Artikel
Erschließen Sie die Leistungsfähigkeit Ihrer Daten mit großen Sprachmodellen

Wenn Sie lieber hören als lesen, können Sie sich die Videoversion dieses Artikels auf YouTube ansehen.
Möchten Sie Ihre Daten mit großen Sprachmodellen kombinieren? Um das Beste aus ihnen herauszuholen? Dieser Artikel führt Sie durch die Grundlagen. Bei Xebia kategorisieren wir LLM-fähige Anwendungen in 3 Stufen. In diesem Artikel werden wir eine Anwendung der Stufe 2 behandeln. Lassen Sie uns zunächst erläutern, was wir unter einer Anwendung der Stufe 2 verstehen.
Stufe 1: Einfaches Prompting Bei einer Stufe-1-Anwendung verlassen wir uns ausschließlich auf die Merkmale des Basis-LLMs. Jeder LLM wurde auf einem Datensatz trainiert. Stellen Sie sich eine Anwendung vor, die Ihnen hilft, einen Blogbeitrag oder einen Artikel zu schreiben. Wir können ein LLM verwenden, um Entwürfe für neue Absätze oder Sätze zu liefern. Das LLM braucht nichts weiter als eine Eingabeaufforderung, und es wird darauf reagieren. Modelle wie GPT-3.5 und GPT-4 sind dafür perfekt geeignet.
Stufe 2: Hinzufügen Ihrer Daten Eine Stufe-2-Anwendung baut auf einer Stufe-1-Anwendung auf, ermöglicht es Ihnen aber, Ihre eigenen Daten einzubringen. Wenn Sie z.B. einen Chatbot für Ihren Webshop erstellen möchten, der Benutzern hilft, die richtigen Informationen über Ihre Dienstleistungen zu finden: Sie möchten, dass der Chatbot Ihre Produkte und Dienstleistungen "kennt". Für eine Anwendung der Stufe 2 müssen Sie einen Berührungspunkt zwischen Ihren Daten und dem LLM finden. Dazu später mehr.
Stufe 3: Verbundene Agenten Vielleicht eine der aufregendsten Anwendungen eines Large Language Model: dem LLM zu erlauben, das Steuer zu übernehmen, um eine bestimmte Aufgabe zu lösen. Für Anwendungen der Stufe 3 entwickeln Sie Fähigkeiten oder Plugins, die einem LLM im Wesentlichen "Hände" und "Füße" geben, um Aufgaben auszuführen, die weit über die Möglichkeiten einer Anwendung der Stufe 1 oder 2 hinausgehen. Sie möchten das Internet durchsuchen? Stufe 3. Wollen Sie einen Roboter steuern? Schreiben Sie eine Fähigkeit für ihn. Wollen Sie ein Buch ohne menschliches Zutun schreiben? Das ist eine Level 3 Anwendung!
Ziele & Herausforderungen
Das Ziel einer Level 2-Anwendung ist es, Ergebnisse zu liefern, die nachprüfbar, genau und aktuell sind.
- Aktualität: Die Daten ändern sich ständig. Das kann monatlich, wöchentlich oder sogar jede Sekunde sein. Wenn Sie gerade Ihre Produktlinie überarbeitet haben, möchten Sie, dass Ihr Chatbot darüber Bescheid weiß, anstatt auf das nächste LLM-Update zu warten.
- Genau: Sie möchten, dass Ihre Anwendung die richtigen Informationen enthält und zu 100% korrekt ist.
- Überprüfbar: Das ist vielleicht das Wichtigste, das wir erreichen müssen, und das wir oft vergessen. Wenn Sie mit Hilfe von KI Ergebnisse erzielen, sollten Sie dem Benutzer nicht nur anzeigen, dass dies der Fall ist. Es liegt in Ihrer Verantwortung, dem Benutzer die Möglichkeit zu geben, die Ergebnisse zu verifizieren.
"Es liegt in Ihrer Verantwortung, dem Benutzer eine Möglichkeit zu geben, die Ergebnisse zu überprüfen."
Diese Ziele scheinen zwar einfach zu sein, können aber schwer zu erreichen sein. Denn wenn Sie beginnen, Level 2-Anwendungen zu erstellen, stoßen Sie auf drei Herausforderungen:
1. Wissen Cutoff
Zum Zeitpunkt der Erstellung dieses Artikels ist der Wissensstand von GPT-3.5 Turbo und GPT-4 der April 2023. Das bedeutet, dass die Daten, auf denen der LLM trainiert wurde, bis zu diesem Datum reichen. Wenn Sie über Daten verfügen, die jüngeren Datums sind, müssen Sie einen Weg finden, Ihre Daten mit dem LLM zu kombinieren. Das ist nicht immer ganz einfach und kann eine Herausforderung sein. Es ist noch nicht lange her, da lag dieser Stichtag für das Wissen Jahre in der Vergangenheit. Heute sind es Monate, und in Zukunft werden es sicherlich Wochen oder sogar Tage sein. Da die Ausbildung von Large Language Models jedoch kostspielig ist und viel Zeit in Anspruch nimmt, ist es unwahrscheinlich, dass wir in naher Zukunft ein sekundengenaues Modell sehen werden.
