
Bevor Sie sich darüber beschweren, dass Big Data ein völlig überladener Begriff ist, denke ich, dass wir unabhängig davon, ob das stimmt, erst einmal lernen müssen, damit zu leben. Der Begriff Big Data wird uns noch eine Weile begleiten. Hier ist der Grund dafür:
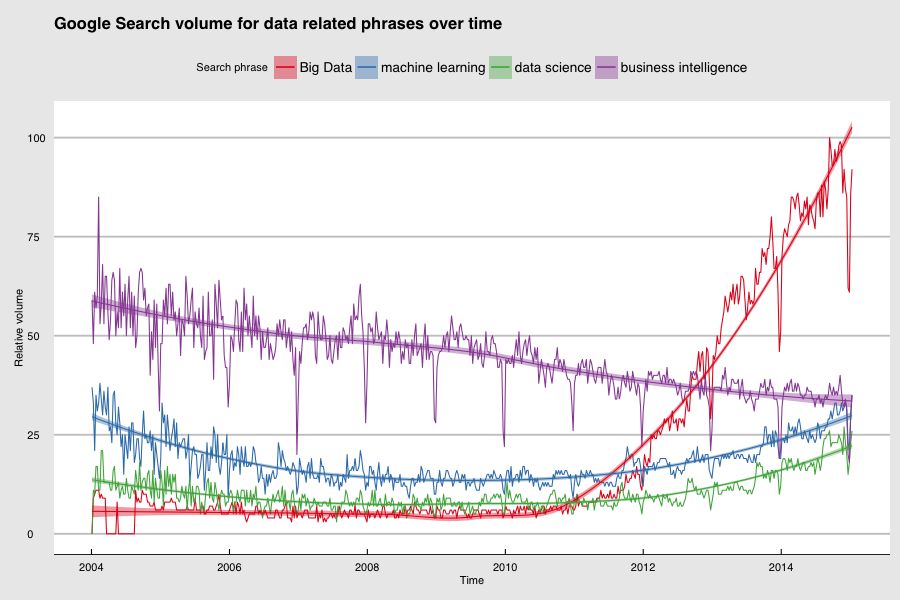
Quelle: Google Trends.
Das Interesse ist eindeutig auf dem Höhepunkt und die Menschen sind in Kauflaune. Wenn die Menschen in Kauflaune sind, verkaufen die Unternehmen. Die Unternehmen, die verkaufen, haben ganze Abteilungen, die dafür sorgen, dass wir davon hören (auch bekannt als Marketing): Ich denke, wir werden noch eine ganze Weile von Big Data hören. Lassen Sie uns einen Blick darauf werfen, wie es dazu kam und was wir tun können, um davon zu profitieren.
Big Data avant la lettre
Im Jahr 2009 war ich Teil eines Teams, das sich mit der Indizierung und dem Abruf großer Mengen von Netzwerkdaten beschäftigte, die von unserem Kunden gesammelt wurden. Die bestehende Lösung, bei der MySQL-Datenbanken gesplittet wurden, funktionierte zwar, war aber mühsam zu warten und hatte mit Skalierbarkeitsproblemen zu kämpfen, so dass wir Apache Hadoop und HBase als Ersatz ausprobierten. Beide Technologien waren bestenfalls schwer zu warten und brachten in scheinbar zufälligen Momenten kryptische Fehlermeldungen, bis man sich die Zeit nahm, den eigentlichen Quellcode zu lesen und herausfand, wie die Dinge wirklich funktionierten. Darüber hinaus war die Software nicht sonderlich effizient in dem, was sie tat; sie holte nicht alles an Leistung aus den Rechnern heraus, auf denen sie lief. Doch trotz dieser Macken haben Hadoop und HBase vor allem eines getan: Sie sind skalierbar.
