Artikel
Entwerfen der richtigen Datenarchitektur

Was ist Datenarchitektur?
Laut TOGAF ist die Datenarchitektur ein strukturierter und umfassender Ansatz für die Datenverwaltung und ermöglicht die effektive Nutzung von Daten, um deren Wettbewerbsvorteile zu nutzen. Wenn sich Unternehmen auf eine digitale Reise begeben und eine umfassende architektonische Umgestaltung vornehmen, ist es ebenso wichtig, die Probleme der Datenverwaltung zu verstehen und anzugehen. Einige der Bereiche, die Aufmerksamkeit erfordern, sind:
- Datenverwaltung: Dies ist ein riesiger Bereich, aber auf einer hohen Ebene umfasst er die Definition der Stamm- und Referenzdaten und die Art und Weise, wie die Organisation ihre Datenbestände erstellt, verwaltet, speichert und Berichte erstellt.
- Datenmigration: Mit Mit dem Aufkommen der Cloud ist dies einer der ersten Schritte auf dem Weg zur Datenmodernisierung. Wenn Anwendungen (und damit Daten) in die Cloud verlagert werden, müssen auch die zugehörigen Stamm-, Transaktions- (historischen) und Referenzdaten migriert werden.
- Datenverwaltung: Es geht darum, die Organisationsstruktur und die wichtigsten Interessengruppen für die Verwaltung und den Besitz der Daten zu ermitteln, die richtigen Tools für die Transformation bereitzustellen und sicherzustellen, dass die richtigen Fähigkeiten vorhanden sind. Die Datenqualität ist ein Bereich, dem oft nicht viel Aufmerksamkeit geschenkt wird oder der übersehen wird.
Die Entwicklung der richtigen Datenarchitektur erfordert die Einhaltung der Datenprinzipien. Angesichts des exponentiellen Datenwachstums, das jeden Tag zu verzeichnen ist, werden diese Prinzipien bei der Datentransformation noch wichtiger:
- Daten sind ein Vermögenswert: Da Daten die Grundlage jeder Entscheidungsfindung sind, müssen sie gesammelt, umgewandelt und bei Bedarf zur Verfügung gestellt werden.
- Daten werden gemeinsam genutzt: Das Endziel von Daten ist es, sie dem Unternehmen für die Entscheidungsfindung zur Verfügung zu stellen. Dies muss zeitnah geschehen und gleichzeitig sicherstellen, dass die Daten korrekt sind und man ihnen vertrauen kann. Die Geschwindigkeit der Datenerfassung und -verarbeitung bei gleichzeitiger Gewährleistung einer einzigen Wahrheitsquelle ist entscheidend.
- Die Daten sind zugänglich: Die Unternehmen benötigen Zugang zu den Daten. Diesem Wunsch muss rechtzeitig entsprochen werden, damit die Benutzer im gesamten Unternehmen datengestützte Entscheidungen treffen können. Gleichzeitig müssen die Zugriffsrechte klar definiert werden, ebenso wie der Mechanismus für die gemeinsame Nutzung sensibler Daten, um Missbrauch zu verhindern.
- Datentreuhänder: Dateneigentümer, vorzugsweise Geschäftsleute, sollten einbezogen werden, um sicherzustellen, dass die Datendefinitionen korrekt und konsistent sind und die Integrität gewahrt bleibt.
- Datensicherheit: Dies ist einer der wichtigsten Aspekte, die bei der Gestaltung der Datenarchitektur berücksichtigt werden müssen. Datenschutz und Compliance sind für ein Unternehmen von entscheidender Bedeutung, um unbefugten Zugriff sowie den Schutz von vorentscheidenden, sensiblen, quellenauswahlsensiblen und geschützten Informationen zu verhindern.
- Gemeinsames Vokabular und Datendefinitionen: Damit die Datenelemente im gesamten Unternehmen eindeutig verstanden werden, müssen die Definitionen einheitlich sein. Dies ist auch für den Datenaustausch und die Schnittstellensysteme erforderlich. Eine gemeinsame Definition ermöglicht es den Geschäftsanwendern, den Daten zu vertrauen und sie zu nutzen.
Komponenten der Datenarchitektur
Die Komponenten, aus denen sich eine Datenarchitektur zusammensetzt, haben sich im Laufe der Zeit weiterentwickelt, da sich die Technologie verändert und weiterentwickelt hat. Laut BMC gehören zu den Komponenten einer modernen Datenarchitektur unter anderem:
- Daten-Pipelines: Datenpipelines definieren die Art und Weise, wie die Daten aufgenommen, gespeichert, transformiert, analysiert und bereitgestellt werden. Datenpipelines müssen auch so orchestriert werden, dass sie in Stapeln laufen oder Daten kontinuierlich streamen.