2. Kein Zugriff auf Ihre Daten
Das Trainingsset, das zur Erstellung von GPT-3.5 und GPT-4 verwendet wurde, enthält wahrscheinlich nicht Ihre Daten. Das ist eine gute Nachricht, denn wir verbringen viel Zeit damit, sicherzustellen, dass Personen außerhalb unserer Organisationen keinen Zugriff auf unsere Daten haben. Das bedeutet aber auch, dass das LLM nie mit Ihren Daten in Berührung gekommen ist, wie kann es also Fragen zu Ihren Daten beantworten? Selbst wenn alle Ihre Daten öffentlich sind, können Sie nicht davon ausgehen, dass sie Teil des Trainingssets waren, da ihr genauer Inhalt nie offengelegt wurde.
3. LLMs generieren nur wahrscheinlichen Text
Im Grunde genommen ist ein LLM ein Textgenerator. Er weiß nichts. Er generiert Text, der mit hoher Wahrscheinlichkeit korrekt ist, d.h. wenn ein Mensch ihn liest, ergibt er einen Sinn. Das ist besonders interessant, wenn man bedenkt, wie viele Menschen ChatGPT als Suchmaschine verwenden. Ein LLM kann Text erzeugen, der korrekt zu sein scheint, aber nicht auf der Wahrheit beruht. Dieses Verhalten haben wir früher als "Halluzination" bezeichnet, aber da wir das LLM nicht vermenschlichen wollen, ist es kein Mensch, der halluzinieren kann, es lügt nicht, es tut nur das, wofür es gebaut wurde, nämlich wahrscheinlichen Text zu erzeugen. Das ist auch der Grund, warum eines unserer Ziele darin besteht, unseren Nutzern die Möglichkeit zu geben, die Ergebnisse zu überprüfen. Was wir natürlich alle tun, nachdem ChatGPT uns eine Antwort gegeben hat, nicht wahr?
Was können wir tun?
Wenn Sie bereits einige Zeit damit verbracht haben, über Azure OpenAI zu lesen, sind Sie auf den Begriff "Feinabstimmung" gestoßen. Die Feinabstimmung ermöglicht es Ihnen, ein Basismodell (wie GPT-3.5 Turbo oder die älteren Babbage- und Davinci-Modelle) zu nehmen und darauf eine weitere Schicht mit Ihren eigenen Daten zu trainieren. Wenn dies also die Lösung ist, warum sprechen wir dann immer noch über die Herausforderungen? Das liegt daran, dass zwar Ihre Daten mit einem LLM kombiniert werden, die meisten Herausforderungen aber dieselben bleiben.
Ein Vorteil der Feinabstimmung ist, dass Sie dem LLM die Sprache Ihres Fachgebiets beibringen. Vielleicht arbeiten Sie in einem Sektor, in dem es viel Jargon oder eine sehr spezifische Terminologie und Abkürzungen gibt. Die Feinabstimmung kann dem LLM helfen, Ihre Sprache besser zu verstehen.
Ein großes Problem bei der Feinabstimmung ist, dass die Daten, die Sie haben, egal wie groß Ihr Datensatz ist, nur ein Sandkorn im Vergleich zu der Datenwüste sind, auf der der LLM trainiert wurde. Für die Feinabstimmung werden Ihre Daten bei der Feinabstimmung "wichtiger" gemacht. Dieser Prozess erfolgt durch Low Rank Adaption (LoRA), mit der ein neues Modell erstellt werden kann, ohne dass der gesamte Datensatz neu trainiert werden muss. Dies kann die Leistung des Gesamtmodells beeinflussen und die Wahrscheinlichkeit erhöhen, dass es Wörter aus Ihrem Datensatz generiert. Sie werden die Ergebnisse trotzdem nicht überprüfen können, denn ein LLM weiß nicht, woher es seine Informationen hat.
Um das Modell auf dem neuesten Stand zu halten, müssen Sie es außerdem häufig feinjustieren. Das ist nicht immer machbar. Die Feinabstimmung ist kostspielig und kann schwer zu pflegen sein. Wenn Sie viele Daten haben, müssen Sie möglicherweise viel Rechenleistung für die Feinabstimmung Ihres Modells investieren. Und wenn sich Ihre Daten häufig ändern, müssen Sie Ihr Modell häufig feinabstimmen. Das ist nicht immer machbar.
Betrachten Sie das folgende Zitat, das direkt aus der Azure OpenAI-Dokumentation stammt:
Häufige Anzeichen dafür, dass Sie noch nicht bereit für die Feinabstimmung sind:
- Sie beginnen mit der Feinabstimmung, ohne andere Techniken getestet zu haben.
Mit anderen Worten: Implementieren Sie zuerst andere Lösungen, bevor Sie mit der Feinabstimmung beginnen.
