The API Challenge in Today's Data World
Imagine creating your modern application, with your data everywhere – in various systems, in the cloud, on-premises. Wrangling all that critical information can feel like a puzzle that you never finish. Traditional APIs don't help the problem, and often complicate it. An API may give you too much data or sometimes, not enough, so you'll have to make multiple requests, which slows everything down.
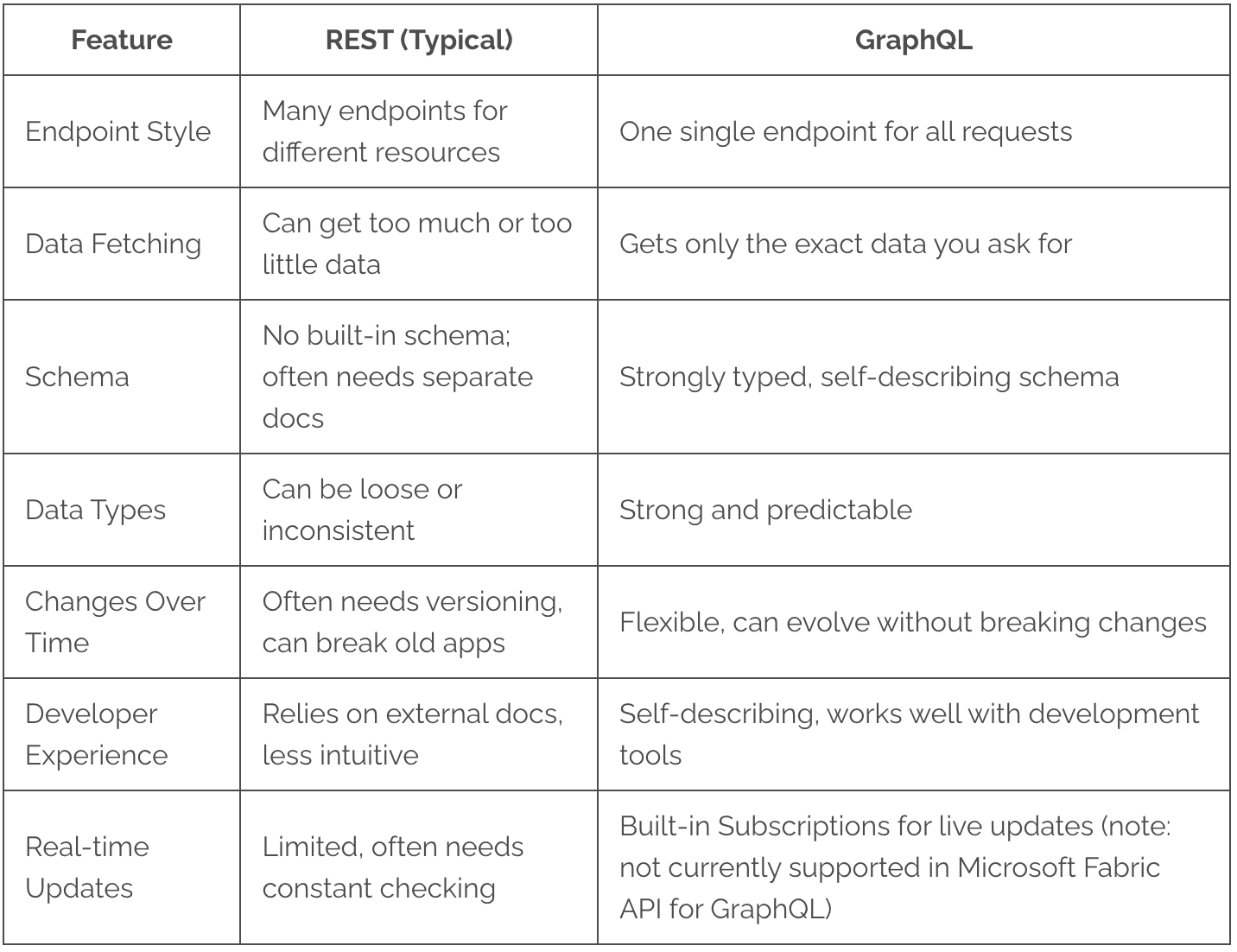
That's where GraphQL changes the game. You're the one who requests the server for the exact data you need. You can request exactly what you need, and that's exactly what you will get. The Microsoft Fabric API for GraphQL affords you the power to efficiently and quickly query the data directly from multiple of your data sources. It hides the complexity of where your data came from while you focus on creating your application, all in one API request .
