Artikel
Intelligentes Alert Clustering: Wie StackState Ihnen gegen Alert-Stürme hilft

Haben Sie schon einmal von dem englischen Sprichwort gehört: "Wenn es regnet, dann schüttet es", was bedeutet, dass wenn etwas Schlimmes passiert, es normalerweise nicht allein ist? Es ist ein altes Sprichwort, das in Büchern aus dem 17. Jahrhundert auftaucht, aber es gilt auch heute noch für die IT-Überwachung.
Wenn irgendwo in Ihrer IT-Landschaft ein Alarm ausgelöst wird, besteht die Wahrscheinlichkeit, dass viele weitere Alarme zu Komponenten ausgelöst werden, die mit dem ursprünglichen Alarm zusammenhängen. Der daraus resultierende "Alarmsturm" kann IT-Mitarbeiter überfordern, die wahre Ursache des Problems verschleiern und die Reaktionsfähigkeit des Teams lähmen.
Das AIOps-Produkt von StackState hilft Anwendern, dem Sturm zu trotzen, indem es zusammenhängende Warnmeldungen in einer einzigen Problemkarte zusammenfasst und die Ursache des Problems feststellt, so dass es schnell und effektiv behoben werden kann.
Die Topologie von StackState
StackState sammelt und kombiniert Daten von verschiedenen IT-Überwachungstools, um ein vollständiges Bild Ihrer IT-Landschaft zu erstellen. Da jedes Tool nur einen Teil des Puzzles sieht, fügt StackState diese Teile zusammen, um einen nahtlosen Überblick zu schaffen.
All diese Tools waren nie dafür gedacht, zusammen zu arbeiten, es ist, als ob sie eine andere Sprache sprechen würden.
Alle Informationen aus den Tools werden in eine gemeinsame Sprache übersetzt, bevor sie verarbeitet werden. Diese Sprache wird das 3T-Modell genannt und besteht aus Topologie, Telemetrie und Zeit. Die Topologie hilft uns, wenn wir mit einem Alarmsturm umgehen müssen.
Den Sturm zähmen
Die Topologie in StackState ist eine Darstellung Ihrer IT-Landschaft. Sie besteht aus Komponenten und deren Abhängigkeiten. Komponenten sind physische oder virtuelle Teile Ihrer IT-Umgebung - physische Server, virtuelle Server, Anwendungen, Datenbanken, Container, Router usw.
Die Komponenten sind voneinander abhängig und bestimmen, welche Komponenten benötigt werden, damit eine Komponente ihre Aufgabe erfüllen kann. In einer herkömmlichen 3-Schichten-Anwendung ist die Front-End-Komponente von der Anwendungskomponente abhängig, die wiederum von der Datenbank abhängig ist. Fällt die Datenbank aus, wirkt sich dies sowohl auf die Anwendungs- als auch auf die Front-End-Komponente aus.
Wenn Alarme auftreten, verwendet StackState die Topologie, um Ausfälle auf höheren Ebenen unter Ausfällen auf einer niedrigeren Ebene zu gruppieren.