Hadoop und seine MapReduce-Implementierung boten eine allgemein verfügbare, quelloffene, skalierbare Abstraktion, die es Entwicklern ermöglichte, sich auf ihren Datenverarbeitungscode zu konzentrieren.
Im Wesentlichen bedeutete dies, dass es keine Rolle spielte, ob Sie einen Auftrag für einen Cluster mit zwei Rechnern oder einen Cluster mit zweihundert Rechnern programmierten; derselbe Code würde auf beiden gleichermaßen laufen. Wenn Sie viele Daten haben und nicht wissen, wie schnell sie wachsen werden, bedeutet das eine Menge. Ganz zu schweigen davon, dass es eine lebhafte Gemeinschaft von Leuten gab, die an dieser Open-Source-Software arbeiteten und Fragen auf Mailinglisten in einer Weise beantworteten, die den meisten kommerziellen Supportangeboten für Datenbanksoftware weit überlegen war. Wir haben viel Zeit damit verbracht, Cluster einzurichten, Probleme zu beheben und eine Menge auszuprobieren. Am Ende hat alles relativ gut funktioniert. Wie bei den meisten Softwareprojekten haben wir es geschafft, dass es funktioniert.
Wenig später gewann Hadoop an Zugkraft, da große Webunternehmen über Erfolge mit dieser Technologie berichteten. Die Kritiker waren damit beschäftigt, auf die praktischen Probleme hinzuweisen, während diejenigen, die die theoretischen Möglichkeiten verstanden, hart daran arbeiteten, die Software zu verbessern. Zu dieser Zeit begannen auch die Abteilungen, die dafür sorgen, dass wir von den Dingen erfahren, sie Big Data zu nennen und dafür zu sorgen, dass jeder über die
In der Zwischenzeit waren die Menschen, die tatsächlich von der Technologie profitierten, nicht so sehr daran interessiert, welches der V's ihre Probleme verkörperten, sondern hauptsächlich daran, die Dinge zu erledigen. Es war, als gäbe es eine Big-Data-Welt, angeführt von Leuten wie Gartner, und eine Hadoop-Welt, angeführt von Ingenieuren. Unternehmen, die bereits Probleme mit der Skalierbarkeit ihrer Daten hatten, sahen sich Hadoop als Lösung an, während Unternehmen, die gut zurechtkamen, aber Angst hatten, Big Data zu verpassen, hart daran arbeiteten, Anwendungsfälle zu erfinden, die zu ihnen passen würden. Letzteres mag zwar albern erscheinen, ist aber gar nicht so verschwenderisch, wie es klingen mag. Diese Initiativen trieben die Innovation voran und zwangen traditionelle Unternehmen dazu, einige ihrer Geschäfte neu zu bewerten und neue Wege einzuschlagen. In den meisten dieser Fälle war nicht die Tatsache, dass Hadoop große Datenmengen verarbeiten kann, das interessante Ergebnis. Vielmehr war es die Tatsache, dass ein Großteil der in Unternehmen verfügbaren Daten auf andere Weise als für den vorgesehenen Zweck genutzt werden kann und zu neuen Geschäfts- oder Kundenkontakten führt. In einigen Fällen war eine Plattform wie Hadoop technisch nicht erforderlich, aber sie trug dazu bei, ein Klima für Innovationen zu schaffen; sie brachte die Menschen dazu, über die Nutzung von Daten anders nachzudenken.
Das Versprechen von Big Data
Die Magie von Big Data besteht angeblich darin, dass Sie mit sehr einfachen Methoden und Modellen interessante und aussagekräftige Ergebnisse erzielen können, solange die Datenmenge sehr groß ist. Die Muster tauchen einfach auf. Ein Beispiel dafür ist die Google Trends-Grafik oben in diesem Beitrag. Wir können Aussagen über das relative öffentliche Interesse an diesen Themen machen, wenn wir davon ausgehen, dass es einen Zusammenhang zwischen dem Suchverhalten der Menschen und realen Ereignissen und Trends gibt. In diesem Fall interessiert uns die Kausalität dieser Beziehung nicht. Die verwendete Methode ist extrem einfach: Zählen Sie, wie oft eine Suche vorkommt. Dennoch sind die Ergebnisse aufgrund des immensen Datenvolumens interessant.
