
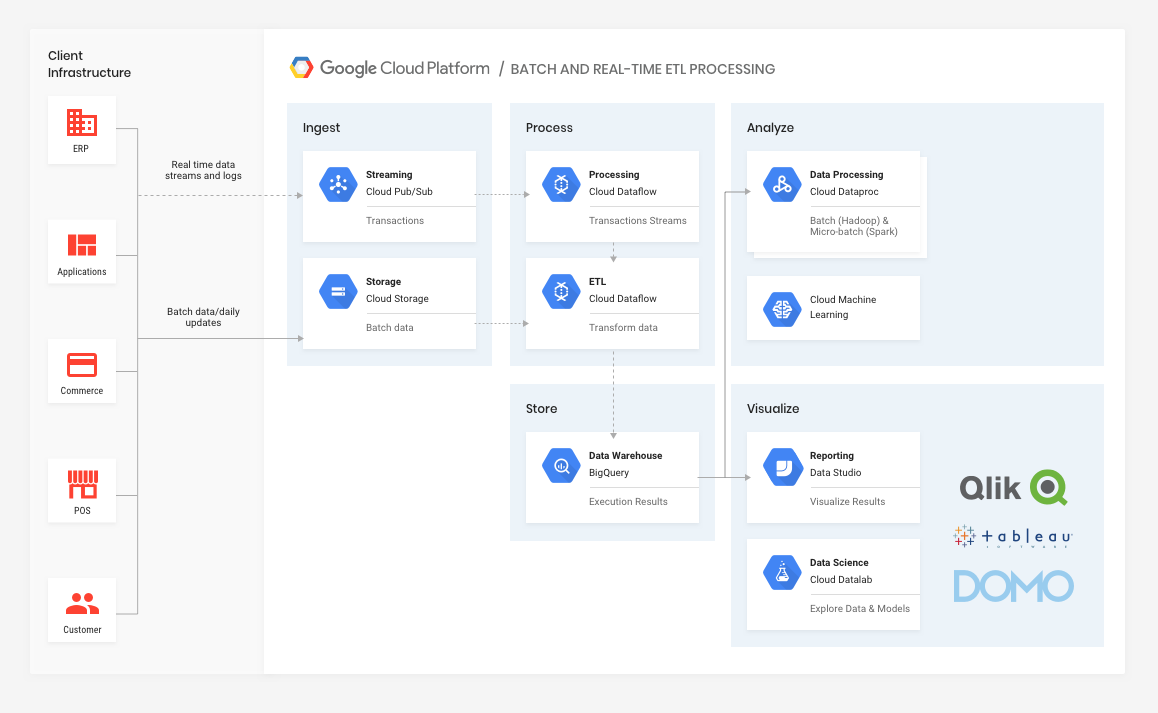
Dies wiederum ermöglicht ihnen den Übergang von großen Batch-Workloads zu Micro-Batch-Workloads, wenn ihre Backend-Infrastruktur im Laufe der Zeit modernisiert wird. Außerdem haben sie die Möglichkeit, die Datenverarbeitung und -umwandlung direkt nach dem Einlesen durchzuführen (Cloud Dataflow ist ein vollständig verwalteter Stream- und Batch-Datenverarbeitungsdienst, der auf Apache Beam basiert).
Im Laufe der Zeit, wenn die Backend-Systeme es zulassen, könnte der Einzelhändler die Vorteile der Echtzeitaufnahme (über Cloud Pub/Sub) nutzen und weiterhin die Verarbeitungs- und Speicherkapazität im selben Data Warehouse wie die ETL-Daten verwenden.
Das Tolle am GCP-Stack ist, dass es sich um einen hochgradig modularen, vollständig verwalteten Service handelt, so dass jedes Unternehmen zunächst ETL, Datenverarbeitung und Visualisierung in die Cloud migrieren könnte, um Infrastrukturkosten zu sparen. Im Laufe der Zeit und in dem Maße, wie die Fähigkeiten des Unternehmens (technologisch und personell) wachsen, könnte es das Echtzeit-Daten-Streaming in denselben Stack einbringen. Hier sind einige wichtige Funktionen und Produkte zu nennen:
Wolke Pub/Sub
Pub/Sub kann als nachrichtenorientierte Middleware in der Cloud betrachtet werden, die eine Reihe von Anwendungsfällen mit hohem Nutzwert bietet, insbesondere in unserem Fall asynchrone Workflows und Daten-Streaming von verschiedenen Prozessen, Geräten oder Systemen. Sie ermöglicht die Aufnahme von Informationen in Echtzeit zur Verarbeitung und Analyse.
Google Cloud Storage (GCS) und Speicherübertragungsdienst
GCS ist ein einheitlicher Objektspeicher und dient lediglich als Zwischenstation für Daten, die von verschiedenen Backend-Systemen vor der Verarbeitung geladen werden. Dieser Staging Point bietet die Möglichkeit, Daten zu standardisieren, bevor nachgelagerte Dienste mit der Verarbeitung beginnen.