Die Wahl des richtigen Ansatzes
Azure AI Studio
Während wir die Lösung erforschen, sollten wir das Problem anschaulich darstellen. Über das neue Azure AI Studio erhalten wir Zugang zu einer Spielplatzumgebung, in der wir genau sehen können, wozu ein LLM in der Lage ist. In dieser Spielumgebung stehen uns verschiedene Parameter zur Verfügung, die wir verwenden können. In Abbildung 1 beschränken wir die Antwort auf eine bestimmte Anzahl von Token und verwenden die Standardtemperatur von 0,7. Der Temperaturparameter steuert die Zufälligkeit der Ausgabe. Je höher Sie ihn einstellen, desto wahrscheinlicher ist es, dass der LLM unerwartete Ergebnisse liefert. Eine Standardeinstellung von 0,7 eignet sich hervorragend für ein Chat-Erlebnis, bei dem Sie keine Daten haben, auf die Sie den LLM stützen können. 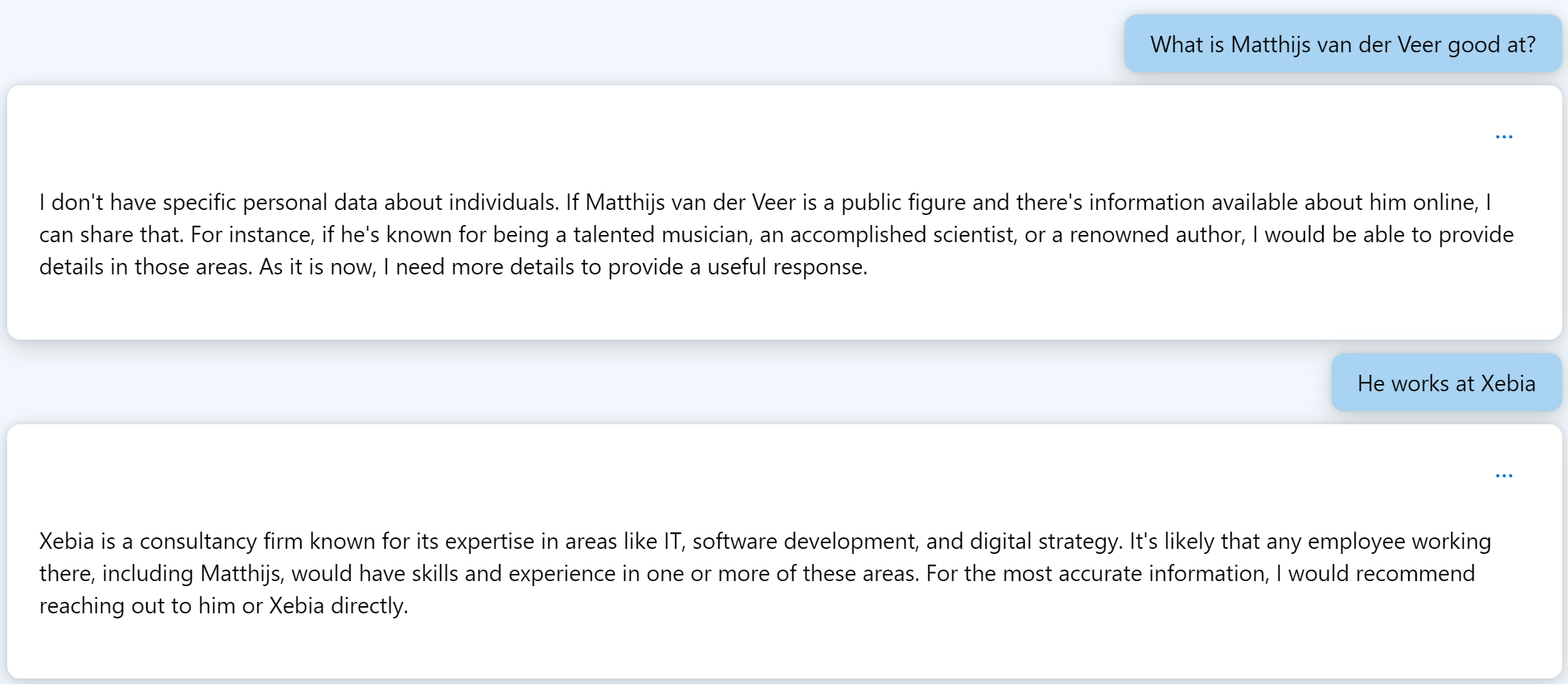 Abbildung 1. Fragen zu meiner Person in Azure AI Studio.
Abbildung 1. Fragen zu meiner Person in Azure AI Studio.
In Abbildung 1 können Sie sehen, dass ich dem Modell eine einfache Frage gestellt habe: "Was kann Matthijs van der Veer gut?". Ich bin mir ziemlich sicher, dass mein Name im Originaldatensatz enthalten ist, mit dem das Modell trainiert wurde. Ich habe einen Blog, ein StackOverflow-Konto und ich teile meinen Namen mit einem Filmemacher und Musiker. Doch obwohl mein Name wahrscheinlich im Originaldatensatz des GPT-4-Modells enthalten ist, weiß ich, dass mein Name wahrscheinlich nicht so häufig vorkommt. Als das LLM unweigerlich antwortet, dass es nicht weiß, wer Matthijs ist (und meine Gefühle unnötig verletzt), füge ich hinzu: "Er arbeitet bei Xebia". Aber selbst mit diesem zusätzlichen Kontext fährt das LLM fort, mich zu verleumden, indem es sagt, ich sei keine bekannte öffentliche Person. Wir sehen auch, warum es wichtig ist, den LLM auf den Boden der Tatsachen zu bringen, denn in seiner Antwort beginnt er, Annahmen über meine Fähigkeiten zu treffen. Dies ist ein großartiges Beispiel dafür, dass das LLM einen wahrscheinlichen Text erstellt, aber nicht auf der Grundlage der Wahrheit.