Wenn Sie sich über den Zusammenhang zwischen Google-Suchanfragen und realen Ereignissen wundern, finden Sie hier ein Beispiel, das sich kaum leugnen lässt. In der Grafik unten zeigen die Punkte auf der blauen Linie das relative wöchentliche Suchvolumen für den Begriff "Vollmond" an. Die Wochen mit den roten Punkten sind die Wochen, in denen ein Vollmond stattfand, die Wochen mit den blauen Punkten die übrigen. Es gibt eine sehr klare Beziehung zwischen dem Suchvolumen und dem realen Ereignis. Es ist für uns leicht zu verstehen, dass die Suchanfragen keinen Vollmond verursachen, genauso wie die Suchanfragen nach Big Data nicht das Interesse an diesem Thema verursachen. Für ein Modell, das den nächsten Vollmond (oder die nächste Welle des Interesses an einem Thema) vorhersagt, ist dies jedoch nicht relevant. Sie können einfach Wörter im Internet zählen, um Aussagen über die reale Welt zu treffen: Big Data in seiner schönsten Form.
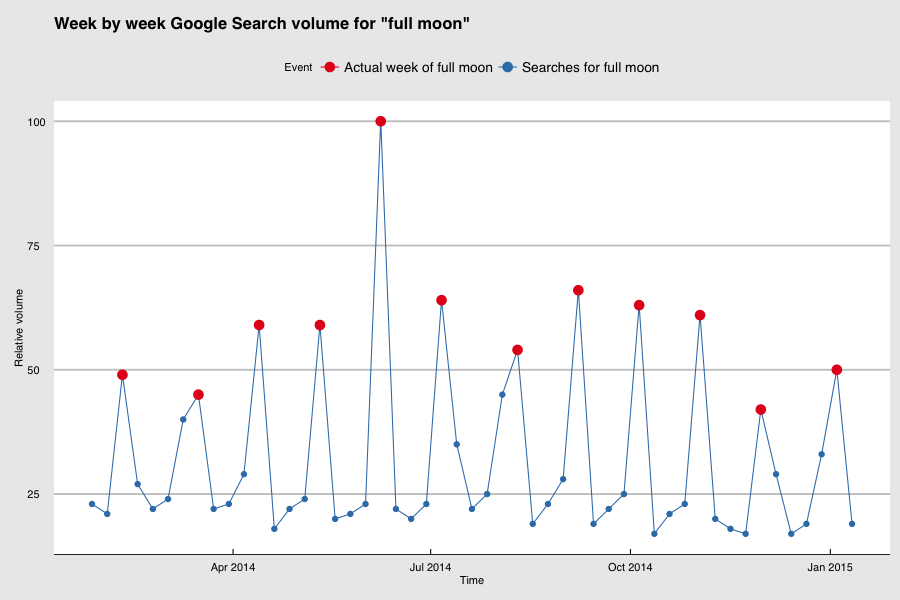
Quelle: Google Trends und moongiant.com. Hinweis: Google Trends zeigt nur wochenweise Daten an, so dass die Vollmonddaten ebenfalls auf den Beginn der Woche, in der sie stattfanden, normalisiert sind.