- Cloud-Speicher: Cloud-Speicher ermöglichen eine kostengünstige und dauerhafte Speicherung aller Unternehmensdaten. Data Lakes bieten einen gemeinsamen Speicherpunkt für Daten, die aus verschiedenen Quellen stammen.
- Cloud Computing: Für Unternehmen, die sich bereits auf dem Weg in die Cloud befinden, ist die Verwendung von No-Code-ETL-Tools (ADF, Glue), Big Data und Spark Processing Engines bereits Standard.
- API: APIs sind eine der am weitesten verbreiteten Möglichkeiten für die gemeinsame Nutzung von Daten und ermöglichen eine einfache Integration, Sicherheit und Automatisierung.
- KI und ML-Modelle: Modelle des maschinellen Lernens sind heute auf allen Ebenen und in allen Aspekten der Daten eingebettet und beschränken sich nicht nur auf die Verwendung durch das Unternehmen zur Entscheidungsfindung. Sie werden in großem Umfang zur Kennzeichnung, Datenerfassung, Sicherstellung der Datenqualität usw. eingesetzt.
- Daten-Streaming: Die geschäftlichen Anforderungen verlagern sich auf Echtzeit- und Streaming-Datenanwendungen, die eine kontinuierliche Aufnahme und Bereitstellung der Daten für Analysen in Echtzeit erfordern.
- Container-Orchestrierung: Container werden zu einem Kernstück des Designs und der Architektur von Microservices. Sie ermöglichen eine einfachere Paketierung und sind sicher und einfach zu implementieren. Die Verwaltung des gesamten Lebenszyklus kann jedoch manchmal eine Herausforderung sein, insbesondere in einem großen Unternehmen.
- Echtzeit-Analysen: Das Paradigma verschiebt sich hin zu ereignisgesteuerten Architekturen und der Fähigkeit, Echtzeit-Analysen zu liefern. Die Fähigkeit, Analysen für neue Daten durchzuführen, sobald diese in der Umgebung eintreffen, ist zu einer der Kernkomponenten einer modernen Datenarchitektur geworden.
Warum brauchen wir ein Datenarchitekturmodell?
Die Datenarchitekturen haben sich weiterentwickelt. In der Vergangenheit waren sie weniger kompliziert, vor allem wegen der strukturierten Daten aus Transaktionssystemen. Analytische Daten wurden hauptsächlich im Data Warehouse in Form eines Sternschemas gespeichert, wobei manchmal kleinere Marts für einzelne Geschäftsbereiche erstellt wurden.
Mit dem Aufkommen von Big Data, das zu halbstrukturierten und unstrukturierten Daten führte, waren die Speicher- und Rechenmechanismen betroffen. Data Lakes (und jetzt Lakehouse) entstanden und der Ingestion-Mechanismus verlagerte sich von ETL zu ELT.
Die nächste Verschiebung kam in Form von Stream Processing und ereignisgesteuerten Architekturen, die zu Echtzeit- und komplexeren Datenarchitekturen führten. Die Cloud brachte eine weitere Dimension mit sich, in der die Daten vergleichsweise kostengünstig gespeichert und verarbeitet werden konnten, allerdings nicht ohne Bedenken hinsichtlich der Einhaltung von Datenrichtlinien und der Sicherheit.
