und NiFi Registry-Richtlinien direkt in der GUI oder über die REST-API einrichten und darüber hinaus das Audit mit Informationen über den verweigerten Zugriff für jeden Benutzer einsehen, der aufgrund der Ranger-Richtlinien nicht akzeptiert wird. In diesem Fall müssten wir Ranger Audit in NiFis konfigurieren und die Verbindung zu Infra Solr und HDFS einrichten, die für die Speicherung von heißen und kalten Daten über Audit verwendet werden.
Die Grundvoraussetzung ist, dass Sie Apache Ranger installiert haben.
Der erste Schritt bei der Verbindung von Ranger und NiFi besteht darin, die neue Dockerdatei mit dem Ranger-Plugin für jedes NiFi zu erstellen. Der beste Weg, dies zu erreichen, ist die Erstellung eines mehrstufigen Dockerfiles, in dem wir das Plugin erstellen und es dann der Schicht mit NiFi selbst hinzufügen können. Sie können das Beispiel im Repository sehen.
Die zweite erfordert das Hinzufügen neuer Richtlinien im Ranger, die wir einfach während des ersten Laufs unserer gesicherten Einrichtung testen können.
Als Nächstes müssen Sie alle von Ranger benötigten Dateien erstellen, wie die Konfiguration der Verbindung zum Ranger von NiFi, die Audit-Einstellungen und die Aktualisierung der NiFi-Autorisierer zur Verwendung des Ranger-Plugins. Dann müssen wir NiFis starten und überprüfen, ob es wie erwartet funktioniert.
NiFi und Kerberos
Die Einrichtung von Kerberos innerhalb von NiFi ist nach Abschluss des Bereitstellungsprozesses ein Kinderspiel. Wir müssen uns die Verbindung zwischen dem Kubernetes-Cluster und Kerberos-Dienstanbietern wie FreeIPA oder AD merken. Der wichtigste Teil ist die Erstellung der Headless-Keytabs, die nicht in ihrem Prinzipal enthalten sind, um die Verwaltung der Keytabs für NiFis zu vereinfachen. Außerdem müssen wir die Datei krb5.conf einhängen und Kerberos-Client-Pakete installieren.
Zusammenfassung: NiFi tritt in eine neue Ära ein
Apache NiFi ist eine der beliebtesten Big Data-Anwendungen und wird schon seit langem eingesetzt. Es hat mehrere Versionen gegeben und ist ein großer Teil der Lösung, die inzwischen ziemlich ausgereift ist. Wir können viele Dienste wie NiFi Registry oder NiFi Tools in seinem eigenen Ökosystem finden. Die Verwendung von Kubernetes als Plattform für den Betrieb von NiFI vereinfacht den Einsatz, die Verwaltung, das Upgrade und die Migration, die bei den älteren Setups komplex sind.
Sicherlich ist Kubernetes nicht die Lösung für alle Probleme mit NiFi, aber es kann ein nützlicher nächster Schritt sein, um die NiFi-Plattform zu verbessern.
Verfasst von
Albert Lewandowski
Unsere Ideen
Weitere Blogs




Contact