Wie sich herausstellt, sind die obigen Beispiele zwar nett, aber das Zählen von Wörtern im Internet löst nicht alle Geschäftsprobleme. Wir möchten detailliertere Vorhersagen machen als die über die gesamte Population der Google-Nutzer. Wir kümmern uns um unsere eigenen Kunden oder Nutzergemeinschaften, denn sie erwarten von unseren Produkten ein sehr hohes Maß an Personalisierung und Anpassung. Doch die Daten, die wir über diese Kunden sammeln, sind in der Regel sehr spärlich. Als Online-Händler haben Sie vielleicht Millionen von Besuchern, aber jeder einzelne von ihnen besucht Ihren Shop vielleicht nur ein- oder zweimal im Jahr. Trotzdem sollen wir ihnen personalisierte E-Mail-Kampagnen schicken, punktgenaue Produktempfehlungen geben und erkennen können, ob es Möglichkeiten für Up-Sell oder Cross-Sell gibt. All dies basiert auf diesen ein oder zwei Besuchen pro Jahr.
Die Gesamtmenge der Daten kann sehr groß sein, aber die Menge der Informationen über einzelne Kunden ist begrenzt. In diesem Szenario noch eine punktgenaue Personalisierung zu bieten, ist ein sehr schwieriges Problem und geht weit über das Zählen von Wörtern hinaus: Hier kommen Data Science und maschinelles Lernen ins Spiel.
Es überrascht nicht, dass wir in unseren Suchtrends feststellen, dass diese Disziplinen im Vergleich zu traditionelleren datenbezogenen Arbeiten wie Business Intelligence immer beliebter werden.
Die Fähigkeiten, die für die Bearbeitung von Problemen im Bereich Data Science und maschinelles Lernen erforderlich sind, sind rar und die Kombination dieser Fähigkeiten mit denen, die für den Umgang mit großen Datenmengen aus einer technischen Perspektive erforderlich sind, noch viel mehr. Aus diesem Grund haben wir GoDataDriven gegründet. Wir helfen unseren Kunden, diesen Weg einzuschlagen. Außerdem sind diese komplexen Modelle und Methoden sehr viel rechenintensiver als das bloße Zählen von Wörtern. Glücklicherweise befinden wir uns hier in einer guten Position.
Computer sind billig und schnell
Viele der Methoden, die derzeit beim maschinellen Lernen in großem Maßstab eingesetzt werden, sind Jahre, wenn nicht Jahrzehnte alt. Natürlich gibt es in letzter Zeit Verfeinerungen und zusätzliche Forschungsarbeiten, aber das Grundgerüst gibt es schon seit langem. Zwei Dinge haben sich geändert: Wir haben mehr Daten und wir haben bessere Möglichkeiten, sie zu verarbeiten.
Es geht nicht so sehr darum, dass wir früher nicht in der Lage waren, leistungsfähige Computer zu bauen, sondern dass sich die Wirtschaftlichkeit der Skalierung von Computersystemen drastisch verändert hat.
Ab und zu wird im Internet etwas über dieses Phänomen gewitzelt:
"'Wenn Sie die Rechenleistung, die in einem iPhone 5S steckt, im Jahr 1991 gekauft hätten, hätte es Sie 3,56 Millionen Dollar gekostet.'" Technologie: Der große Gleichmacher
â Steven Sinofsky (@stevesi) December 23, 2014
Mit oder ohne zweijähriges Abonnement. Es wäre auch nicht gerade im Taschenformat gewesen.
Diese Zahl mag zwar nicht auf den Dollar genau sein, aber die Größenordnung ist wahrscheinlich korrekt. Die Rechenleistung in Ihrer Hosentasche war irgendwann einmal ein Multi-Millionen-Dollar-Computer, wahrscheinlich noch zu Ihren Lebzeiten.
Unten sehen Sie ein Diagramm, dessen Daten ursprünglich von John C. McCallum gesammelt und später von Blok ergänzt wurden, der auch dieses Diagramm erstellt hat. Beachten Sie, dass die vertikale Achse eine logarithmische Skala hat!