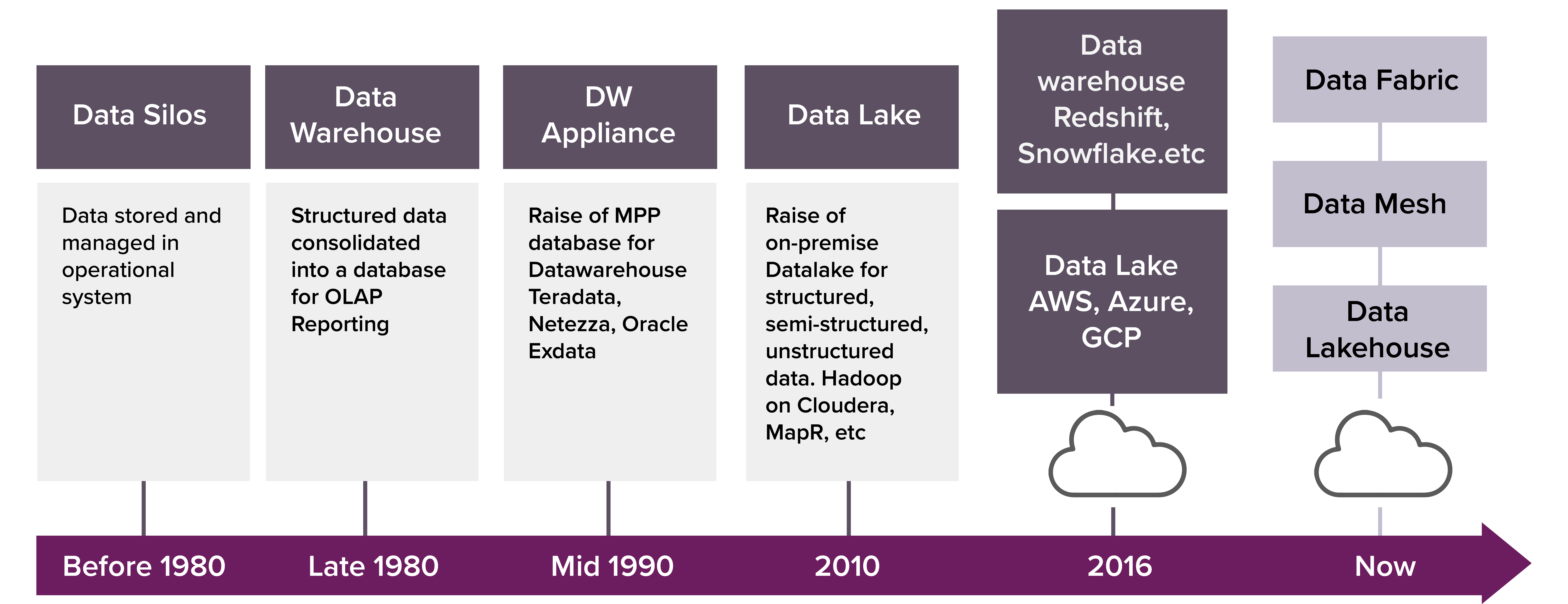 Bildquelle: Medium
Bildquelle: Medium
Maschinelles Lernen und fortschrittliche Analysen haben sich durchgesetzt, und fast alle Unternehmen möchten sie in ihre tägliche Entscheidungsfindung einbeziehen, um ihre Geschäftsprozesse zu verbessern. Dies ist jedoch mit den alten Datenplattformen und der begrenzten Rechenleistung, über die sie (möglicherweise) verfügen, nicht möglich. Die traditionellen monolithischen Systeme und die Altsysteme sind nicht in der Lage, die notwendige Infrastruktur bereitzustellen, um die groß angelegten maschinellen Lernmodelle auszuführen und die fortschrittlichen Analysemöglichkeiten voll auszuschöpfen. Beispiele für moderne Datenplattformen Dazu gehören die öffentlichen Cloud-Anbieter, wie Microsoft Azure, AWS und Google oder die On-Premise-Plattformen, wie Cloudera CDP. Die zugrundeliegenden Prinzipien für diese Datenarchitekturen bleiben jedoch dieselben.
In der heutigen Ära des Datenüberflusses besteht eine der größten Herausforderungen darin, sicherzustellen, dass die Daten für alle Arbeitslasten verfügbar und zugänglich sind. Die Auffindbarkeit von Daten, Governance und Zuverlässigkeit sind heute einige der wichtigsten Herausforderungen, und die Datenverwaltungslösung muss diese Herausforderungen/Bedenken in einem hybriden, Multi-Cloud-Ökosystem angehen.
Die Architekturmodelle helfen bei der Bewältigung der oben genannten Herausforderungen und ermöglichen Organisationen eine bessere Entscheidungsfindung. Die beliebtesten Modelle sind im Folgenden aufgeführt:
- Data Fabric
- Daten-Mesh
- Daten-See-Haus
Was also ist Data Fabric?
Data Fabric baut auf dem modernen Data Warehouse auf und bietet die Möglichkeit, Unternehmensdaten auf kontrollierte Weise zu integrieren. Diese Daten werden über Self-Service zur Verfügung gestellt. Es basiert auf den Prinzipien der Datenverwaltung, um Qualität, Sicherheit, Governance und Katalogisierung zu gewährleisten.
Data Fabric vereinfacht den Datenbankzugriff, indem es die Komplexität kapselt, die durch die Vielzahl von Anwendungen, Datenmodellen, Formaten und verteilten Datenbeständen in einem Unternehmen entsteht. Der Benutzer kann auf die Daten zugreifen, ohne den Speicherort, die Zuordnung oder die Struktur der Daten zu kennen.