Lassen Sie uns also diese Ergebnisse verbessern. Angenommen, ich möchte einen Chat einrichten, in dem ich mich über die Mitarbeiter von Xebia informieren kann. Das ist für ein Beratungsunternehmen wie unseres äußerst nützlich. Jeder Mitarbeiter verfügt über einzigartige Fähigkeiten, und jeder ist auf seiner persönlichen Autoritätsmission unterwegs. Wenn also ein neues Projekt ansteht, kann diese Art von Chatbot extrem hilfreich sein, um die richtige Person für den Job zu finden. Um das Modell auf eine solide Grundlage zu stellen, benötige ich einen Datensatz, der die Berufserfahrung und die Wünsche aller unserer Berater enthält. Und ich möchte nicht erst Zeit mit der Codierung der Anwendung verschwenden, sondern muss erst herausfinden, wie wertvoll mein Datensatz ist. Glücklicherweise verfügt Azure AI Studio über eine Funktion, mit der ich mein Dataset in 5 Minuten testen kann. Das ist der schnellste Weg, Ihre Daten zu testen.
In Azure AI Studio gibt es eine Funktion namens "Fügen Sie Ihre Daten hinzu", mit der Sie dem Spielplatz einen Datensatz hinzufügen können. Sie können dann die gleiche Chat-Erfahrung machen wie vorher, aber jetzt sollten die Ergebnisse auf der Wahrheit beruhen. Wenn Sie Ihre Daten hinzufügen, können Sie aus einer Reihe von Optionen wählen. Siehe Abbildung 2.
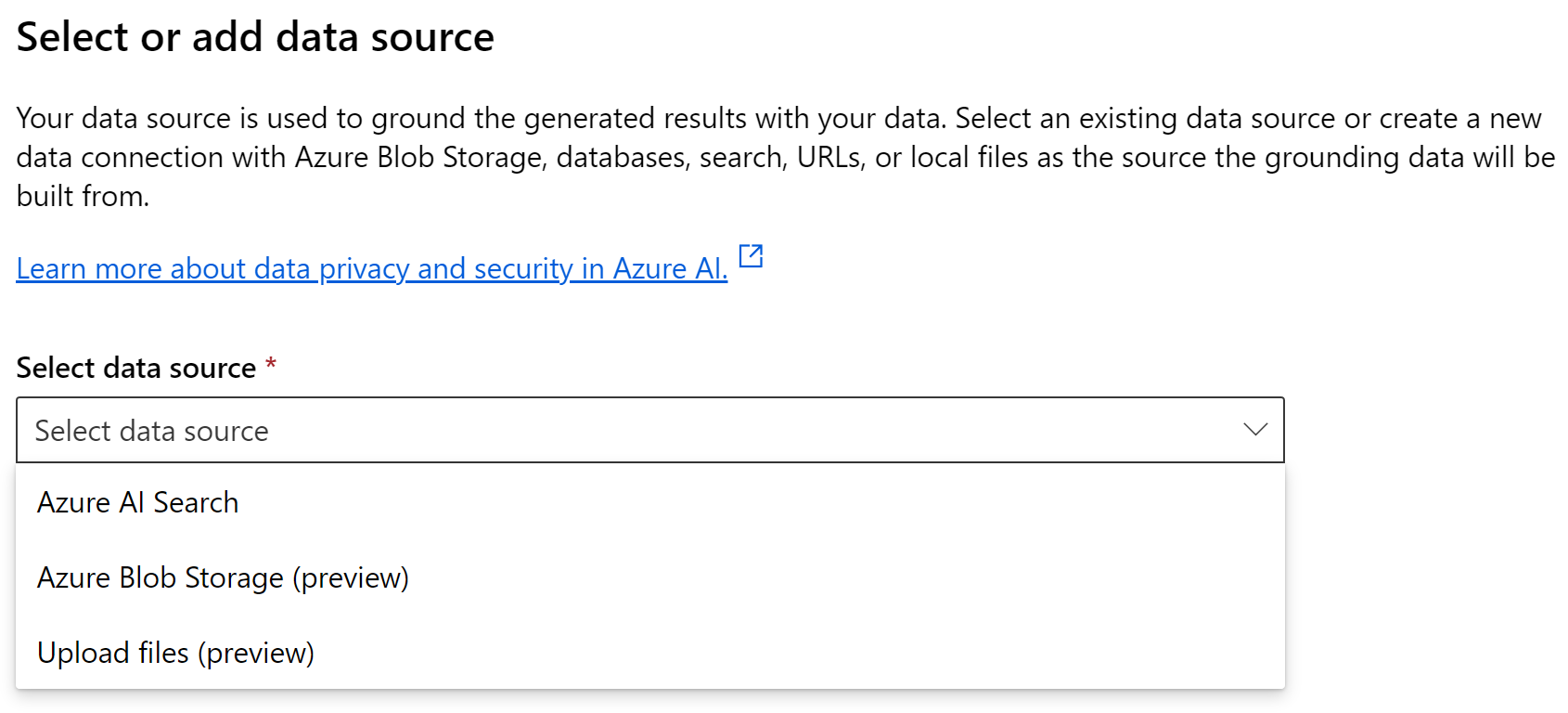 Abbildung 2. Auswahl einer Datenquelle.
Abbildung 2. Auswahl einer Datenquelle.
In Abbildung 2 sehen Sie, dass wir wählen können, ob wir Dateien hochladen, Blob-Speicher verwenden oder mit Azure Search kommunizieren möchten. In Zukunft werden Sie auch andere Optionen sehen, wie CosmosDB und Webhook-Unterstützung. Diese Optionen befinden sich derzeit in der Vorschau. Wenn Sie dies lesen, könnten sie bereits verfügbar sein. Wenn Sie diese Funktion zum ersten Mal verwenden, wählen Sie "Dateien hochladen". Wenn Sie diese Funktion nutzen, erstellen Sie ein Blob-Storage-Konto und eine neue Azure AI Search-Ressource. Bitte stellen Sie sicher, dass Sie eine Basic AI Search Ressource erstellen, da die Standardstufe für Testzwecke sehr teuer ist. Im folgenden kurzen Assistenten aktivieren Sie die Vektorsuche und lassen alle anderen Einstellungen auf Standard. Wenn Sie den Assistenten beendet haben, wird Azure AI Search alle hochgeladenen Dateien schnell indizieren und wir können mit der Arbeit beginnen.