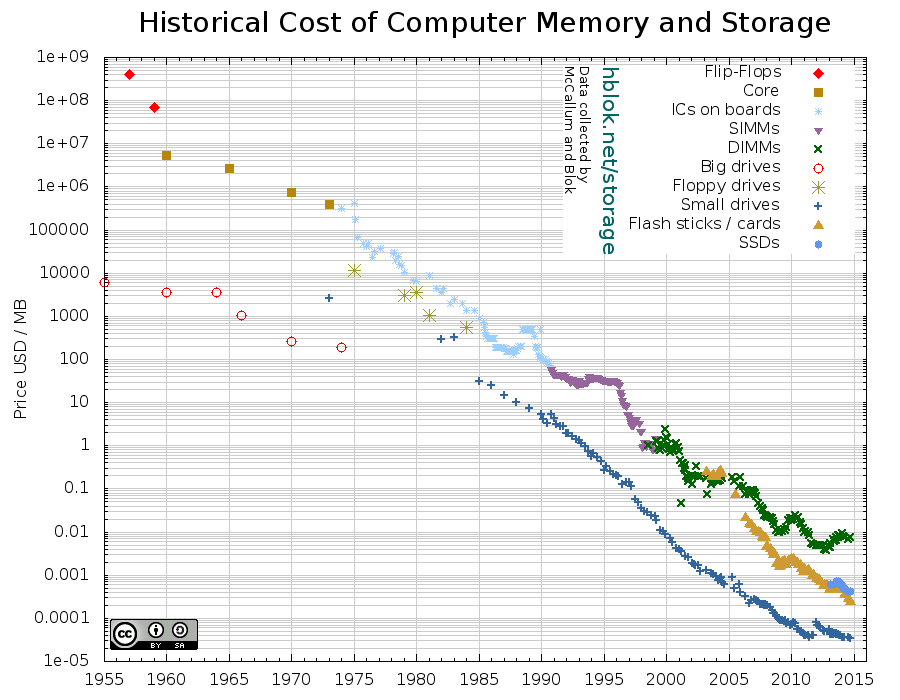 Hier gibt es ein paar Dinge zu beachten (in keiner bestimmten Reihenfolge). Als Google sein MapReduce-Papier veröffentlichte (2004), waren Spinning-Festplatten teurer als SSDs heute. Die erste Veröffentlichung von Hadoop war im September 2007. Zu diesem Zeitpunkt lagen die Preise für Spinning-Festplatten mehr oder weniger auf dem Niveau der heutigen SSD-Preise. Der niedrigste Preis für Arbeitsspeicher (RAM) entspricht in etwa den Preisen für Spinning Disks im Jahr 2001.
Wie auch immer Sie es betrachten: In-Memory-Computing ist eine attraktive Option für viele Probleme, die bisher auf der Festplatte gelöst werden mussten. Das Gleiche gilt für die Verwendung von SSDs anstelle von rotierenden Festplatten. Das Lesen von Daten von einer SSD ist etwa 6-7 Mal schneller als das Lesen von einer rotierenden Festplatte. Das Lesen von Daten aus dem Speicher ist etwa 105 Mal schneller als das Lesen von einer Spinning Disk und 15 Mal schneller als das Lesen von einer SSD. (Zahlen zur Latenzzeit mit freundlicher Genehmigung dieser Website).
All dies bedeutet, dass einige Probleme, die früher als Cluster-Probleme galten (d.h. zu groß für eine einzelne Maschine), jetzt Probleme im Maßstab einer einzelnen Maschine sind. Das Problem ist, dass es ein bewegliches Ziel ist, welche Klasse von Problemen Sie vor sich haben. Die Maschinen werden immer billiger und schneller, aber die Daten wachsen und die Methoden und Modelle, die wir anwenden, werden immer komplexer. Dies erfordert die Art von Skalierbarkeit, die Hadoop bietet. Um flexibel zu sein, sollte es keine Rolle spielen, ob Ihr Code auf zwei oder zweihundert Rechnern läuft.
