Blog
Beschleunigen Sie die Datenverarbeitung mit speicheroptimierten Azure SQL-Tabellen

In vielen Fällen ist die Verwendung von Azure SQL Server mit plattenbasierten Tabellen ausreichend und funktioniert für die meisten Anwendungen gut. Ich denke, dass es wichtig ist, die Auswirkungen der Gleichzeitigkeit zu bedenken, die zu nachteiligen Effekten führen können. Festplattenbasierte Tabellen verwenden Sperren, um gleichzeitige Szenarien zu verwalten, was zu einer langsamen Leistung führen kann, wenn mehrere Operationen innerhalb eines bestimmten Zeitfensters ausgeführt werden. Sie können z.B. Indizes (ob geclustert oder nicht) zu den Tabellen hinzufügen, aber selbst das reicht möglicherweise nicht aus.
Vielleicht bauen Sie eine hochgradig transaktionale Anwendung, bei der Daten in schneller Folge in eine Tabelle gelesen und geschrieben werden (oder Sie möchten eine solche Anwendung bauen). Eine Option in diesem Szenario ist die Verwendung speicheroptimierter Tabellen. Sie wurden entwickelt, um große Mengen an Transaktionen mit gleichbleibend niedrigen Latenzzeiten zu unterstützen. Speicheroptimierte Tabellen sind frei von Sperren und speichern alles im Speicher, was zu einem viel schnelleren Datenzugriff führt und Lese- und Schreibvorgänge auf der Festplatte überflüssig macht. Dieser Blog-Artikel befasst sich mit der Verwendung von speicheroptimierten Azure SQL-Tabellen für Anwendungen, die ein relationales Datenmodell und hochperformante Operationen erfordern.
Hochperformantes Anwendungsszenario
Stellen wir uns eine Anwendung vor, die Daten von RESTful-APIsvon Drittanbietern abruft, die Daten verarbeitet und sie dann in einer Azure SQL-Datenbank speichert. Hier sind ein paar Merkmale der Anwendung:
- Die Daten werden so schnell wie möglich verarbeitet.
- Bei jeder Verarbeitungsiteration werden über 150k Datenzeilen entweder eingefügt oder aktualisiert.