This transformation isn't just a slight improvement, it 's a paradigmatic shift. It allows faster apps, less wasted effort, and a much more streamlined experience for developers. Now let's get into the magic.
Introducing GraphQL - A query language for your API
You can think of GraphQL as a translator for your data. It's not a database but a smart API that gives you a layer on top of your existing data source. It lets you "talk" to your data in a very precise way.
How does it work?
- Schema: The blueprint of your data—defines exactly what can be queried or changed, acting as a contract between client and server.
- Types: Organizes data into clear, predictable structures so you always know what to expect.
- Queries: Retrieve data by specifying only the fields you need; the server returns precisely that.
- Mutations: Change data (create, update, delete) in a controlled way, specifying both the changes and the data you want returned.
- Subscriptions: Enable real-time updates by notifying clients when data changes (note: not currently supported in Microsoft Fabric API for GraphQL).
Why is GraphQL making the difference?
- Efficient Data Fetching: Retrieve exactly the data you need—no more, no less—reducing bandwidth usage and improving application speed.
- Self-Describing API: Instantly discover available data and operations through the API’s schema, making development faster and more intuitive.
- Strong Typing: Benefit from predictable, consistent data structures, which minimizes errors and strengthens application reliability.
- Single Endpoint Simplicity: Access all resources through one unified endpoint, streamlining both backend management and client integration.
- Seamless Evolution: Update and extend your API without breaking existing clients, supporting long-term scalability and flexibility.
- Unified Data Access: Aggregate data from multiple sources and present it through a single, consistent interface for easier integration.
This focus on developer experience is key. Imagine knowing exactly what data you'll get before you even ask for it! This saves immense time, reduces errors, and makes building applications a joy.
Here's a quick comparison:
Microsoft Fabric API for GraphQL: Connecting to Your Data
The Microsoft Fabric API for GraphQL is a powerful layer that is designed to query your Fabric data sources quickly and efficiently. It's primary function is to provide developers with easy access to data without having to think about the complexities of your backend data. Developers are free to build their applications as they can be confident they can get all the backend data they need in a single optimized API call.
Key advantages of the Fabric API for GraphQL:
- Fast Data Access: Precise data requests enable applications to retrieve information quickly, improving performance.
- Hides Complexity: Developers are abstracted from the underlying details of different data sources.
- Unified Access: A single, consistent API provides access to multiple Fabric data assets, streamlining integration.
- Enhanced Security: Saved credentials reduce direct exposure of sensitive login details.
- Monitoring: Built-in dashboards and detailed logs offer visibility into API activity for troubleshooting and optimization.
- CI/CD Support: Seamless integration with Fabric's continuous integration and delivery tools ensures smooth development and deployment.
One of the cool features? It automatically discovers your data structure and creates the proper queries and mutations for you. This really cuts down on manual setup. For example, if you connect Fabric SQL database, the API automatically inspects its tables and procedures and dynamically creates the GraphQL types and operations.
For more complicated business rules, you can implement that logic in stored procedures in your SQL database. You can then easily expose those procedures to your application as GraphQL mutations through the API, allowing your apps to trigger complicated business operations neatly. This automation makes complicated API development far more accessible, allowing data professionals to deliver high-value data products with a relatively small coding footprint.
Data Integration: Internal & External Sources and GraphQL
The Fabric API for GraphQL allows the querying of data from many internal Fabric items and presents a unified access layer as a single API for developers.