Hier gibt es ein paar Dinge zu beachten (in keiner bestimmten Reihenfolge). Als Google sein MapReduce-Papier veröffentlichte (2004), waren Spinning-Festplatten teurer als SSDs heute. Die erste Veröffentlichung von Hadoop war im September 2007. Zu diesem Zeitpunkt lagen die Preise für Spinning-Festplatten mehr oder weniger auf dem Niveau der heutigen SSD-Preise. Der niedrigste Preis für Arbeitsspeicher (RAM) entspricht in etwa den Preisen für Spinning Disks im Jahr 2001.
Wie auch immer Sie es betrachten: In-Memory-Computing ist eine attraktive Option für viele Probleme, die bisher auf der Festplatte gelöst werden mussten. Das Gleiche gilt für die Verwendung von SSDs anstelle von rotierenden Festplatten. Das Lesen von Daten von einer SSD ist etwa 6-7 Mal schneller als das Lesen von einer rotierenden Festplatte. Das Lesen von Daten aus dem Speicher ist etwa 105 Mal schneller als das Lesen von einer Spinning Disk und 15 Mal schneller als das Lesen von einer SSD. (Zahlen zur Latenzzeit mit freundlicher Genehmigung dieser Website).
All dies bedeutet, dass einige Probleme, die früher als Cluster-Probleme galten (d.h. zu groß für eine einzelne Maschine), jetzt Probleme im Maßstab einer einzelnen Maschine sind. Das Problem ist, dass es ein bewegliches Ziel ist, welche Klasse von Problemen Sie vor sich haben. Die Maschinen werden immer billiger und schneller, aber die Daten wachsen und die Methoden und Modelle, die wir anwenden, werden immer komplexer. Dies erfordert die Art von Skalierbarkeit, die Hadoop bietet. Um flexibel zu sein, sollte es keine Rolle spielen, ob Ihr Code auf zwei oder zweihundert Rechnern läuft.
Die Ineffizienz der Verkleinerung
(Warnung: Technischer Inhalt voraus. Der folgende Abschnitt enthält Verweise auf technische Konzepte und Code. Wenn Sie sich nur für die sich daraus ergebenden geschäftlichen Empfehlungen interessieren, können Sie gerne bis zum Ende des Abschnitts springen). Es stimmt zwar, dass es für das frühe Hadoop MapReduce keinen Unterschied machte, ob Ihr Code auf zwei oder zweihundert Rechnern lief, aber der erste Fall war in der Praxis nicht wirklich sinnvoll. Verteiltes Rechnen ist immer mit Overhead verbunden und der Overhead von Hadoop MapReduce war so groß, dass es nur sinnvoll war, Hadoop auf mindestens 20 oder mehr Rechnern laufen zu lassen. Außerdem hängt MapReduce stark von der Festplatten-IO ab und macht nur minimale Annahmen über das Vorhandensein von viel Arbeitsspeicher (der in letzter Zeit sehr viel billiger geworden ist). Infolgedessen hat man an anderen Verarbeitungsabstraktionen gearbeitet, die den verfügbaren Speicher besser ausnutzen und nur dann auf Festplatten-IO zurückgreifen, wenn es die Arbeitslast erfordert. Wenn die verteilte Datenverarbeitung beginnt, den Arbeitsspeicher und den schnelleren Speicher zu nutzen, macht es Sinn, sich auch auf die Optimierung der Teile des Programms zu konzentrieren, die nicht im gesamten Cluster parallelisiert sind, wie z.B. das Starten von Aufträgen (siehe Amdahls Gesetz). Der Start-Overhead eines Hadoop MapReduce-Auftrags lag in den frühen Versionen in der Größenordnung von 30 Sekunden. Zurzeit liegt er eher bei 5 Sekunden. Neben MapReduce sind weitere Frameworks aufgetaucht, die auf der