Die wichtigsten Säulen von Data Fabric sind Metadaten (die auch ein zentrales Prinzip der Datenarchitektur sind), ein robustes Datenintegrations-Backbone und eine semantische Schicht. Data Fabric stützt sich stark auf Metadaten, um das Ziel zu erreichen, die richtigen Daten zur richtigen Zeit bereitzustellen. Die Metadaten sollten in der Lage sein, die Daten für die verschiedenen Methoden, einschließlich Batch, Streaming, Messaging usw., zu identifizieren, zu verbinden und zu analysieren. Das folgende Diagramm zeigt die wichtigsten Säulen einer Data Fabric laut Gartner.
 Bildquelle: Gartner
Bildquelle: Gartner
Einführung von Data Fabric
Die größte Herausforderung bei der Implementierung von Data Fabric-Lösungen besteht darin, dass Daten in Silos existieren . Die große Vielfalt an Datenbanken, Datenverwaltungsrichtlinien und Speicherorten erschwert die Integration. Eine Fabric-Lösung muss natürlich in der Lage sein, all diese Unterschiede zu harmonisieren. Die meisten Unternehmen verwenden ein Tool zur Datenvirtualisierung, um dies zu erreichen. Die Harmonisierung und Vereinheitlichung durch Virtualisierung birgt jedoch immer ein Risiko und kann aufgrund des Datentransfers zwischen hybriden oder Multi-Cloud-Grenzen auch Leistungs- und Kosteneinbußen mit sich bringen.
Was ist Data Mesh?
Zhamak Dehghani schreibt in ihrem Buch: "Data Mesh ist ein dezentraler soziotechnischer Ansatz für die gemeinsame Nutzung, den Zugriff und die Verwaltung analytischer Daten in einer groß angelegten, komplexen Umgebung." Es basiert auf den Grundprinzipien der Dezentralisierung von Daten, der Bereitstellung von Domäneneigentum, der Selbstbedienungsinfrastruktur als Plattform und der Behandlung von Daten als Produkt, das dann im gesamten Unternehmen mit Hilfe einer föderierten Computersteuerung gemeinsam genutzt wird. Der grundlegende Wandel im Wertesystem eines Datennetzes besteht darin, dass Daten nicht mehr als zu sammelndes Gut, sondern als Produkt behandelt werden, das den Kunden dient. Data Mesh basiert auf zwei Designansätzen:
1. Ergebnisorientiert:
Denken in Datenprodukten - Veränderung der Denkweise hin zu einer Sichtweise der Datenverbraucher- Eigentümer der Datendomäne, die für die KPIs/SLAs der Datenprodukte verantwortlich sind
- Gleiches Technologiegeflecht und gleiche Semantik der Datendomäne für alle