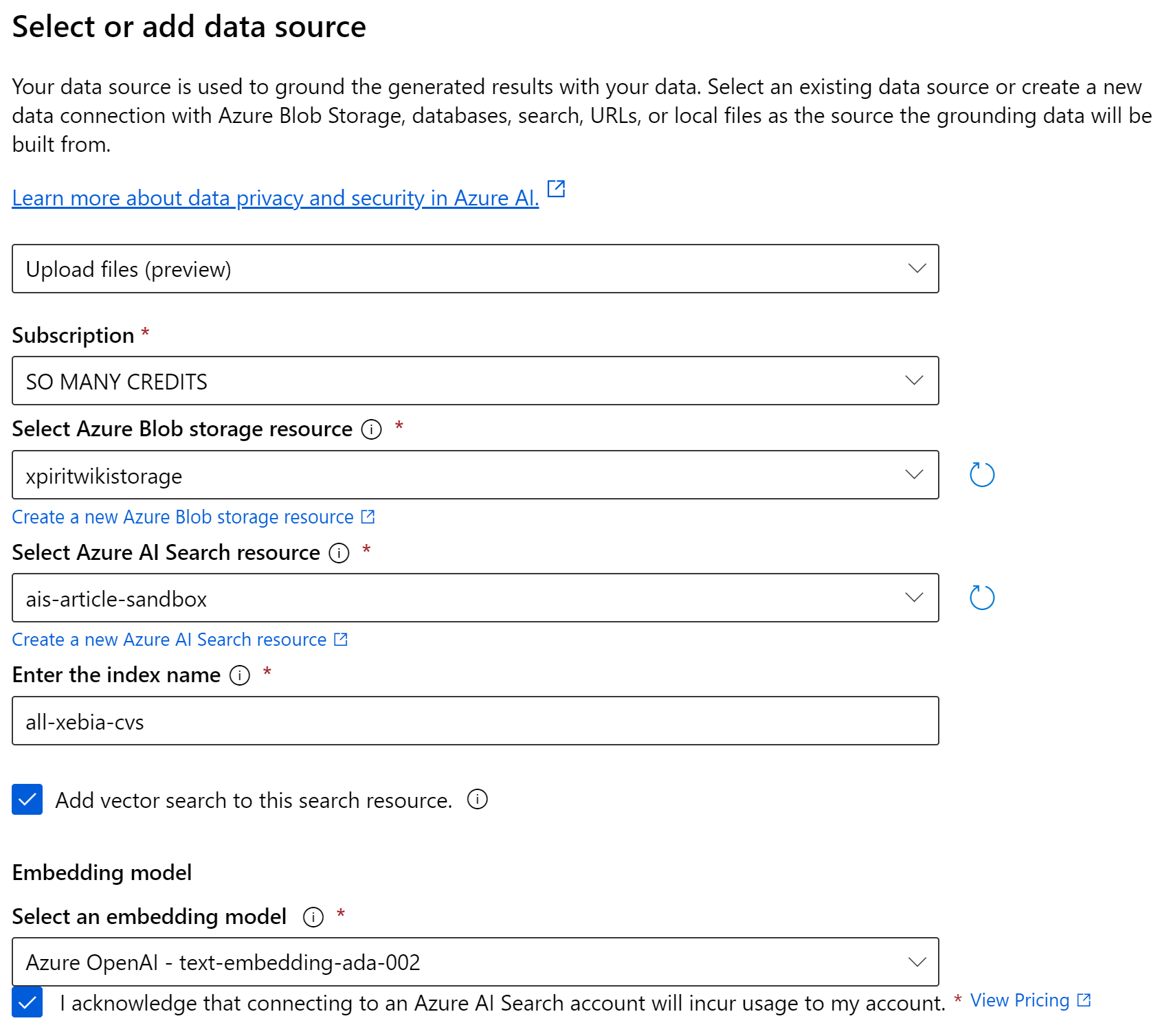 Abbildung 3. Hinzufügen Ihrer Daten zum Spielplatz.
Abbildung 3. Hinzufügen Ihrer Daten zum Spielplatz.
Lassen Sie uns nun noch einmal mit unserem LLM sprechen. Ich werde die erste Frage etwas erschweren, indem ich meinen Nachnamen nicht nenne. Wenn ich frage "Was kann Matthijs gut?", sollte der LLM nun in der Lage sein, eine Antwort zu geben, die auf der Wahrheit beruht. Wenn Sie sich Abbildung 4 ansehen, werden Sie sehen, dass wir eine sehr detaillierte Antwort erhalten. Was ebenfalls auffällt, ist, dass die Antwort einen Inline-Link zur Quelle der Informationen enthält. Dies ist eine gute Möglichkeit, die Ergebnisse zu überprüfen. Dies ist ein gutes Beispiel dafür, wie Sie Ihren Datensatz in 5 Minuten testen können. Wenn Sie dies mit Ihren eigenen Daten tun, vergessen Sie nicht, verschiedene Fragen und Aufforderungen zu testen. Sie möchten sicherstellen, dass Ihre Daten wertvoll sind und sich die Investition in eine Anwendung lohnt.