Hadoop-Speicherarchitektur aufbauen und die Kosten des Paralellismus sowie die Nutzung von Speicher und schnelleren Festplatten weiter optimiert haben. Eines dieser Frameworks ist das beliebte Apache Spark-Projekt. Wenn es zutrifft, dass diese neuen Abstraktionen den Speicher besser nutzen und den Overhead des Paralellismus gesenkt haben, sollte es realistisch sein, sehr kleine Cluster oder sogar Ein-Maschinen-Setups zu verwenden, aber mit einer skalierbaren Abstraktion, die potenziell zu großen Clustern skalieren kann. Dies würde uns in die Lage versetzen, uns wieder auf den Datenverarbeitungscode zu konzentrieren, ohne uns um die Skalierbarkeit kümmern zu müssen, aber als zusätzlichen Vorteil würde es uns erlauben, klein anzufangen (mit einem einzelnen Rechner, nicht mit einem Cluster). Lassen Sie uns das einmal testen. Nachfolgend finden Sie eine Tabelle mit der Zeit, die benötigt wird, um einfache Apache Spark Codeschnipsel gegen einen Datensatz von 600 Millionen Datensätzen mit etwa 40 GB an Rohdaten laufen zu lassen. Diese Zahlen sind keineswegs repräsentativ für das verwendete Framework und können mit relativ einfachen Mitteln (wie der Verwendung eines binären Dateiformats und Komprimierung) noch viel weiter optimiert werden. Diese Aufgaben wurden auf einem einzelnen Rechner mit 2x 10 CPU-Kernen, 128GB RAM und 2x 1,6TB SSD-Laufwerken in RAID0-Konfiguration ausgeführt. Einen solchen Rechner können Sie z.B. bei Rackspace im Rahmen des OnMetal-Angebots mieten. Zum Zeitpunkt des Verfassens dieses Artikels kostet diese Konfiguration USD 1.750,- pro Monat oder etwa USD 2,5 pro Stunde, was einem Preis von USD 21.000,- pro Jahr entspricht. Ohne Lizenzkosten ist dieser Preis nicht weit entfernt von einem typischen schweren Datenbankrechner einschließlich Lizenzen, wie er oft für Datawarehousing-Zwecke verwendet wird. Andere Cloud-Anbieter oder On-Premise-Hosting sollten nicht weit von diesem Preispunkt entfernt sein.| Aufgabe | Zeit | Code |
|---|---|---|
| Datei lesen und 600M Zeilen zählen |
val tf = sc.textFile("/mnt/raid/numbers.txt")
tf.count | |
| Datei lesen, CSV parsen und 600M Datensätze zählen |
val data = tf.map(_.split('|'))
.map(line => (
line(0).toLong, line(1).toLong,
line(2).toLong, line(3).toLong,
line(4).toLong, line(5).toDouble,
line(6).toDouble)
)
data.count | |
| Zusammenfassende Statistik über 600M Gleitpunkte | import org.apache.spark.SparkContext._ data.map(_._5.toDouble) .stats | |
| Gruppe mit niedriger Kardinalität nach Schlüssel + Anzahl | data.map( x => (x._3, 1) ) .reduceByKey(_ + _) .collect | |
| Top 10 der Spalte mit hoher Kardinalität und Long-Tail-Verteilung | data.map( x => (x._4, 1) ) .reduceByKey(_ + _) .map(List(_)) .reduce( (x,y) => (x ++ y).sortWith(_._2 > _._2) .slice(0,10)) | |
| KMeans-Clustering auf ~60M zwischengespeicherten 2D-Vektoren Hinweis: Das Clustering brauchte zwei Iterationen, um zu konvergieren. Rechnen Sie für jede nachfolgende Iteration etwa 4 Sekunden hinzu. Die Zeit beinhaltet nicht die Entnahme der Probe und die Zwischenspeicherung. | import org.apache.spark.mllib.clustering.KMeans import org.apache.spark.mllib.linalg.Vectors val clusterData = data.sample(false, 0.1) .map( t => Vectors.dense( Array(t._6, t._7) ) ) clusterData.cache clusterData.count //returns 60011237 val clusters = KMeans.train(clusterData, 4, 10) |