Einsatz für die Arbeit
Nehmen wir an, Sie haben StackState zur Überwachung Ihrer IT-Landschaft eingerichtet. Hier sehen Sie ein Beispiel, wie das aussehen könnte:
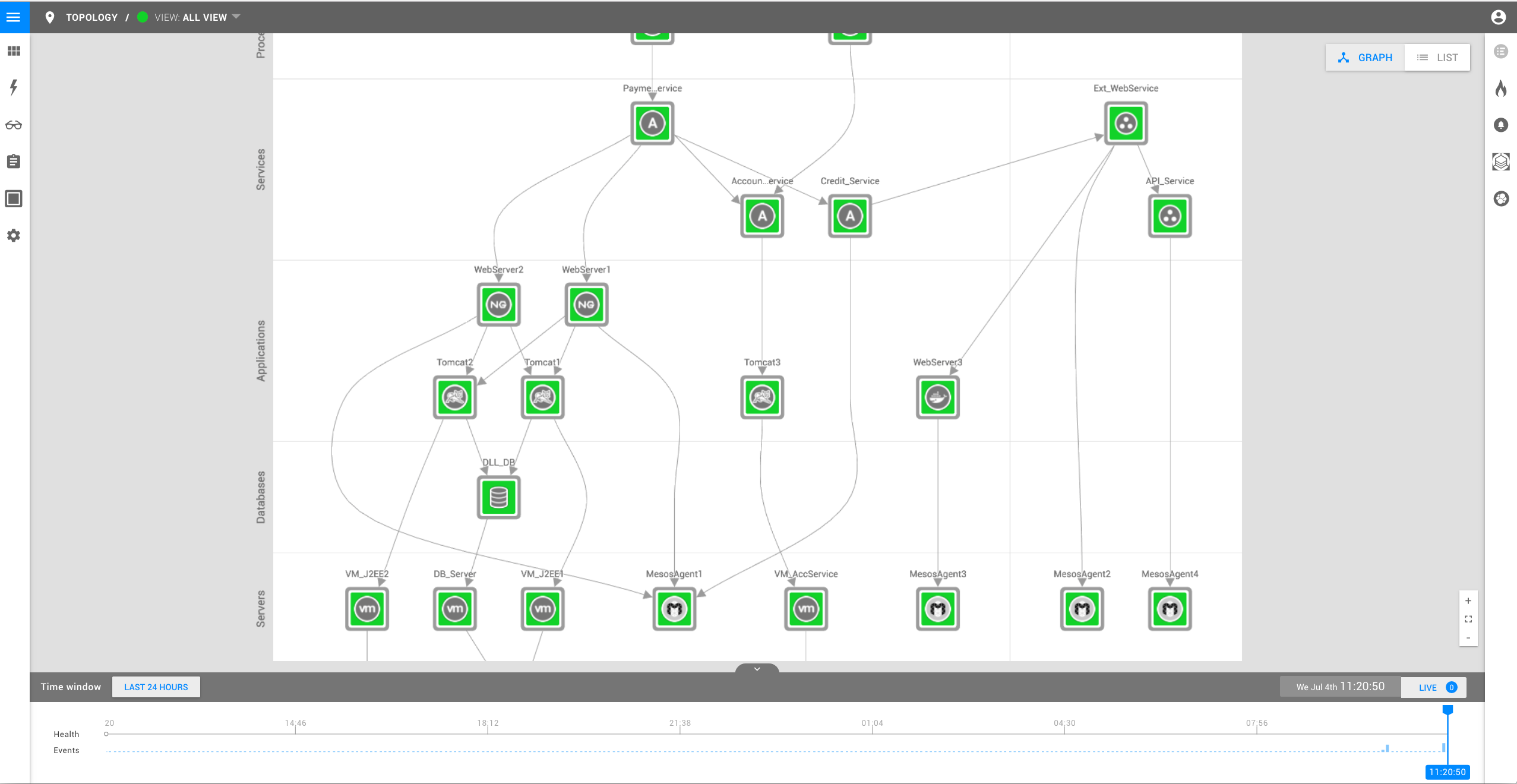
Die Abbildung zeigt eine Umgebung, die aus einem Zahlungsdienst (oben links) und den zugehörigen IT-Ressourcen besteht, die ihn funktionsfähig machen:
- zwei Webservices
- zwei Tomcat-Server
- und eine Datenbank zur Speicherung
Nehmen wir nun an, die Datenbank wird aufgrund eines Fehlers in Ihrer neuen Softwareversion langsamer. StackState erkennt dieses Problem und zeigt es im Problembereich an:
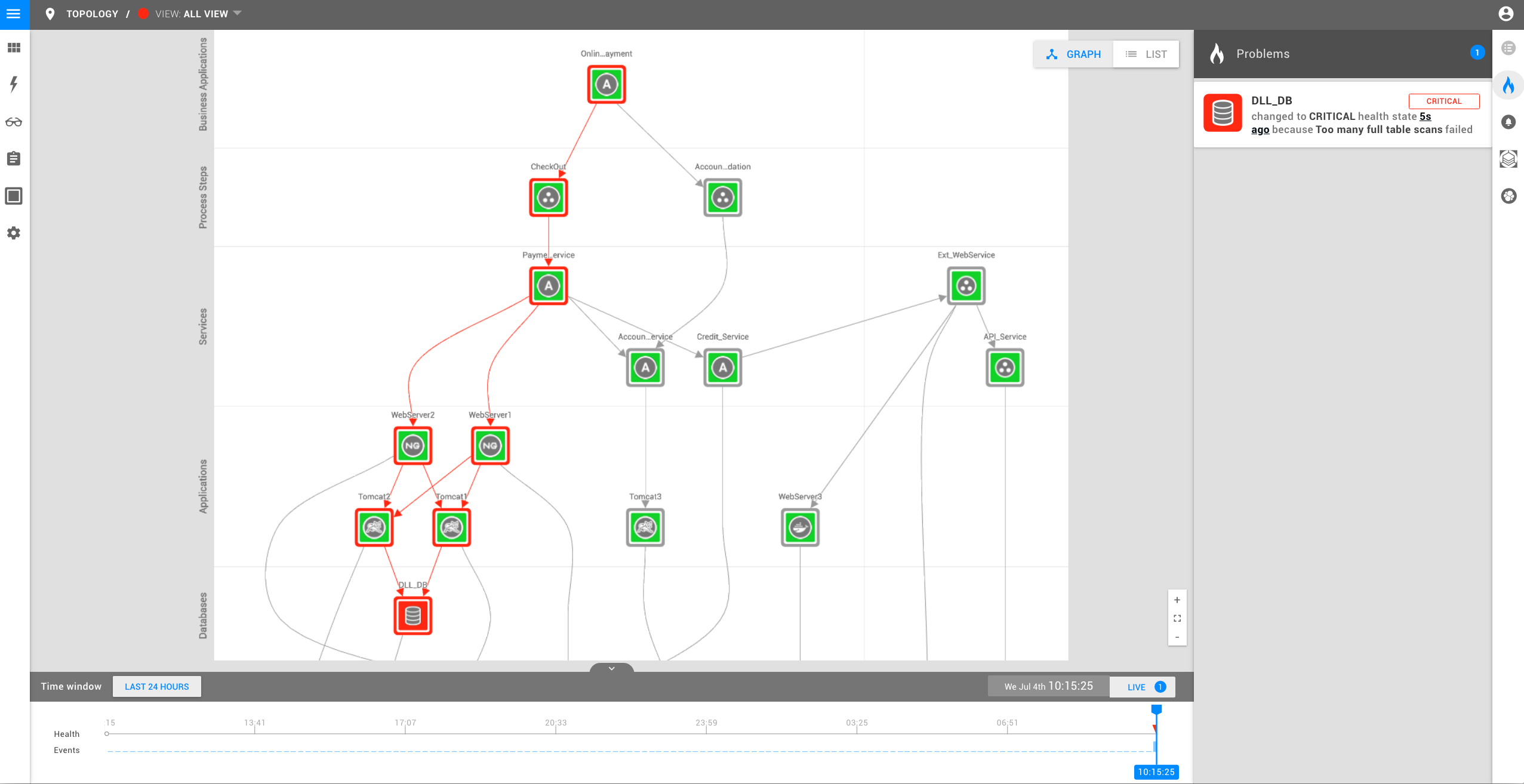
Die Problemkarte zeigt als Überschrift die Hauptursache 'DLL_DB' und erklärt, warum sich die Komponente in einem kritischen Zustand befindet. Über den Link im Text können Benutzer eine Zeitreise zu dem Zeitpunkt unternehmen, an dem die Prüfung fehlgeschlagen ist, um den genauen Zustand der gesamten Landschaft zu diesem Zeitpunkt zu sehen. Beachten Sie, dass StackState auch potenziell betroffene Komponenten in der Topologieansicht hervorhebt, indem es sie mit einem roten Rahmen umgibt.