- Beseitigen Sie den "Mann in der Mitte", indem Sie Datenereignisse direkt aus den Datensystemen zugänglich machen und Self-Service-Echtzeit-Datenpipelines bereitstellen, um Daten dort zu erhalten, wo sie benötigt werden.
2. Lehnt eine monolithische IT-Architektur ab
Dezentralisierte Architektur- Eine Architektur für dezentralisierte Daten, Dienste und Clouds
- Entwickelt, um Ereignisse aller Arten, Formate und Komplexitäten zu verarbeiten
- Stream-Verarbeitung als Standard, zentralisierte Stapelverarbeitung als Ausnahme
- Entwickelt, um Entwickler zu unterstützen und Datenkonsumenten direkt mit Datenproduzenten zu verbinden
- Sicherheit, Validierung, Nachweisbarkeit und Erklärbarkeit sind eingebaut
Grundsätze des Datennetzes
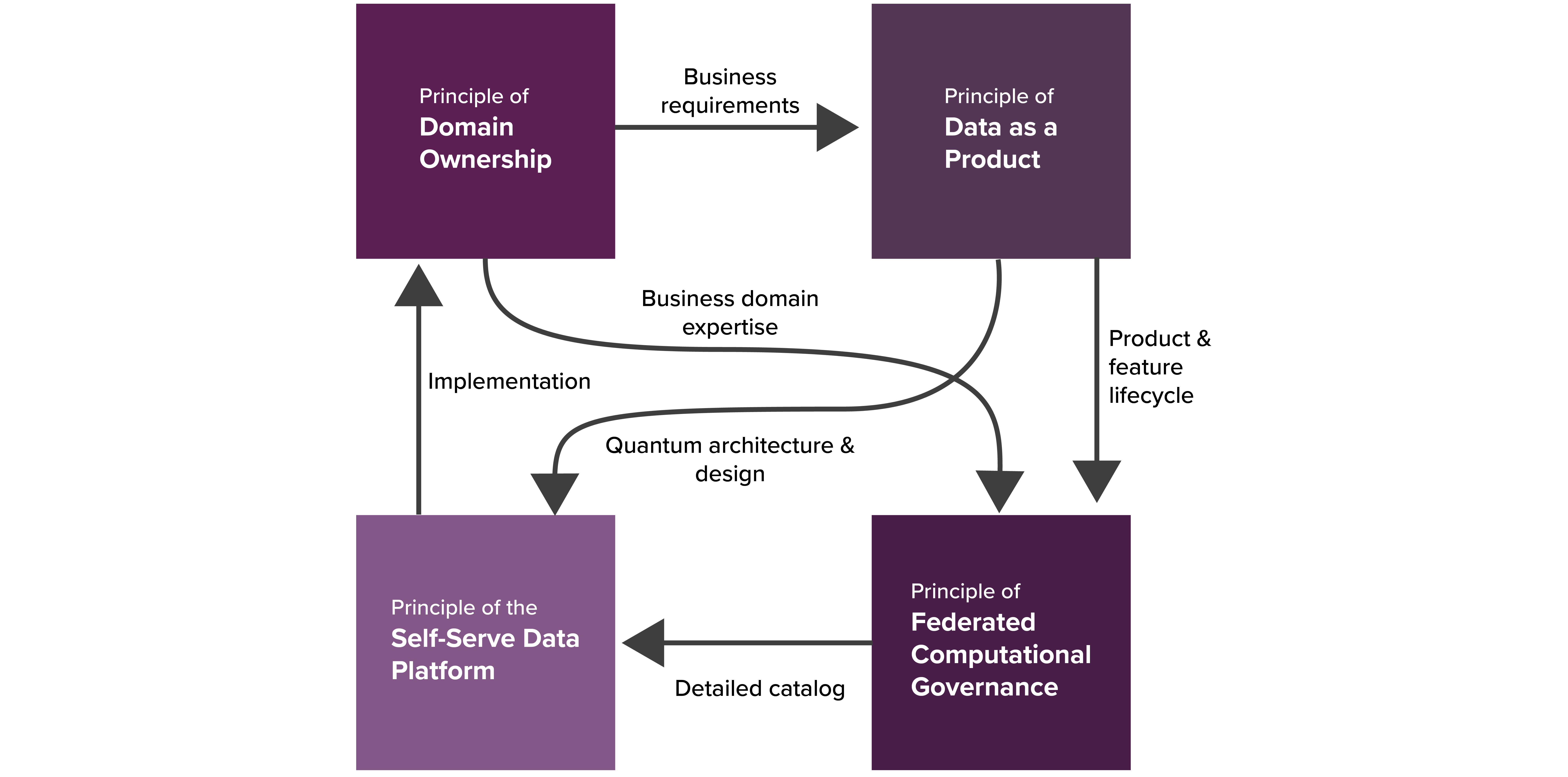
Bildquelle: Medium
Grundsätze des Datennetzes
1. Prinzip der Domäneneigentümerschaft: Dezentralisieren Sie das Eigentum an analytischen Daten auf die Geschäftsbereiche, die den Daten am nächsten sind - entweder die Quelle oder die Hauptverbraucher.
2. Das Prinzip der Daten als Produkt: Bereichsorientierte Daten werden als Produkt direkt mit expliziten Datennutzern geteilt. Diese Daten als Produkt entsprechen einer Reihe von Benutzerfreundlichkeitsmerkmalen, einschließlich Auffindbarkeit, Adressierbarkeit, Verständlichkeit, Sicherheit usw.
3. Selbstbedienungs-Datenplattform: Besteht aus Self-Service-Datenplattformdiensten, die es funktionsübergreifenden Teams ermöglichen, Daten gemeinsam zu nutzen. Dies hilft bei der Kostensenkung, der Automatisierung von Governance-Richtlinien und der Abstraktion.
4. Federated Computational Governance: Dies ist ein Betriebsmodell für die Datenverwaltung, das auf einer föderierten Entscheidungs- und Verantwortungsstruktur basiert. Dieses Modell stützt sich in hohem Maße auf die Kodifizierung und Automatisierung der Richtlinien auf einer feinkörnigen Ebene für jedes Datenprodukt über die Plattformdienste.
Einführung von Data Mesh
Um sich als geeigneter Kandidat für Data Mesh zu qualifizieren, müssen sich Unternehmen anhand der sieben Dimensionen bewerten, die in der nebenstehenden Abbildung dargestellt sind.
Was den meisten Unternehmen Schwierigkeiten bereiten könnte, ist die Tatsache, dass sie in ALLEN Kategorien eine mittlere (M) oder hohe (H) Punktzahl erreichen müssen .
