Artikel
Anwendung der Prinzipien der Microservices-Architektur auf die moderne Datenarchitektur

Microservices-Architektur im Kontext eines modernen Datenstapels
Microservices sind heute ein zentraler Bestandteil der meisten, wenn nicht aller Anwendungsentwicklungen. Mit der jüngsten Entwicklung von datenbezogenen Technologien und Frameworks, wie z.B. Data Mesh, wird die Microservices-Architektur jedoch zum Mainstream und Teil des modernen Datenarchitekturdesigns.
Die Microservices-Architektur ist ein Software-Entwurfsmuster, das eine Anwendung als Sammlung von lose gekoppelten Diensten (z.B. nach Geschäftsfunktionen) strukturiert. Im Falle der Datenverarbeitung könnte es sich um einen Pipeline-Schritt handeln. Das Design von Microservices ermöglicht es, dass diese Dienste unabhängig von den anderen Diensten in der Pipeline entwickelt, verwaltet und bereitgestellt werden können.
In einem modernen Data Stack ist dies ein Ansatz zur Gestaltung eines Datenverarbeitungs-Workflows, der Prozesse wie Datenaufnahme, Datenspeicherung, Datenumwandlung oder Datenbereitstellung umfasst, indem diese Prozesse in eine Sammlung kleiner, unabhängiger und hochspezialisierter Dienste zur Abwicklung der gesamten Datenverarbeitung aufgeteilt werden.
Die Microservices sind so konzipiert, dass sie lose gekoppelt sind, was eine größere Flexibilität und Agilität bei der Verwaltung des Datenverarbeitungssystems ermöglicht, da neue Services bei Bedarf hinzugefügt oder entfernt werden können, ohne das Gesamtsystem zu stören. Außerdem erhalten die Entwickler die Flexibilität, den Technologie-Stack zu verwenden, mit dem sie vertraut sind und der für ihren speziellen Dienst besser geeignet ist.
Die Microservice-Datenmanagement-Muster
- Das Datenbank-pro-Dienst-Muster
Die Datenbank pro Dienst ermöglicht eine Dezentralisierung und bietet mehr Flexibilität. Sie ermöglicht eine unabhängige Skalierung und Änderungen am Datenschema können ohne Auswirkungen auf andere Microservices durchgeführt werden. Die Trennung von Datenbanken bedeutet, dass jede DB je nach Arbeitslast und Art der Daten individuell gestaltet werden kann. - Gemeinsame Datenbank
Eine gemeinsame Datenbank ermöglicht eine logische Trennung zwischen den Microservices, die sich dieselbe physische Instanz teilen. - Das CQRS-Muster
Das CQRS ermöglicht separate Datenbankinstanzen für Abfragen und die Ausgabe von Befehlen. Dies eignet sich besser für ein Szenario, in dem mehr gelesen als geschrieben wird. - Das Event Sourcing-Muster
Event Sourcing persistiert und aggregiert als eine Folge von Ereignissen. - Das Saga-Muster
Saga ermöglicht die Implementierung von Geschäftstransaktionen, die sich über mehrere Dienste erstrecken, wobei jede lokale Transaktion die Datenbank aktualisiert und die nächste lokale Transaktion auslöst. Im Falle eines Fehlers führt Saga eine Reihe von Ausgleichstransaktionen aus, um die Änderungen rückgängig zu machen.
Wie können Microservices bei der Entwicklung einer modernen Datenarchitektur helfen?
Der erste Schritt ist die Identifizierung der geschäftlichen Anforderungen an die Datenarchitektur, einschließlich der Identifizierung der Datenquellen, der Art, des Formats und der Häufigkeit der Daten sowie der Anforderungen an die Datenverarbeitung, die Schritte für die Datenqualität, das Stammdatenmanagement, die Datenkatalogisierung usw. umfassen können. Sobald dies geschehen ist und der Verarbeitungsworkflow definiert ist, wird jeder Schritt des Workflows in einen Microservice aufgeteilt und containerisiert, so dass er unabhängig verwaltet, bereitgestellt und skaliert werden kann. Einige der gemeinsamen Elemente, die in allen Microservices enthalten sein müssen, sind die Beobachtbarkeit, die Datensicherheit und alle spezifischen Compliance- und Datenschutzregeln.