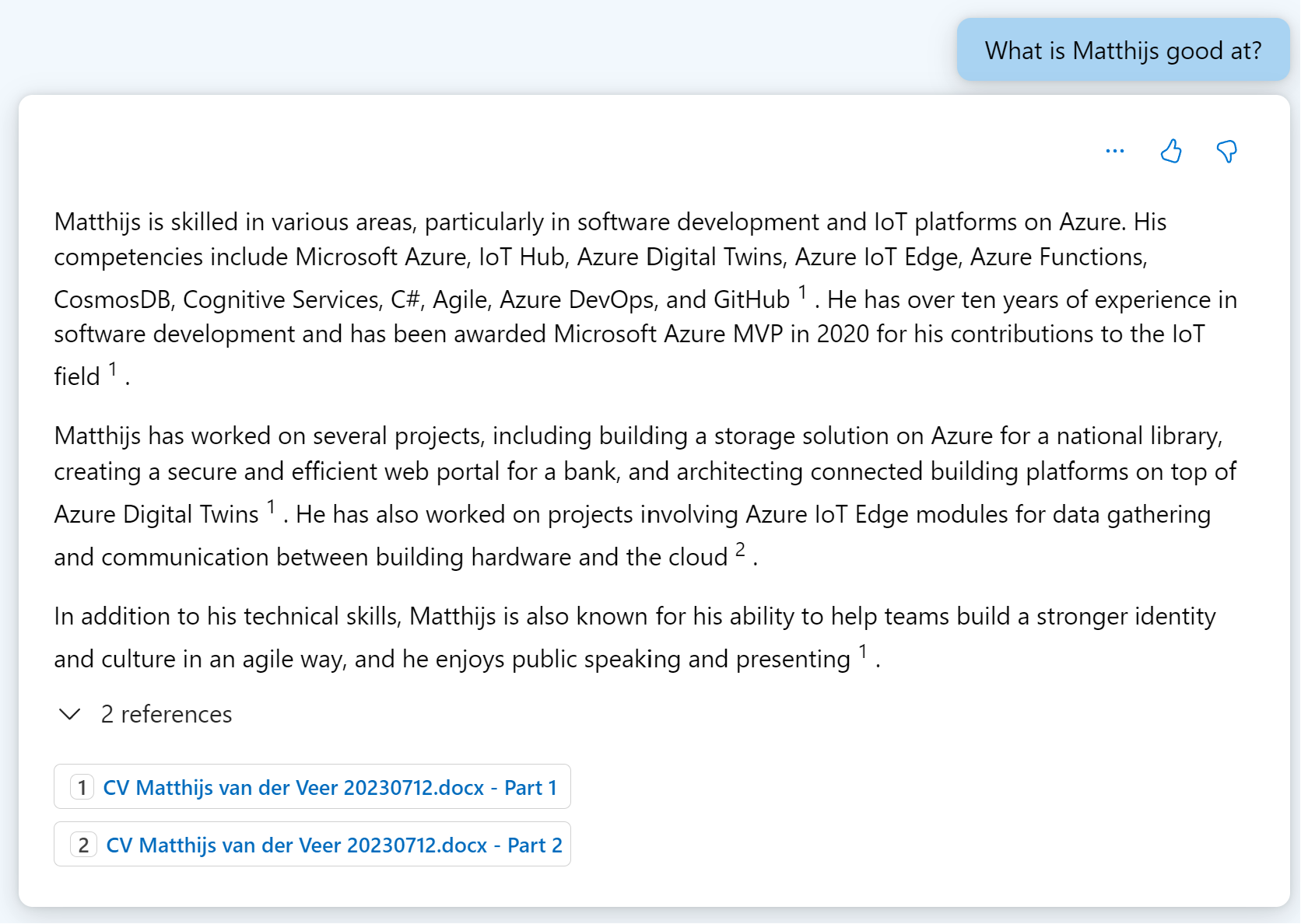
Abruf Erweiterte Generation
Die Ergebnisse, die wir gerade vom LLM gesehen haben, sind großartig. Es wurden aktuelle Daten verwendet, die Ergebnisse waren überprüfbar und genau. Es löst alle unsere Herausforderungen. Aber es reicht nicht aus, Azure AI Studio einfach nur zu verwenden und Feierabend zu machen. Lassen Sie uns darüber sprechen, wie das funktioniert, damit auch Sie Ihre eigenen Anwendungen erstellen können. Das Muster, das die Azure AI Studio-Funktion ermöglicht, heißt Retrieval Augmented Generation. Das Muster ist einfach, aber leistungsstark. Damit ein LLM in der Lage ist, Fragen zu unseren Daten zu beantworten, fügen wir sie einfach der Eingabeaufforderung hinzu. Dies ist der "erweiterte" Teil der Geschichte. Im vorangegangenen Beispiel habe ich eine Frage gestellt, die mit meinem Lebenslauf beantwortet werden kann. Wenn ich ihn also zur Eingabeaufforderung hinzufüge, kann der LLM ihn verwenden, um meine Frage zu beantworten.