- Die Daten werden jederzeit in beliebiger Häufigkeit von einer Web-API und der entsprechenden Web-UI gelesen.
- Die Anwendung ist nur mit neuen Daten befasst, die von den RESTful-Endpunktenvon Drittanbietern kommen.
- Es besteht keine Notwendigkeit, Daten aus historischen Gründen zu speichern.
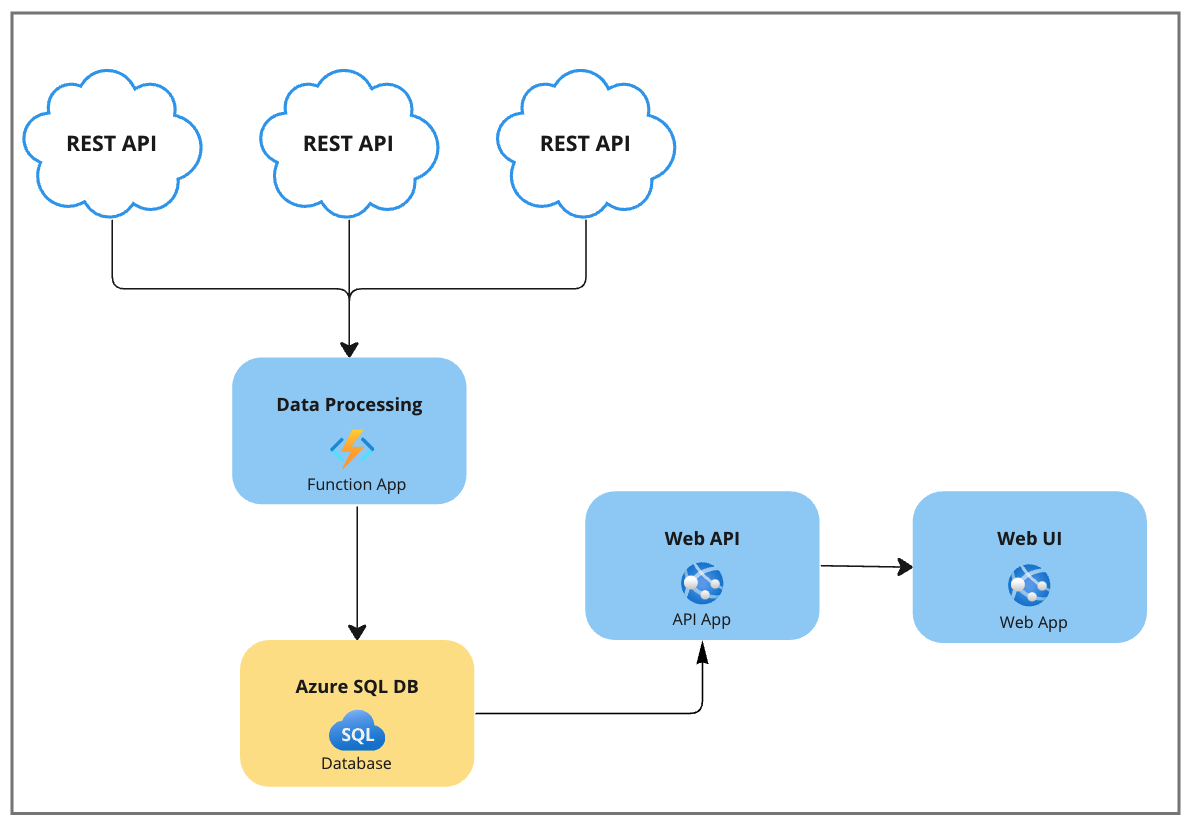
Vielleicht denken Sie jetzt: "Ist das die richtige Architektur?" oder "Wir können hier eine Skalierung einführen". Lassen wir diese Gedanken beiseite und konzentrieren wir uns in diesem Szenario auf die Datentransaktionen selbst.
Bei der Verwendung von plattenbasierten Tabellen in diesem Szenario gibt es einige Optionen, die Ihnen einfallen, um zusätzliche Leistung zu erzielen. Die Optionen umfassen:
Kill-and-Fill
Jedes Mal, wenn die App 'Datenverarbeitungsfunktionen' ausgelöst wird, können wir alles in der Azure SQL-Tabelle löschen und durch alle neuen Daten ersetzen, die von den RESTful-Endpunkten kommen.
| Profis | Nachteile |
| Einfache Operation(en) | Kurzzeitige Lücken in den Daten, während die Kill-and-Fill-Operation noch ausgeführt wird |
| Erfordert keine komplexe Vergleichslogik, um festzustellen, ob sich vorhandene Daten geändert haben. | Es gibt Fälle, in denen die Benutzeroberfläche während des Kill-and-Fill-Vorgangs unvollständige Daten abrufen würde |
| Indizes müssten beim ersten Löschen aller Daten neu angelegt werden | |
| Je nachdem, wie viele Daten in der Tabelle vorhanden sind, könnte dies eine teure Operation sein |
Diff die Daten
Die eingehenden Daten können mit den vorhandenen Daten verglichen und entsprechend aktualisiert werden. Dazu können Sie entweder eine äußere Verknüpfung mit bestimmten Spalten der Tabelle durchführen oder einen Hash-Schlüssel auf der Grundlage bestimmter Werte erzeugen und einen Hash-Schlüssel mit einem anderen vergleichen.