Wie Sie weiter unten sehen werden, müssen beim Entwurf einer Datenplattformarchitektur für ein Unternehmen mehrere Aspekte berücksichtigt werden. Wenn wir uns von links nach rechts bewegen, kann eine vollautomatische Datenplattform aus mehreren Schritten für ihre Datenverarbeitungspipelines bestehen. Eine einfache Batch-Ingestion-Pipeline verwendet beispielsweise das Batch-Ingestion-Framework, einen Datenqualitäts- und Katalogdienst, erfordert eine Aggregation vor dem Laden in das Warehouse und muss automatisiert, überwacht und auf Fehler hin orchestriert werden usw. Jeder dieser Hops kann ein eigener Microservice sein, wobei jeder Service über eigene Speicher-, Rechen- und Verarbeitungskomponenten verfügt.
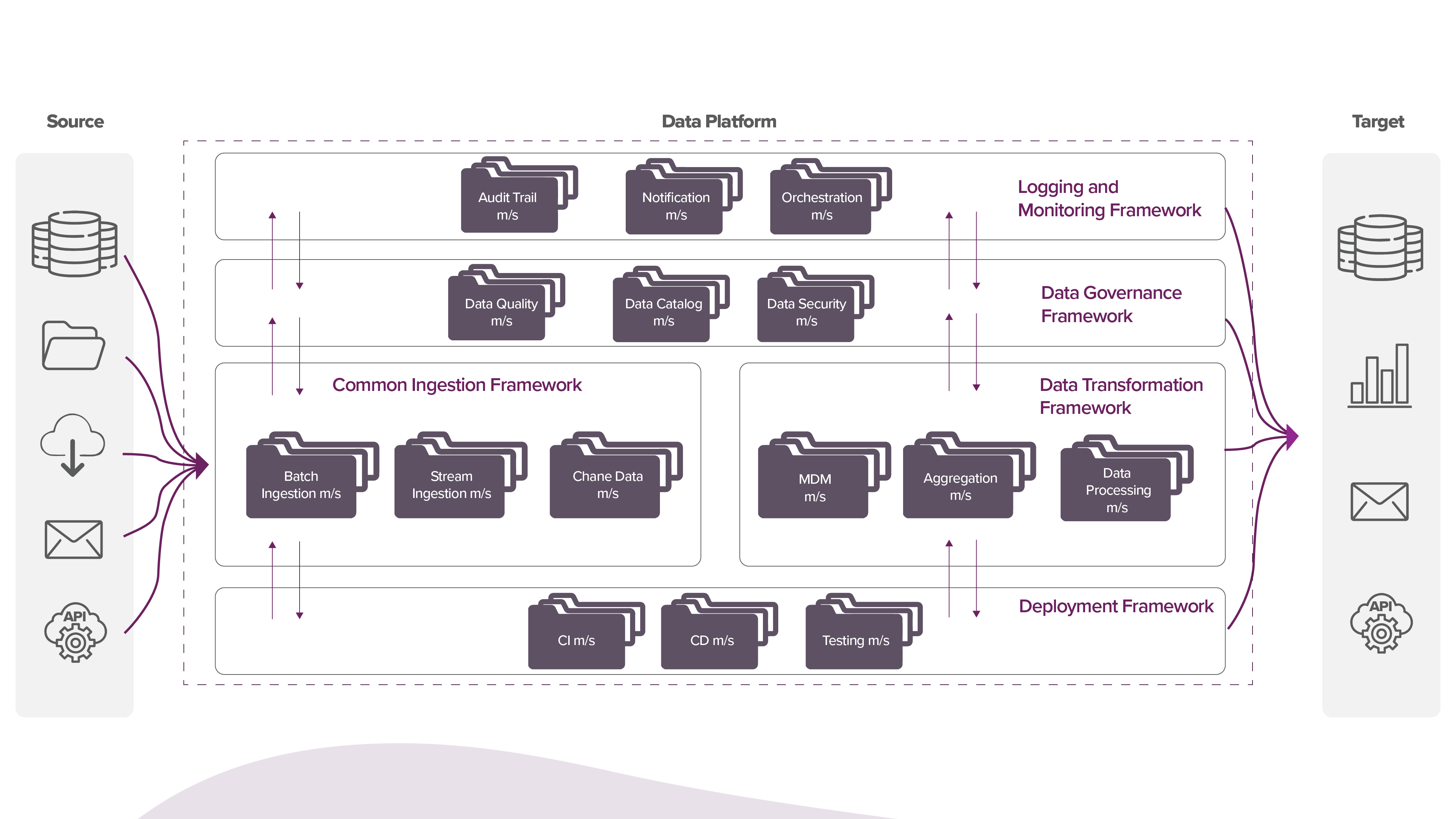
Herausforderungen
Wenn die Daten von den Produzenten zu den Konsumenten gelangen, müssen alle Schritte der Datenpipeline, auch wenn sie durch Microservices getrennt sind, nahtlos als Teil der Gesamtausführung ablaufen. Das klingt zwar offensichtlich, wirft aber einige offensichtliche Designaspekte auf, die durchdacht werden müssen:
- Wie stellen Sie die Konsistenz zwischen den verschiedenen Diensten sicher, da die Möglichkeit besteht, dass die Daten zwischen den Diensten dupliziert werden?