Eine langsame Datenbank führt dazu, dass alle Abfragen, die in der Datenbank ausgeführt werden, länger dauern als gewöhnlich. Wenn der Zugriff auf die Datenbank über eine Webanwendung erfolgt, dauern auch die Anfragen an diesen Dienst länger. In unserem Beispiel lösen die Tomcat-Server, die auf die Datenbank zugreifen, ebenfalls einen Alarm aus.
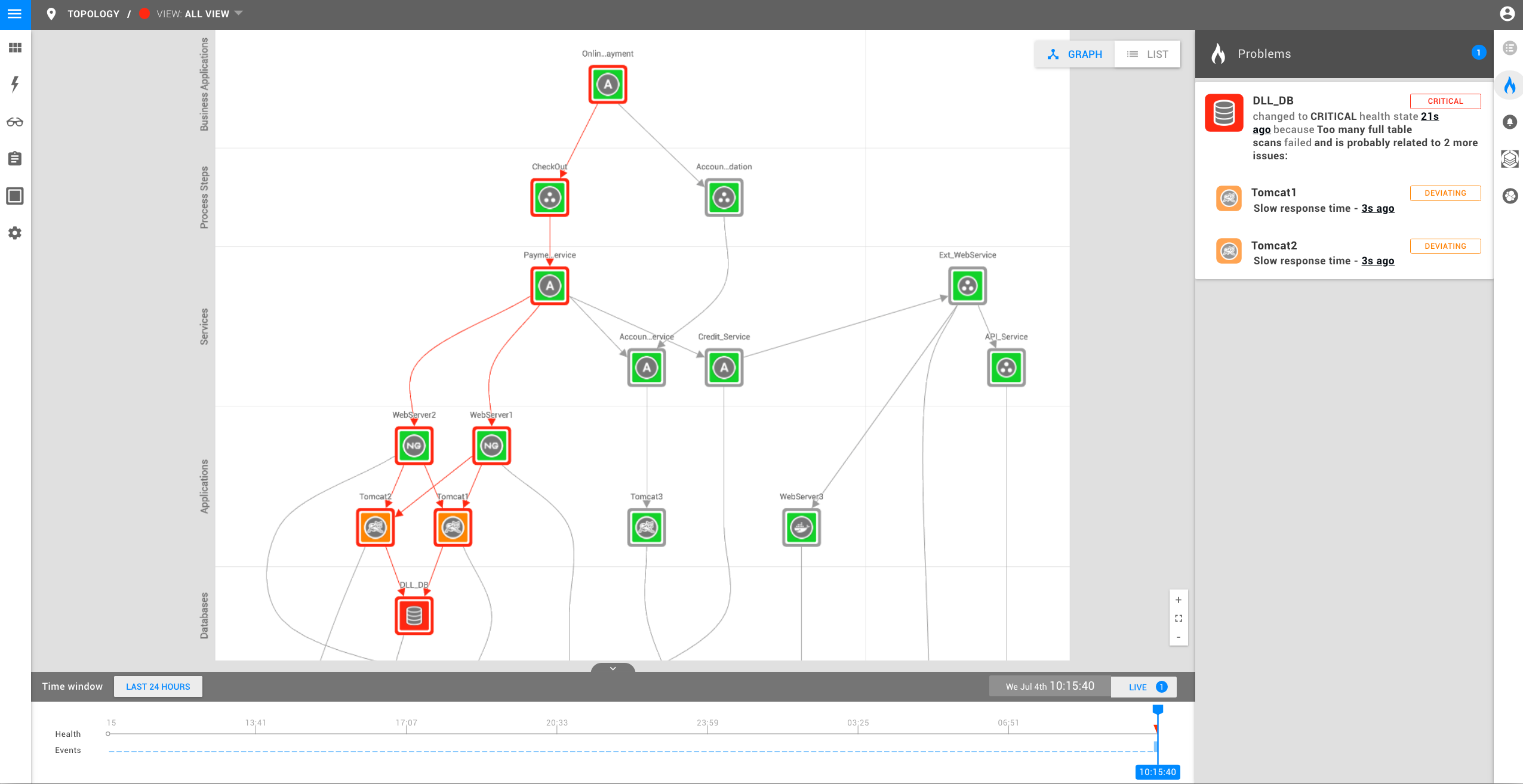
Da StackState die Abhängigkeiten in Ihrer Systemlandschaft kennt, werden die Tomcat-Server-Warnungen nicht als eigenständige Probleme angezeigt, sondern werden der Problemkarte hinzugefügt, die das Datenbankproblem anzeigt. Als IT-Mitarbeiter wissen Sie jetzt, dass Sie die Probleme mit dem Tomcat-Server nicht untersuchen müssen (da sie wahrscheinlich ein Symptom eines größeren Problems sind) und sich stattdessen auf das Datenbankproblem konzentrieren können.
Schließlich löst der Zahlungsdienst selbst einen Alarm aus, weil er aufgrund der Langsamkeit der Tomcat-Server und des Datenbankservers sein SLA nicht einhalten kann.