Fazit
Und was bedeutet das alles? Big Data ist immer noch ein heißes Thema. Hadoop und sein Ökosystem von Tools und Frameworks haben sich zu einer einigermaßen effizienten Technologie für skalierbare Datenverarbeitung entwickelt. Das anfängliche Versprechen von Big Data, dass wir die Welt durch das Zählen von Wörtern beherrschen würden, hat sich nicht ganz bewahrheitet, aber mit komplexeren Modellen können wir sehr interessante Dinge mit Daten tun, die zuvor für andere Zwecke gesammelt wurden. Wir hören nicht mehr so viel von den V's, aber Data Science, maschinelles Lernen und Analytik sind das neue Schwarz. Wohin stecken Sie nun Ihr Geld? Jetzt sind wir wirklich an dem Punkt, an dem wir uns auf datengesteuerte Produkte konzentrieren können: Wir nutzen eine Kombination aus Datenwissenschaft und Technik, um ein besseres Erlebnis für die Kunden zu schaffen. Die Skalierung der Datenverarbeitung ist ein gelöstes Problem. Computer sind in der Tat schnell und billig, oft können Sie mit Daten auf einem handelsüblichen Laptop beginnen. Data Science ist eine echte Sache (und natürlich können wir Ihnen bei den ersten Schritten helfen). Es besteht nun die Möglichkeit, diese Entwicklungen zu besseren Produkten zu kombinieren. Hören Sie auf, über die V's von Big Data zu reden und schließen Sie sich der ersten Welle von Unternehmen an, die tatsächlich von dieser Technologie profitieren. Mein erster Ratschlag: Beginnen Sie mit den Menschen, nicht mit der Technologie. Ohne Menschen, die wissen, wie man die Daten interpretiert und darauf aufbauend Lösungen entwickelt, ist es egal, wie groß Ihre Daten sind. Die technologische Seite der Dinge ist eigentlich ein gelöstes Problem (jedenfalls für die meisten unserer Zwecke). Versuchen Sie, ein Klima zu schaffen, das es Ihnen ermöglicht, Datenwissenschaftler und hochqualifizierte Ingenieure einzustellen (das ist es, was wir tun). Ermutigen Sie zu Innovation und Experimenten. Bauen Sie nicht einfach einen Hadoop-Cluster, nur weil Sie es können. Zweitens: Konzentrieren Sie sich auf die allgemeine Verfügbarkeit von Daten und nicht auf deren Korrektheit. Überlassen Sie es demjenigen, der die Daten verwendet, zu entscheiden, ob sie für den Zweck geeignet sind. Ob Sie es nun Data Hub, Data Lake, Data Warehouse, virtualisierter Datenspeicher oder etwas anderes nennen, Sie brauchen einen zentralen Ort, an dem alle, die mit Daten arbeiten, auf die Rohdaten zugreifen können, die beschreiben, was in Ihrem Unternehmen geschieht. Und nicht zuletzt sollten Sie eine Erfassungsstrategie haben. Die Datenerfassung bei Produkten ist in vielen Fällen ein nachträglicher Gedanke. Oft wird dies dann an externe Dienstleister ausgelagert, aber Sie sollten darauf achten, dass Sie das Eigentum an Ihren eigenen Daten behalten. Wenn Sie eine Website mit hohem Besucheraufkommen haben, aber Ihre Clickstream-Daten über Google Analytics an Google senden, verschenken Sie einen Ihrer Aktivposten und zahlen gleichzeitig dafür (ganz zu schweigen von den rechtlichen und datenschutzrechtlichen Problemen, die entstehen können, wenn Ihre Kundendaten Ihrer Kontrolle entzogen werden).Unsere Ideen
Weitere Blogs




Contact