| Profis | Nachteile |
| Behält Indizes bei, da einige Daten immer in der Tabelle vorhanden sein werden | Komplexe Operationen (die Logik kann entweder im Code oder mit einer SQL Stored Procedure ausgeführt werden) |
| Dieser Vorgang könnte sehr teuer werden und den gesamten Prozess mit zusätzlichen Verzögerungen belasten. | |
| Höhere Komplexität, die zu Fehlern und Randfällen führt, in denen Probleme auftreten können |
Kombination von beidem mit Bulk Copy
Ein anderer Ansatz könnte darin bestehen, ein Pseudo-Kill-and-Fill durchzuführen, aber die Daten der letzten Iteration beizubehalten, so dass die Tabelle nie leer ist. Beim Einfügen der Daten kann die Klasse SQL Bulk Copy für ein schnelleres Einfügen verwendet werden.
| Profis | Nachteile |
| Schnellere Einsätze | Höhere Komplexität bei der Nachverfolgung der Daten aus der letzten Iteration |
| Verwaltet Indizes | Mehrere Operationen könnten sehr teuer werden und den Gesamtprozess zusätzlich verzögern. |
Letztendlich hat jede dieser Optionen immer noch erhebliche negative Auswirkungen. Lassen Sie uns einen völlig anderen Ansatz mit speicheroptimierten Tabellen betrachten.
Speicheroptimierte Tabellen verwenden
In Anbetracht des Szenarios dieser Anwendung wären speicheroptimierte Tabellen ein großartiger Ansatz, denn sie können eine bis zu 30-fache Leistungssteigerung bieten. Sie wurden entwickelt, um große Mengen von Transaktionen mit regelmäßig niedrigen Latenzzeiten für einzelne Transaktionen zu unterstützen. Einer der wichtigsten Mechanismen, mit dem diese Leistungsverbesserung erreicht wird, ist die Beseitigung von Sperren und fehlenden Konflikten zwischen gleichzeitig ausgeführten Transaktionen. Alle Transaktionen in speicheroptimierten Tabellen sind außerdem dauerhaft. Alle Änderungen werden im Transaktionsprotokoll auf der Festplatte aufgezeichnet, was für Datenredundanz sorgt. Zusätzlich zu den Tabellen selbst können Entwickler nativ kompilierte gespeicherte Prozeduren nutzen, die die für Transaktionen benötigte Zeit weiter reduzieren, indem sie die CPU-Zyklen verringern. Wenn wir uns die Eigenschaften der Anwendung noch einmal ansehen, wurde die Verwendung speicheroptimierter Tabellen für Szenarien wie dieses konzipiert.
Erstellen und Lesen von speicheroptimierten Tabellen
Es gibt zahlreiche Dokumentationen von Microsoft, die Ihnen zeigen, wie Sie speicheroptimierte Tabellen erstellen können. Sie können dazu das SQL Server Management Studio (SSMS) verwenden. Ich habe ein einfaches DDL-Skript beigefügt, das zeigt, wie Sie eine Tabelle erstellen. Beachten Sie, dass der Wert 'MEMORY_OPTIMIZED' auf 'ON' gesetzt ist und die 'DURABILITY' in Zeile 20 eingestellt ist. Die Optionen für die Einstellung der Haltbarkeit können Sie hier einsehen.
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[DataProviders]
(
[Id][bigint] IDENTITY(1, 1) NOT NULL,
[DataProvider][nvarchar](50) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL,
[Value][nvarchar](200) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
CONSTRAINT[PK_DataProviders] PRIMARY KEY NONCLUSTERED
(
[Id] ASC
)
)WITH(MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY)
GOJe nachdem, wie auf die Daten vom Code aus zugegriffen wird, können Sie Abfragen direkt in die speicheroptimierten Tabellen schreiben, entweder mit Inline-SQL (wenn rohes ADO verwendet wird) oder mit Linq-Abfragen (wenn das Entity Framework verwendet wird). Wie bereits erwähnt, können zur Verbesserung der Leistung auch nativ kompilierte Stored Procedures verwendet werden.