Internal Fabric Data Sources
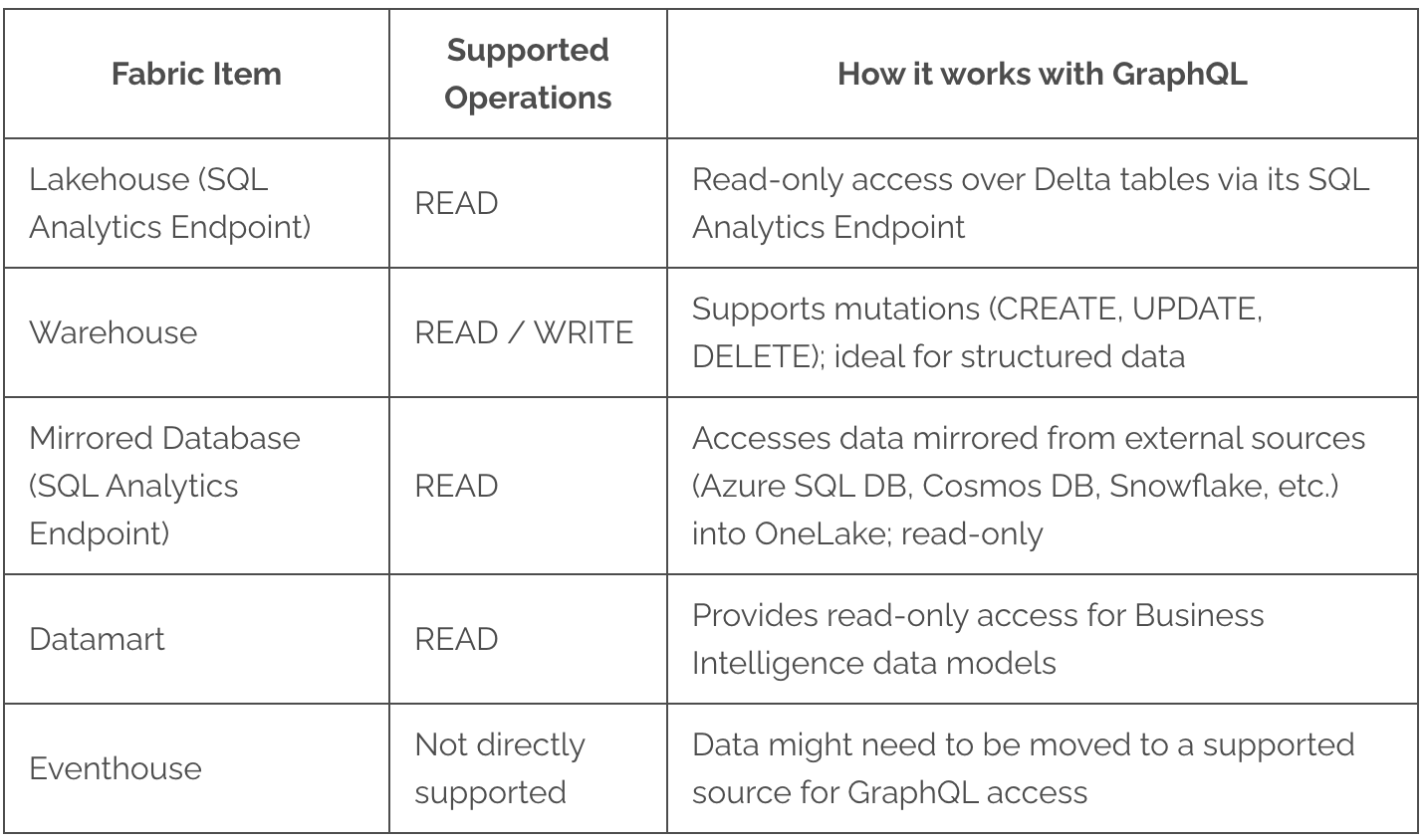
- Lakehouse (SQL Analytics Endpoint): Your Lakehouse data can be exposed for READ operations. The GraphQL API accesses it through its read-only SQL Analytics Endpoint, making your Delta tables available
- Warehouse: This is where the real power for data modification lies! The Fabric GraphQL API fully supports both READ / WRITE operations for data in a Warehouse. This makes it the go-to for direct GraphQL mutations (CREATE, UPDATE, DELETE). The API even intelligently generates CREATE mutations based on your Warehouse schema.
- Eventhouse: While Eventhouses are great for real-time data , the Microsoft Fabric API for GraphQL does not currently directly support querying or changing Eventhouse data. If you need GraphQL access to Eventhouse data, you'd typically process it and then move or mirror it to a supported source like a Warehouse or Lakehouse.
External Data Sources via Mirroring
With Fabric's innovative Mirroring feature you can even have GraphQL for your external datasources. By continuously copy data from various external systems directly into OneLake, avoiding complex ETL processes, it allows you to use the same GraphQL for Microsoft Fabric.
- Supported Mirrored Sources: This includes popular sources like Azure SQL Database, Azure Cosmos DB, Azure Databricks, and Snowflake.