- Wie können Sie im Falle eines Fehlers die gesamte Transaktion, die sich über mehrere Dienste erstrecken könnte, zurücksetzen?
- Wie werden Änderungen in der Datendefinition zwischen den Diensten (sowohl vorwärts als auch rückwärts) kommuniziert und wie wird die ACID-Konsistenz gegenüber der eventuellen Konsistenz verwaltet?
- Wie legen Sie den Umfang und die Prioritäten der Probleme (teamübergreifend) fest, wenn es zu einem Ausfall kommt?
- Wie stellen Sie die Isolierung von Code und Daten sicher, wenn der Gesamtauftrag mehrere Dienste und Projekte umfasst?
Bei Microservices geht es um die Dezentralisierung von Daten. Sie sollten über ihre eigenen Daten verfügen und gleichzeitig in der Lage sein, miteinander zu interagieren und Daten gemeinsam zu nutzen. Die oben genannten Fragen müssen vor der eigentlichen Implementierung beantwortet und sorgfältig geplant werden. Mehr Microservices führen zu mehr Komplexität, und es ist klar, dass bei der Entscheidung über die richtige Anzahl von Microservices ein Kompromiss gefunden werden muss, um Dezentralisierung und Modularität zu ermöglichen und gleichzeitig sicherzustellen, dass die Teamgröße, das Testen und Debuggen sowie die Teamkoordination nicht aus dem Ruder laufen.
Das könnte Sie auch interessieren: GCP-Zertifizierungen | AWS-Zertifizierungen
Anbieter von Cloud-Diensten wie Azure, AWS und GCP tragen wesentlich dazu bei, dass eine Microservices-Architektur möglich wird. Die Vielzahl der Cloud-Services für Ingestion, Speicherung, Berechnung, Bereitstellung, Orchestrierung usw. ermöglicht ein flexibles Design für Microservices und eine ereignisgesteuerte Architektur bei gleichzeitiger Implementierung von Service Discovery, Sicherheit und Compliance sowie automatisierten Bereitstellungen. Innerhalb von AWS können Sie zum Beispiel Microservices entweder mit AWS Lambda oder mit Docker Containern mit AWS Fargate entwickeln.