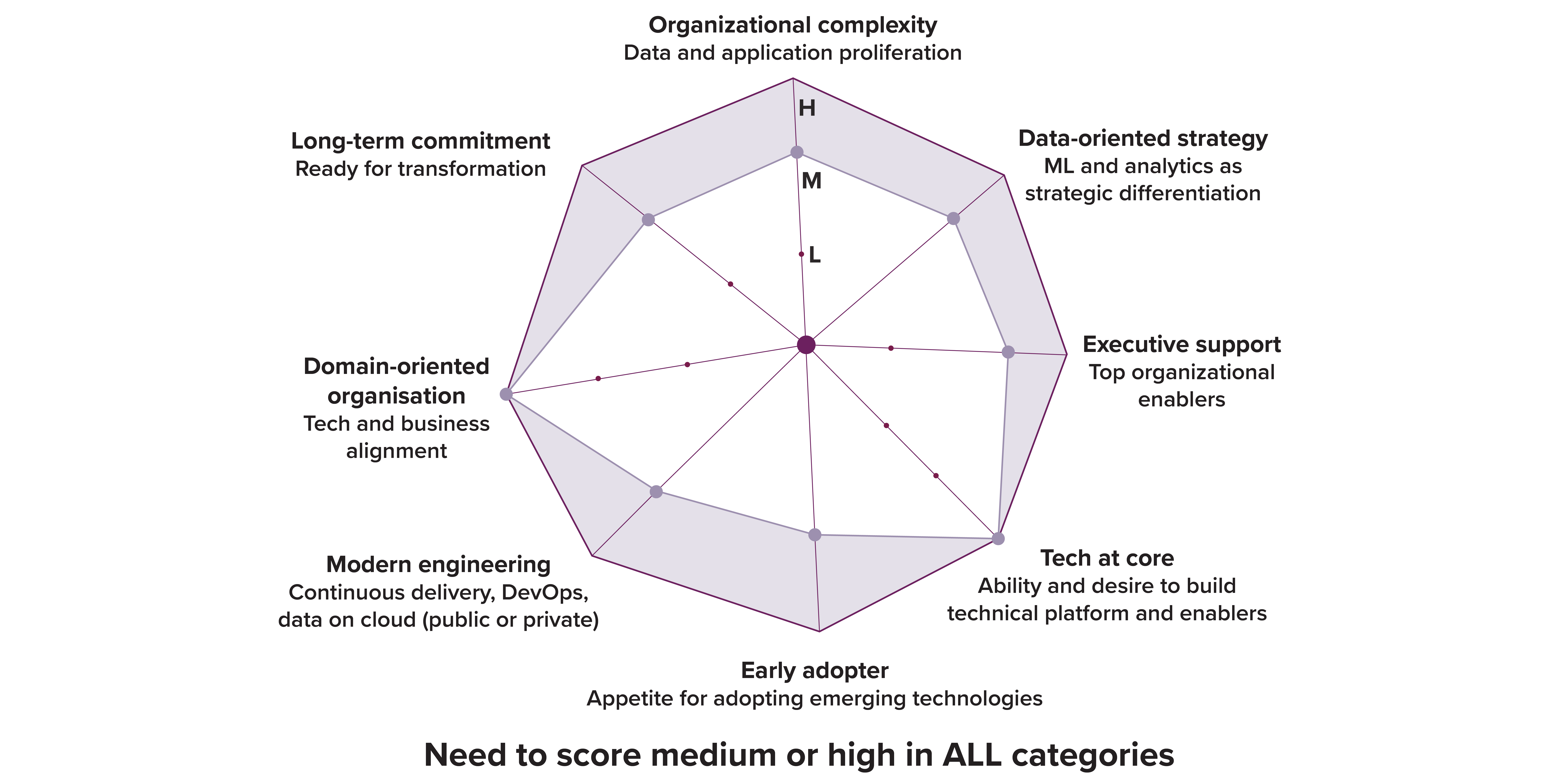 Bildquelle: Data Mesh von Zhamak Dehghani
Bildquelle: Data Mesh von Zhamak Dehghani
Daten-See-Haus
Data Lakehouse baut, wie der Name schon sagt, auf dem Data Lake auf und ist so optimiert, dass es die Skalierbarkeit des Data Lakes und die Integrität des Data Warehouses sowohl für Batch- als auch für Streaming-Daten bietet. Laut databricks ist ein Data Lakehouse eine neue, offene Datenmanagement-Architektur, die die Flexibilität, Kosteneffizienz und Skalierbarkeit von Data Lakes mit dem Datenmanagement und den ACID-Transaktionen von Data Warehouses kombiniert und so Business Intelligence (BI) und maschinelles Lernen (ML) auf allen Daten ermöglicht. Lakehouse implementiert Datenstrukturen und Datenverwaltungsfunktionen, die denen eines Data Warehouses ähneln, direkt auf kostengünstigem Speicher, wie er für Data Lakes verwendet wird.