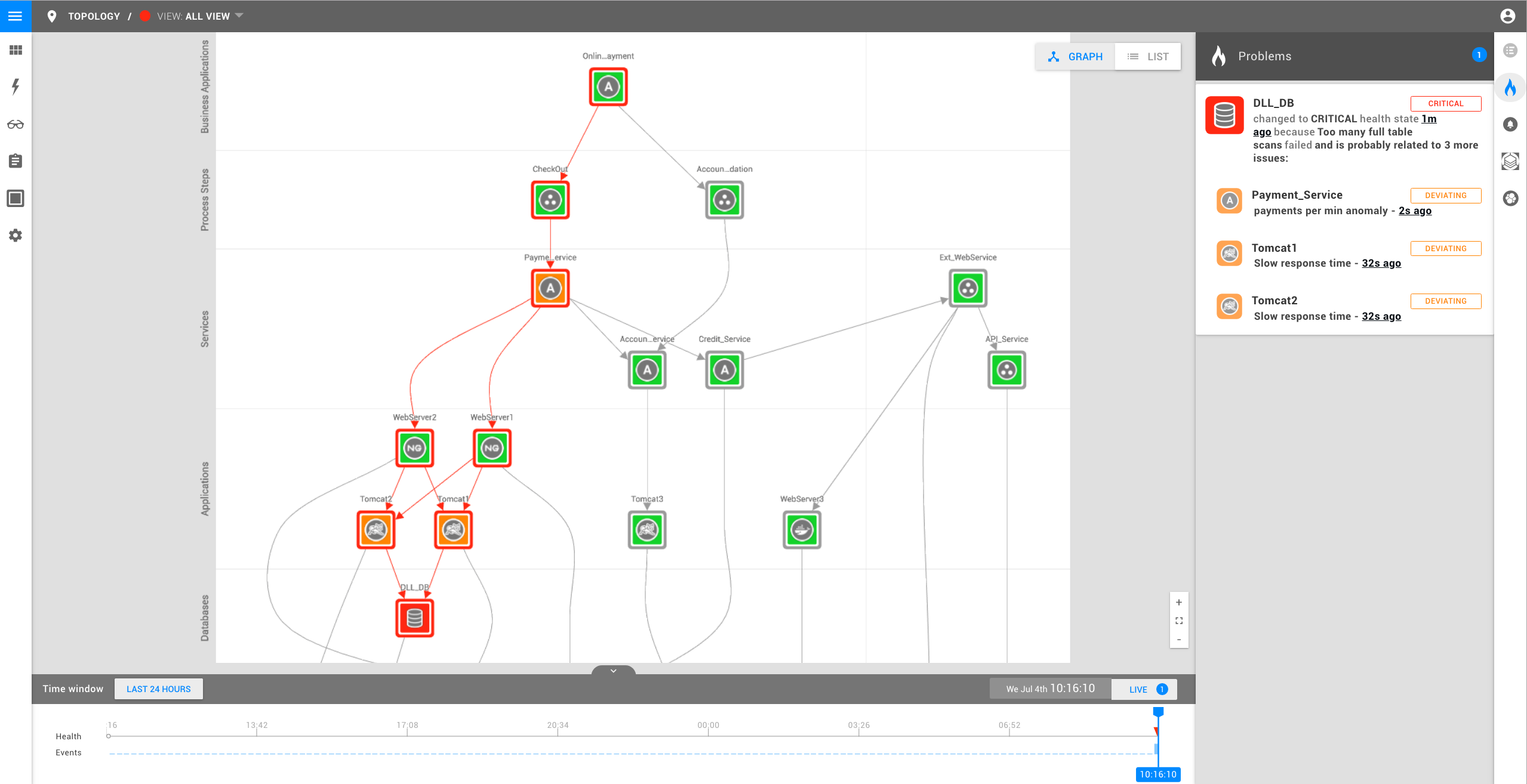
Auch hier wird das Problem mit den Zahlungsdiensten auf der Grundlage der Topologie unter der Datenbankursache gruppiert. Die Techniker wissen, welche der Probleme sie angehen müssen und welche sie vorerst ignorieren können.
Gemeinsames Verstehen
Der Problembereich von StackState ist sogar noch leistungsfähiger, wenn er von verschiedenen Teams gemeinsam genutzt wird. Stellen Sie sich vor, dass der Zahlungsdienst von verschiedenen Datenbank-, Entwicklungs- und Geschäftsteams verwaltet wird. Ohne ein gemeinsames Dashboard würde jedes Team seinen Teil der Welt (die Datenbank, die Anwendung oder den Geschäftsdienst) betrachten und auf der Grundlage der oben beschriebenen Warnmeldungen zu dem Schluss kommen, dass es in seinem Teil der Anwendung ein Problem gibt.
Wenn Sie StackState als gemeinsames Dashboard verwenden, wissen die Entwicklungs- und Geschäftsteams, dass die Ursache für die Warnmeldungen ein Datenbankproblem ist, und müssen nur noch die Lösung des Problems überwachen, anstatt in den Feuerwehreinsatz zu gehen. Dies spart unzählige Unterbrechungen und Aufwand, wenn es auf Unternehmensebene angewendet wird.
Möchten Sie mehr über AIOps erfahren?
Laden Sie unseren kostenlosen 'Leitfaden für AIOps' herunter und machen Sie den ersten Schritt in Richtung AIOps. Holen Sie sich Ihr Exemplar und Sie werden lernen:
- Das Wesentliche und die Vorteile von AIOps
- Die verschiedenen Datenquellen und Tools, die analysiert werden können
- Moderne AIOps-Funktionen und Anforderungen, auf die Sie achten sollten
- Wie Sie IT Operations & DevOps dabei unterstützen, effiziente und qualitativ hochwertige Dienste zu liefern - ohne blinde Flecken
Laden Sie den Leitfaden gleich hier herunter.
Unsere Ideen
Weitere Artikel

Xebia schließt Partnerschaft mit PlatformEngineering.org
Xebia arbeitet mit PlatformEngineering.org zusammen, um praktisches, von der Community betriebenes Plattform-Engineering voranzutreiben, wobei der...
Adnan Alshar



Contact