Der Teil "Abrufen" ist hier allerdings der Schlüssel. Wenn ich eine Frage zu einer Person in meinem Unternehmen habe, müsste ich alle Lebensläufe aller Personen in meinem Unternehmen an den LLM weiterleiten. Das ist wegen der "Kontextgrenze" nicht machbar. Jeder LLM hat ein solches Limit, und es wird in einer maximalen Anzahl von Token ausgedrückt.
| Modelle | Kontext | Eingabe (pro 1.000 Token) | Ausgabe (pro 1.000 Token) |
|---|---|---|---|
| GPT-3.5-Turbo-0125 | 16K | $0.0005 | $0.0015 |
| GPT-3.5-Turbo-Anleitung | 4K | $0.0015 | $0.002 |
| GPT-4-Turbo | 128K | $0.01 | $0.03 |
| GPT-4-Turbo-Vision | 128K | $0.01 | $0.03 |
| GPT-4 | 8K | $0.03 | $0.06 |
| GPT-4 | 32K | $0.06 | $0.12 |
| GPT-4 Turbo | 128K | $0.01 | $0.03 |
Ein Token ist ein Wort oder ein Teil eines Wortes. Anstatt auf die Tokenisierung einzugehen, sagen wir einfach, dass mein Lebenslauf etwa 1.300 Token umfasst. Zum Zeitpunkt der Erstellung dieses Artikels hat GPT-4 Turbo ein großzügiges Kontextlimit von 128 Tausend Token. Es könnte fast 100 Lebensläufe im Kontext akzeptieren. Aber das würde bedeuten, dass mich jede Anfrage 1,28 $ kosten würde und der LLM keine Ausgabe erstellen könnte, da dies ebenfalls Teil des gleichen Token-Limits ist. Sie können einfach nicht alle Ihre Daten in die Eingabeaufforderung aufnehmen.
Was wir brauchen, ist der "Retrieval"-Teil von RAG. Es gibt eine Art von Software, die sich dadurch auszeichnet, dass sie die Frage eines Benutzers in Daten verwandelt, die die Antwort auf diese Frage enthalten. Wenn Sie jetzt denken "Suchmaschine!", dann klopfen Sie sich bitte auf die Schulter! Anstatt Ihren gesamten Datensatz zur Eingabeaufforderung hinzuzufügen, füttern wir eine Suchmaschine damit und erstellen einen Index, den wir durchsuchen können. Der Prozess der Umwandlung von Daten in einen Index kann mit den folgenden Schritten beschrieben werden:
Extrahieren - Partitionieren - Transformieren - Persistieren
Bei der Extraktion geht es darum, die Daten aus der Quelle herauszuholen. Dies kann mit einem einfachen Skript oder einer komplexeren Datenpipeline geschehen. Um es einfach zu halten, ist die Extraktion der Akt des Lesens der Dokumente. Es gibt Bibliotheken, die Sie verwenden können, um Daten aus PDF- oder Office-Dateien zu extrahieren, oder Sie können die integrierten Funktionen von Azure AI Search nutzen, um dies für Sie zu tun.
Danach müssen wir die Daten partitionieren. Wir müssen die extrahierten Dokumente in Partitionen, oder "Chunks", aufteilen. Diese Chunks können groß oder klein sein, je nach Anwendungsfall. Eine gute Faustregel für die Größe eines Chunks ist, ihn einfach zu lesen. Wenn der Chunk für sich genommen einen Sinn ergibt, ist er für einen LLM nützlich. Wenn Sie nicht erkennen können, worum es sich handelt, ist der Brocken möglicherweise zu klein. Wenn ich meinen Lebenslauf in einzelne Seiten aufteile, enthält er immer noch genug Daten, um sinnvoll zu sein, aber wenn ich eine Rechnung in einzelne Posten aufteile, ist das vielleicht nicht sinnvoll. Eine gute Praxis ist es, Chunks mit einer gewissen Überlappung zu versehen, so dass der LLM die Antwort auf eine Frage, die sich am Rande eines Chunks befindet, immer noch finden kann, wenn sie in einem anderen Chunk steht, der dem Kontext hinzugefügt wurde.
Der nächste Schritt ist das Transformieren dieser Chunks. Eine gängige Methode zum Speichern von Chunks ist die Verwendung einer Vektordarstellung. Dies ist eine mathematische Darstellung des Textes. Einfach ausgedrückt: Text, der die gleiche Bedeutung hat, liegt sehr nahe beieinander, wenn er in einen Vektor übersetzt wird. Das folgende Diagramm zeigt zum Beispiel Wörter in einem 2-dimensionalen Raum. Diese Wörter sind ein Vektor mit 2 Dimensionen, abgestuft nach dem Grad der "Nahrung" und wie französisch sie sind. Ähnliche Wörter werden in Gruppen zusammengefasst. Stellen Sie sich nun vor, dass wir anstelle von 2 Dimensionen Vektoren mit 1.536 Dimensionen erzeugen! Glücklicherweise müssen wir diese Berechnungen nicht selbst durchführen, denn OpenAI verfügt über mehrere Modelle, die dafür verwendet werden können. Das Modell text-embedding-ada-002 von OpenAI wird derzeit am häufigsten verwendet, aber Sie werden seine Nachfolger text-embedding-3-small und text-embedding-3-large in Zukunft immer häufiger sehen.
quadrantChart
title French vs Food
x-axis Not very French --> Very French
y-axis Not Food --> Food
quadrant-1 French Food
quadrant-2 Not French Food
quadrant-3 Not Food, Not French
quadrant-4 Not Food, Still French
Baguette: [0.8, 0.9]
Croissant: [0.7, 0.8]
Eiffel Tower: [0.9, 0.1]
Hot Dog: [0.1, 0.9]
Windmill: [0.1, 0.1]
Lion: [0.2, 0.2]
Lyon: [0.8, 0.2]Der letzte Schritt besteht darin, diese Daten zu speichern, damit wir sie später wieder abrufen können. Sie möchten den Originaltext zusammen mit seinem Vektor speichern. So können wir den Text später wiederfinden, wenn wir ihn brauchen. Dies kann in einer Vektordatenbank Ihrer Wahl geschehen, aber die besten Ergebnisse erzielen Sie mit einer Suchmaschine, die sowohl eine Vektor- als auch eine Stichwortsuche durchführen kann. Azure AI Search ist ein hervorragendes Beispiel dafür.