Ein Data Lakehouse ist eine Erweiterung des Data Lakes und sollte in der Lage sein, alle Datenformate zu unterstützen, einschließlich strukturierter und unstrukturierter Daten. Das bedeutet, dass Unternehmen, die von der Arbeit mit unstrukturierten Daten profitieren können (was so ziemlich jedes Unternehmen ist), nur einen Datenspeicher benötigen und nicht sowohl eine Warehouse- als auch eine Lake-Infrastruktur.
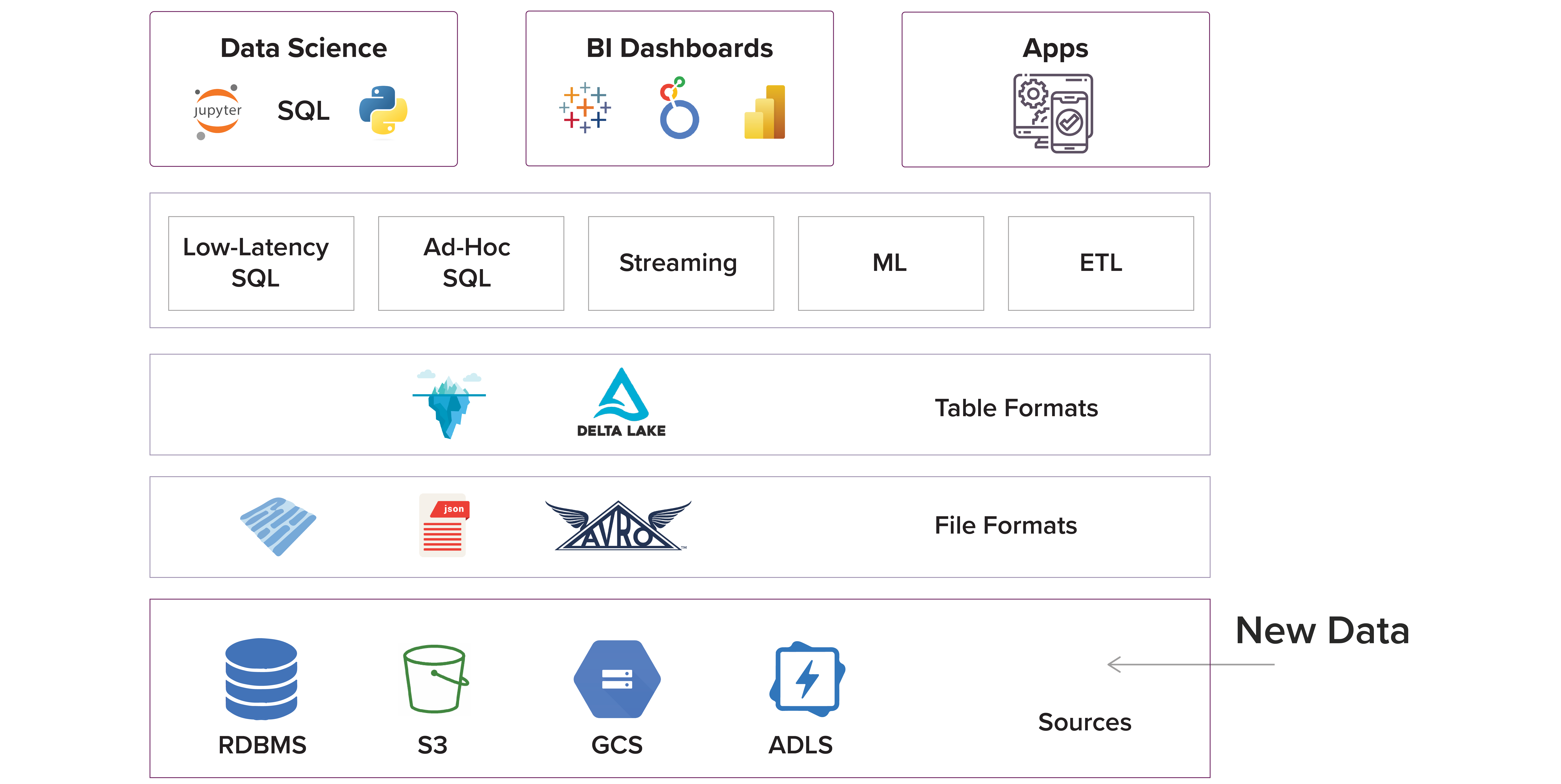 Bildquelle: Dremio
Bildquelle: Dremio
Lakehouse basiert auf einigen der folgenden Grundprinzipien:
- Metadatenschicht - fungiert als eine Art "Vermittler" zwischen den unstrukturierten Daten und dem Datennutzer, um die Daten zu kategorisieren und zu klassifizieren, so dass sie katalogisiert und indiziert werden können. Diese Schicht ermöglicht die Unterstützung von Streaming I/O (wodurch Nachrichtenbusse wie Kafka überflüssig werden), Zeitreisen zu alten Tabellenversionen, die Durchsetzung und Weiterentwicklung von Schemata sowie die Datenvalidierung.