Natürlich kompilierte Stored Procedures
Wenn wir noch einmal auf den Kill-and-Fill-Ansatz zurückkommen, den wir bei plattenbasierten Tabellen erörtert haben, kann derselbe Ansatz hier mit speicheroptimierten Tabellen verwendet werden, aber der große Unterschied ist die Leistung. Die oben genannten Nachteile würden aufgrund der dramatischen Leistungsverbesserung im Wesentlichen wegfallen. Die folgenden beiden Codeschnipsel veranschaulichen, wie Sie mit nativ kompilierten Stored Procedures Daten entfernen und einfügen (Kill-and-Fill).
Beachten Sie, dass 'WITH native_compilation' in Zeile 9 verwendet wird. Die Details zur Erstellung dieser gespeicherten Prozeduren finden Sie hier.
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE PROCEDURE [dbo].[memory_delete]
@lastProcessedDate Datetime,
WITH native_compilation,
schemabinding
AS
BEGIN
atomic WITH (TRANSACTION isolation level = snapshot, language = N'us_english');
DELETE FROM dbo.[Outcomes]
Where Created < @lastProcessedDate;
END
GODiese Prozedur verwendet einen tabellenwertigen Parameter namens 'memdataproviders'. Wenn Sie die Prozedur aus dem Code heraus aufrufen, kann ein DataTable-Objekt im .NET-Code erstellt und als Parameter an die Prozedur übergeben werden (Zeile 8).
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE PROCEDURE [dbo].[memory_insert]
@memdataproviders dbo.dataproviders readonly
WITH native_compilation,
schemabinding
AS
BEGIN
atomic WITH (TRANSACTION isolation level = snapshot, language = N'us_english');
INSERT INTO [dbo].[DataProviders]
(
[DataProvider] ,
[Value]
)
SELECT
[DataProvider] ,
[Value]
FROM @memoutcomes
END
GOKosten
Wie bei allem, was Sie tun, sollten Sie bei der Entscheidung für speicheroptimierte Tabellen die Kosten im Auge behalten. Diese Art von Technologie ist nur in den Azure SQL Premium- und Business Critical-Tiers verfügbar. Die Details zu den Preisvergleichen zwischen den einzelnen Stufen können Sie hier einsehen.
Fazit
Bei der Entwicklung von Anwendungen kann es immer eine Herausforderung sein, sich für den besten Ansatz zu entscheiden. In diesem Blogartikel haben wir ein spezifisches Szenario einer hochleistungsfähigen Anwendung untersucht, die kontinuierlich große Datenmengen so schnell wie möglich verarbeitet. Dieses Szenario ist auf viele Branchen und Anwendungsfälle anwendbar. Wenn Sie an Finanzinstrumente, mobile Spiele oder die Bereitstellung von Werbung denken, ist es klar, wo sich dies anbietet. Speicheroptimierte Tabellen können ein ausgezeichneter Ansatz sein, um die Datenverarbeitung in Azure zu verwalten und gleichzeitig die bestmögliche Leistung bei der Verwendung von relationalen Azure SQL-Datenbanken beizubehalten. Ziehen Sie den Einsatz in Betracht, wenn Sie bei der Entwicklung Ihrer Anwendung vor ähnlichen Herausforderungen stehen!
Erfahren Sie mehr darüber, wie Xpirit Ihnen helfen kann, Ihr Unternehmen zu verändern!
Folgen Sie mir hier auf Twitter !
Verfasst von

Esteban Garcia
Managing Director at Xebia Microsoft Services US and a recognized expert in DevOps, GitHub Advanced Security, and GitHub Copilot. As a Microsoft Regional Director (RD) and Most Valuable Professional (MVP), he leads his team in adopting cutting-edge Microsoft technologies to enhance client services across various industries. Esteemed for his contributions to the tech community, Esteban is a prominent speaker and advocate for innovative software development and security solutions.
Contact