Mit unseren Vektoren können wir nun jede beliebige Benutzerfrage nehmen und die relevantesten Abschnitte finden. Dazu wandeln wir die Frage einfach in einen Vektor um, und zwar mit demselben Modell, mit dem wir unseren Text in Vektoren umgewandelt haben. Anschließend suchen wir in unserem Index nach den ähnlichsten Vektoren. So erhalten wir die Chunks, die für die Frage relevant sind. Danach müssen wir einen Prompt erstellen, der die Frage des Benutzers, die Chunks und einen Systemprompt enthält, der dem LLM erklärt, was er zu tun hat. Dieser Systemprompt ist eine Kunst, die in einer Level 1-Anwendung gemeistert werden muss. Nachfolgend finden Sie ein Beispiel für einen Prompt, der die Chunks enthält. Bitte beachten Sie, dass sehr wichtige Teile wie Sicherheit und Tonfall ausgelassen wurden.
You are the Xebia People Assistant. Users can ask you about people's skills,
or who to staff on an assignment.
### Context
Base your answer on the following data, do not answer questions that are not
in the data.
{{chunks}}
### User question
{{user-question}}
### Instructions about safety, jailbreaking, etcMit dieser Aufforderung weisen wir das LLM an, die Frage des Benutzers nur mit dem vorhandenen Wissen zu beantworten. Wir müssen immer noch berücksichtigen, dass das Modell dazu neigt, etwas Unerwartetes zu erzeugen. Es wäre ratsam, die Temperatur für Antworten mit dieser Aufforderung niedriger anzusetzen. Es gibt viel über die Wahl der richtigen Parameter zu sagen, genug, um einen ganzen Artikel damit zu füllen. Das Wichtigste ist, dass manuelle Tests nur einen geringen Nutzen haben. Wenn Sie sicher sein wollen, dass Ihre Eingabeaufforderung robust genug ist, um eventuellen Angriffen oder einfach nur ungeschickten Fragen standzuhalten, können Sie Prompt Flow und seine Bewertungsfunktionen verwenden. Damit können Sie Ihre Eingabeaufforderung schnell durchgehen, um herauszufinden, ob sie für den realen Einsatz geeignet ist.
Mit RAG können Benutzer zwar Antworten auf diese Fragen erhalten, aber es ist wichtig, dass Sie wissen, welche Fragen Sie damit beantworten können. In meinem Beispiel habe ich nach bestimmten Themen gefragt, die in dem Datensatz vorhanden sind. Hier kann RAG wirklich glänzen. Wenn ich Aggregationsfragen stellen würde, wie z.B. "Wie viele Personen arbeiten bei Xebia" oder "Listen Sie alle Personen auf, die C# können", würden wir nicht die richtigen Ergebnisse erhalten. Diese Fragen eignen sich besser für eine Anwendung der Stufe 3, bei der wir eine Fähigkeit zur Ausführung einer Aufgabe verwenden können. Aber für den Moment haben wir eine großartige Level 2-Anwendung, die genaue, aktuelle und überprüfbare Ergebnisse liefert.
Fazit
Große Sprachmodelle haben die Art und Weise, wie wir KI betrachten, verändert, sie haben fast magische Eigenschaften. Wir schwärmen von ihnen, weil sie Fragen auf unterhaltsame Weise beantworten können. Aber Sie müssen bedenken, dass ein LLM nur wahrscheinlichen Text erzeugt. Lassen Sie uns also dem Modell helfen. Ermöglichen Sie dem Modell den Zugriff auf Ihre Daten, indem Sie sie in Ihrer Eingabeaufforderung bereitstellen. Versorgen Sie es mit aktuellem Kontext, damit es auf dem Boden der Tatsachen steht. Wenn Sie dem Modell hochwertigen Kontext und eine robuste Eingabeaufforderung zur Verfügung stellen, werden die Ergebnisse Ihren Benutzern fast magisch erscheinen. Retrieval Augmented Generation kann ein mächtiges Werkzeug sein, wenn man es richtig einsetzt. Und was auch immer Sie tun, bieten Sie Ihren Benutzern immer eine Möglichkeit, die Ergebnisse zu überprüfen.
Wenn Sie bereit sind, eine Level 2-Anwendung zu erstellen, hat mein Kollege Duncan eine tolle Einstiegsanwendung in C# erstellt. Sie können sie hier finden.
Dieser Artikel ist Teil von XPRT.#16. Sie können das Magazin hier herunterladen.

Tauchen Sie tiefer in die Welt der Innovation ein - besuchen Sieunsere Bibliothek'Your Essential Guides to Innovation and Expertise' und greifen Sie auf eine Sammlung von Magazinen und eBooks zu, die Ihr Verständnis von Spitzentechnologie verbessern und Sie zu Ihrer nächsten großen Idee inspirieren werden.




Contact