- Intelligente Analyse-Schicht - Das Lakehouse ist eine optimierte SQL-ähnliche Abfrage-Engine zur Ausführung auf dem Data Lake und ermöglicht die automatisierte Integration von Daten. Eine Datenabfrage kann von jedem beliebigen Ort aus mit einem beliebigen Tool durchgeführt werden, wobei in einigen Fällen eine SQL-ähnliche Schnittstelle verwendet wird, um strukturierte und unstrukturierte Daten gleichermaßen abzufragen. Erreicht wird dies durch die Zwischenspeicherung heißer Daten in RAM/SSDs (möglicherweise transkodiert in effizientere Formate), Optimierungen des Datenlayouts, um gemeinsam genutzte Daten zu bündeln, zusätzliche Datenstrukturen wie Statistiken und Indizes sowie vektorisierte Ausführung auf modernen CPUs.
- Zugang für Datenwissenschaftler und Tools für maschinelles Lernen - Die offenen Datenformate, die von Data Lakehouses (wie Parquet) verwendet werden, machen es für Datenwissenschaftler und Ingenieure für maschinelles Lernen sehr einfach, auf die Daten im Lakehouse zuzugreifen. Außerdem können Datenwissenschaftler so unstrukturierte Daten zusammen mit KI und maschinellem Lernen nutzen. . Lakehouse ermöglicht auch Audit-Historie und Zeitreisen, was bei ML-Anwendungsfällen hilfreich ist.
Einführung von Data Lakehouse
Während Data Lakehouse darauf abzielt, das Beste aus beiden Welten zu bieten, nämlich die Skalierbarkeit von Data Lakes und die Integrität von Data Warehouses, gibt es einige Bereiche, die bei der Implementierung dieses Ansatzes durchdacht werden müssen, darunter die Komplexität der Lösung, die Governance und die Leistung. Es handelt sich um kosteneffiziente Lösungen, die es ermöglichen, strukturierte und unstrukturierte Informationen an einem Ort zu speichern, bevor die Metadatenschicht über dem Data Lake verwendet wird, wie APACHE HUDI, ICEBERG und DELTA.
Fazit
Eine Datenarchitektur ist ein Entwurf für die Verwaltung von Daten. Unabhängig vom Rahmenwerk bleibt das Endziel dasselbe. Der Schwerpunkt liegt jetzt eher auf der Bereitstellung genauer und aktueller Daten auf sichere und kontrollierte Weise für Geschäftsanwender, um datengestützte Entscheidungen zu ermöglichen, als auf der bloßen Sammlung und Speicherung von Daten. Die Datenstrategie wird zu einer Schlüsselaktivität, die den Weg in die Zukunft bestimmt.
Die Implementierung eines der oben genannten Architekturstile hängt von der Reife des Unternehmens ab. Es geht mehr um die Prozesse und kulturellen Veränderungen als um die Technologie. Es gibt keine Schablone oder einen allgemeingültigen Ansatz, der sich auf alle Unternehmen übertragen lässt.
Außerdem gibt es eine Menge Überschneidungen zwischen diesen Stilen, und sie können auch zusammen verwendet werden, anstatt als Einzellösungen. Sie schließen sich nicht gegenseitig aus. Die Grundpfeiler aller Architekturstile sind ähnlich. Die automatische Integration von Datenquellen, ein gut definierter Katalog und der einfache und zeitnahe Zugriff auf nützliche und relevante Daten sind die Prinzipien all dieser Frameworks. Es steht Unternehmen frei, einen oder mehrere dieser Stile zu verwenden, wenn sie es für richtig halten.
Referenzen:
Entmystifizierung der Datenplattformarchitektur auf Medium
Data Lakehouse Glossar auf Databricks
Was ist ein Data Lakehouse? auf Forbes
Data Fabric Architektur auf Gartner
TOGAF Kapitel auf The Open Group
Die nächste Generation von Datenplattformen auf Medium
Data Fabric Architektur auf Gartner
Unsere Ideen
Weitere Artikel




Contact