Ein gutes Beispiel für einen serverlosen Microservice für eine E-Commerce-Anwendung sehen Sie unten. Ähnliche Architekturmuster und Designs können auch mit Microsoft Azure und GCP umgesetzt werden. 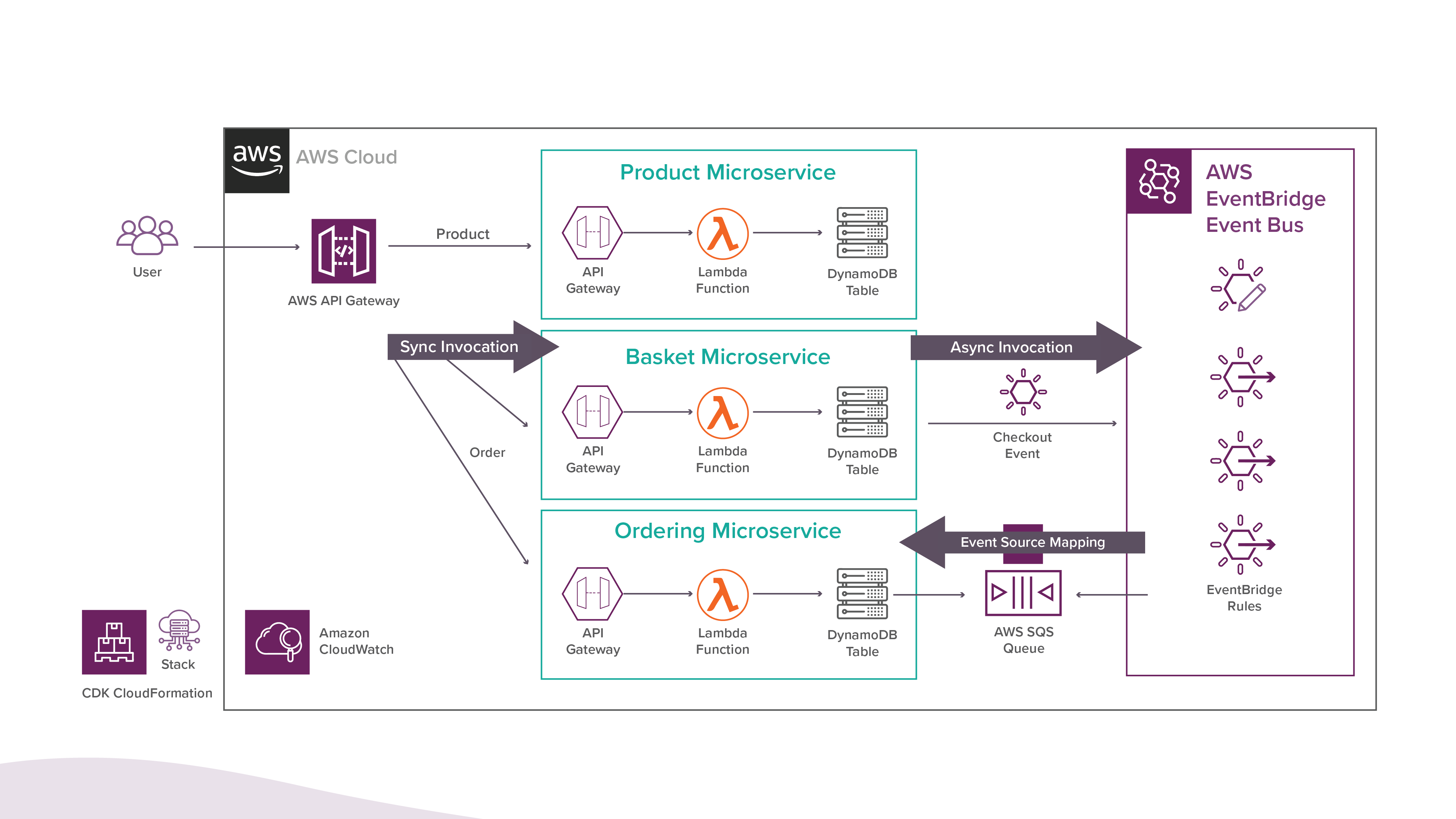
Bildquelle: Medium
Fazit
Die Microservices-Architektur eignet sich gut für moderne Datenplattformen und eignet sich besser für große Unternehmen mit mehreren Funktionen, die die Verarbeitung und Verwaltung großer Datenmengen in Echtzeit erfordern. Sie eignet sich auch für ereignisgesteuerte Architekturen, bei denen die Daten als Ereignisse konsumiert werden können, bevor sie angefordert werden. Das Design von Microservices ermöglicht eine detailliertere Kontrolle über die verschiedenen Teile der Plattform, wodurch sie leichter skaliert und gewartet werden kann. Die Nutzung der Cloud und insbesondere die Containerisierung haben die Entwicklung und Bereitstellung von Microservices erleichtert.
Das Design und die Einschätzung, ob das Microservices-Design die richtige Lösung für ein Unternehmen und seine Datenplattform ist, müssen vorgenommen werden. Die Kosten und die Komplexität der Implementierung stehen in keinem Verhältnis zu dem Aufwand, der für das Design, die Entwicklung und die Pflege des Designs betrieben werden muss. Für einige kleinere Unternehmen ist ein Monolith vielleicht genau das Richtige.
Referenzen
Muster und Prinzipien der Datenbankverwaltung für Microservices
Daten aus Microservices in den Data Lake bringen Teil 1: Aus Datenbanken
Index der Muster für Microservices-Architektur
AWS Serverless Services für Microservices-Architekturen
Tägliche Verarbeitung von Terabytes an Daten mithilfe der Microservices-Architektur bei MiQ
Unsere Ideen
Weitere Artikel




Contact