- GraphQL API Access: Once these external databases are mirrored into OneLake, they become accessible via their SQL Analytics Endpoints. The Fabric GraphQL API can then seamlessly expose this mirrored data, primarily for READ operations. This means your applications can query data from diverse external sources through a unified GraphQL interface, treating them like native Fabric data assets. For example, mirroring Azure Cosmos DB data with GraphQL lets you build "robust real-time analytical applications".
The Warehouse remains the only data store that allows data modification through GraphQL mutations. The GraphQL API provides read-only access to Lakehouse and mirrored databases. The data store characteristics match their intended use because Warehouses handle transactional structured data and Lakehouses serve analytical large-scale reads.
Here's a quick overview of Fabric data source support in the GraphQL API:
Best Practices for Robust GraphQL APIs in Fabric
To get the most out of your GraphQL APIs in Fabric, keep these best practices in mind:
- Optimize Queries: Only ask for the exact data you need. Avoid "over-fetching" to keep things fast.
- Batch Queries: Group multiple queries into one request to prevent API overload, especially with large datasets.
- Keep Queries Simple: Avoid overly complex or deeply nested queries, as they can slow things down and be tricky to debug.
- Strong Security: Implement authentication and authorization. The Fabric API for GraphQL uses Microsoft Entra (formerly Azure AD) and supports Service Principals (SPNs) for robust, automated security.
- Use Stored Procedures for Logic: While basic mutations are auto-generated, use stored procedures in your SQL database for complex business logic like validation or custom ID generation. These can then be exposed as GraphQL mutations.
- Monitor Performance: Fabric provides dashboards and detailed logging to help you visualize API activity, troubleshoot errors, and optimize performance.
- Leverage CI/CD: The API fully supports Fabric's CI/CD tools, including Git integration and deployment pipelines. This ensures proper version control, collaboration, and consistent deployments across environments.
These features mean the Fabric GraphQL API isn't just a data access tool; it's a full-fledged, production-ready solution. It helps you manage the entire API lifecycle, from development to monitoring, ensuring your data initiatives are reliable and scalable.
Practical Use Cases: Where the Microsoft Fabric API for GraphQL Shines
The Microsoft Fabric API for GraphQL opens up a world of possibilities:
- Efficient Web & Mobile Apps: Build highly responsive applications that fetch only the data they need, leading to faster load times and smoother user experiences.
- Real-time Dashboards: Power dynamic analytics applications and dashboards that need up-to-date insights. While direct Eventhouse querying isn't supported, mirroring Azure Cosmos DB data via GraphQL enables "robust real-time analytical applications" and live dashboards.
- Microservices & Backend-for-Frontend: Use GraphQL as a backbone for flexible microservices, allowing different services to communicate cleanly. It's also perfect for "Backend-for-Frontend" architectures, tailoring data access for various client needs.
- AI Agent Integration: Seamlessly expose your Fabric Lakehouses, Data Warehouses, and databases to AI agents through a standardized GraphQL interface. This makes it much easier to develop AI-driven insights and intelligent applications.
The Microsoft Fabric API for GraphQL is a critical piece in building an "Intelligent Data Fabric." It helps bridge the gap between your raw data and its smart use by advanced analytics or real-time systems, maximizing the value you get from your unified data platform.
Conclusion: The Future of Data Access in Microsoft Fabric
The Microsoft Fabric API for GraphQL is a significant leap forward in how organizations interact with their data. It brings GraphQL's powerful benefits—like unmatched efficiency, flexible querying, reliable data types, and a fantastic developer experience—seamlessly into the unified Microsoft Fabric platform.
This integration fundamentally simplifies and speeds up data access across all your Fabric data assets, from Lakehouses to Warehouses and mirrored databases. By hiding the complexities of backend data sources, the API empowers developers to focus on delivering real business value.
This is just the beginning. We can expect even broader support for Fabric items in the future, potentially including direct Eventhouse integration for real-time subscriptions. The continuous evolution of Microsoft Fabric and its APIs promises even more exciting possibilities.
Ultimately, the combination of unified data storage and a flexible, self-service API aligns perfectly with modern "Data Mesh" principles. It treats data as a product, making it easy for teams to share and consume data in a standardized, flexible way. The Microsoft Fabric API for GraphQL isn't just a technical feature, it's a powerful enabler for organizations to build the next generation of data-driven and AI-powered applications.
Contact