Der Übermittlungsdienst (in der Architektur nicht dargestellt) bietet einen Mechanismus, um Daten in den Cloud-Speicher zu übertragen, z. B. für einmalige oder wiederkehrende Übermittlungsvorgänge sowie für die regelmäßige Synchronisierung zwischen Datenquellen und Datensenken. Damit entfällt die Notwendigkeit, das Laden von Stapeln usw. manuell zu verwalten, und der Automatisierungsgrad zwischen interner und Cloud-basierter Verarbeitung wird erhöht.
Google Stackdriver
Stackdriver (in der Architektur nicht dargestellt) ist zwar für den Betrieb der Datenverarbeitung und -analyse nicht entscheidend, lässt aber alle Beteiligten nachts besser schlafen, da es eine sehr leistungsstarke Überwachung, Protokollierung und Diagnose bietet, die sicherstellt, dass alle Datenverarbeitungs-Workloads und alle nachgeschalteten Anwendungen gesund sind und optimal funktionieren. Da die Überwachung auch in Ihre eigene Infrastruktur eingebettet werden kann, bietet sie einen ganzheitlichen Überblick über die Datenlieferketten in Ihrem Unternehmen.
Cloud-Datenfluss
Cloud Dataflow ist ein Service (basierend auf Apache Beam) zur Umwandlung und Anreicherung von Daten im Stream- (Echtzeit) und Batch-Modus (historisch) mit gleicher Zuverlässigkeit und Aussagekraft. Er bietet ein einheitliches Programmiermodell und einen verwalteten Service für die Entwicklung und Ausführung einer Vielzahl von Datenverarbeitungsmustern, einschließlich ETL. Cloud Dataflow erschließt transformative Anwendungsfälle in verschiedenen Branchen, darunter:
- Clickstream-, Point-of-Sale- und Segmentierungsanalysen im Einzelhandel
- Aufdeckung von Betrug bei Finanzdienstleistungen
- Personalisierte Benutzererfahrung bei Spielen
- IoT-Analytik in Fertigung, Gesundheitswesen und Logistik
Google hat das Cloud Dataflow-Programmiermodell und die SDKs in die Apache Software Foundation eingebracht und damit das Apache Beam-Projekt ins Leben gerufen, das sich schnell zu einem De-facto-Tool im Bereich der Datenverarbeitung entwickelt. Jan 2018 - Apache Beam senkt die Einstiegshürden für Technologien zur Verarbeitung großer Datenmengen
BigQuery
Google BigQuery ist ein Cloud-basierter Big-Data-Analyse-Webdienst für die Verarbeitung sehr großer, schreibgeschützter Datensätze. Es handelt sich praktisch um ein vollständig verwaltetes Data Warehouse in der Cloud. BigQuery wurde für die Analyse von Daten in der Größenordnung von Milliarden von Zeilen entwickelt und verwendet eine SQL-ähnliche Syntax. Es läuft auf der Google Cloud Storage-Infrastruktur und kann über eine REST-orientierte API angesprochen werden.
Daten aus BigQuery können von verschiedenen Anwendungen für regelmäßige oder Ad-hoc-Workloads eingelesen werden, z.B. für das End-of-Day-Reporting mit Tools wie Dataproc (dem vollständig verwalteten Hadoop- oder Spark-Service von GCP), für das Reporting in DataStudio (oder anderen BI-/Visualisierungstools) oder für aufkommende Data-Science-Initiativen mit DataLab (das den Open-Source-Kern von Jupyter nutzt).
Neben einem vollständig verwalteten Service bietet Googles Ansatz für die Infrastruktur eine Reihe von Vorteilen. Erstens verfügt fast jeder GCP-Service über einen Open-Source-Kern, so dass jeder Kunde die Freiheit hat, jederzeit von GCP auf eine andere Infrastruktur seiner Wahl zu migrieren (auch wenn er wahrscheinlich eine kleine Armee von DevOps und CREs einstellen müsste, um das zu verwalten). Zweitens, GCP bietet eine kostenlose Stufe. BigQuery beispielsweise hat zwei kostenlose Stufen: eine für die Speicherung (10 GB) und eine für die Analyse (1 TB/Monat), wodurch die Nutzung für Prototypen oder Tests gefördert wird.
Schlussfolgerungen
Wir sind begeistert von der Vielfalt der Möglichkeiten, die sich vielen unserer Kunden und Interessenten im Bereich der Dateninnovation bieten. Einige davon könnten für sie in den nächsten 5-10 Jahren zu einem bahnbrechenden Wachstum führen. Nicht nur in Bezug auf die Datenverarbeitung und -visualisierung, sondern auch in Bezug auf die Schaffung von Echtzeit-Datenlieferketten im Herzen ihrer Unternehmen. Das ist letztlich unsere Mission.
Wenn Sie der Meinung sind, dass Sie in einem dieser Bereiche Hilfe benötigen, würden wir gerne die für Ihr Unternehmen relevanten Optionen prüfen.



